
학부연구생으로 소속된 연구실에서는 그간 이미지 기반의 딥러닝 모델에 대해서만 연구를 진행했었다. 딥러닝을 공부하면서, 알고 있는 지식이 한 분야에만 한정되어있다는 생각이 들어 NLP(자연어 처리)와 연관된 텍스트에 대해서도 공부해야 할 필요성을 느껴 Tensorflow 튜토리얼을 기반으로 공부해보았다.
Word Embeddings
임베딩이란, 자연어를 컴퓨터가 이해할 수 있는 언어(숫자) 형태인 벡터로 변환환 결과 혹은 일련의 과정을 의미한다. 임베딩의 역할은 단어 및 문장간의 관련성을 계산하는 것, 그리고 의미적 또는 문법적 정보를 함축하는 것이다.
One-hot encodings
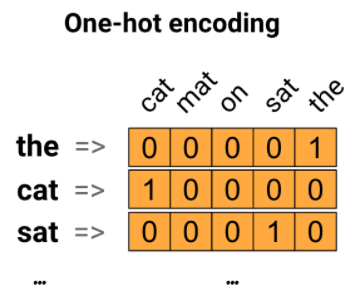
텍스트를 숫자로 표현하기 위한 방법으로는 세 가지가 있는데, 첫 번째는 원 핫 인코딩이다. 각 단어를 원 핫 인코딩하는데, 각각의 단어를 나타내기 위해 길이가 vocabulary와 동일한 0벡터를 만들고 1을 위의 그림과 같이 배치한다. 이런식으로 대부분의 값이 0으로 채워져 있는 경우를 가지고 희소 벡터라고 한다. 직관적으로 이해하기 쉽지만 유의어, 반의어와 같은 단어끼리의 관계성이 없이 서로 독립적인 관계(벡터 내적하면 0값 가져 직교 이루므로)라는 점과 비효율적인 점(차원의 저주)이 단점으로 지적된다.
Encode each word with a unique number

희소 벡터가 갖는 단점을 보완하고자 제안된 방법이다. 고유 번호를 사용해 각 단어를 인코딩하는 방법이다. 이런 벡터는 밀집 벡터라고 부른다. 차원의 저주라 불리는 비효율성은 해결되었지만 마찬가지로 단어 간의 관계를 파악할 수 없다는 단점 존재한다. 즉, 유사성이 없기 때문에 함수의 가중치 조합이 의미가 없어서 모델을 해석하기 어려울 수 있다.
Word embeddings
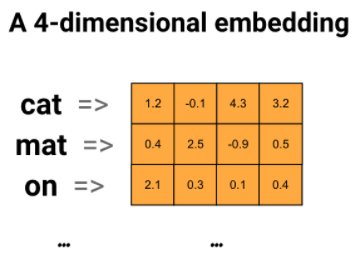
워드 임베딩은 마찬가지로 단어를 밀집 벡터의 형태로 표현한다. 유사한 단어일 경우 유사한 인코딩을가지는 효율적인 방법을 제공한다. 임베딩은 소수점 값으로 이루어져 있고 이는 학습 가능한 매개변수이다. 8차원에서 최대 1024차원까지 벡터 표기할 수 있다. 위그림의 예시는 4차원 벡터로 이루어진 워드 임베딩에 대한 다이어그램에 해당한다. 이러한 가중치를 학습한 후 테이블에서 해당 벡터를 조회해 각 단어를 인코딩한다.
정리하여, 워드 임베딩이란 분산 표현을 이용해 단어의 의미를 다차원 공간에 벡터화하는 방법이다. 여기서 분산 표현이란, 비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다는 가정 하에 만들어진 표현 방법을 의미한다.
Tutorial Code
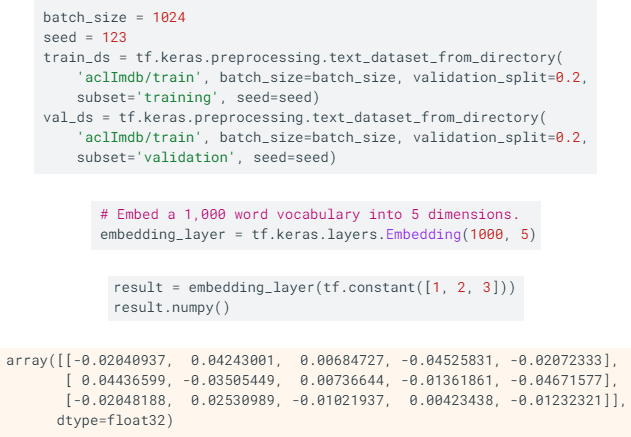
위의 코드는 TensorFlow Tutorial에서 제공하는 예제 코드 중 주요 부분만 가져온 것이다. 여기서는 Large Movie Review Dataset을 사용하였다. train 디렉터리에서 train과 validation 데이터셋을 8:2로 분할하면 20000장은 train, 5000장은 validation을 위해 쓰인다. 라벨링의 경우 1은 positive로 긍정적인 리뷰, 0은 negative이다.
다음은 embedding layer를 이용한 코드에 해당한다. 임베딩 레이어 생성하면 임베딩에 대한 가중치 무작위로 초기화한다. 이는 backpropagation을 통해 조정된다. 일단 훈련되면 학습된 워드 임베딩은 단어 간의 유사성이 대략적으로 인코딩된다.
세 번째 코드와 같이 임베딩 레이어에 정수를 전달하면 result 변수는 각 정수를 임베딩 테이블의 벡터로 대체한다.

텍스트 전처리를 통해 영화 리뷰를 벡터화하는 과정이다. 전처리 과정은 크게 3가지로 나뉘는데, 띄어쓰기를 기준으로 토큰화를 수행한 다음에 토큰들을 문자 인코딩을 시키고, 길이를 지정한 만큼 맞춰준 후 이 값을 모델에 넣게 된다. 그러면 모델의 임베딩 레이어를 거쳐 학습을 진행한다.
가장 중요한 내용은 TextVectorization 레이어이다. 이를 초기화해서 리뷰를 벡터화하기 때문이다. custom_standardization 함수에서는 알파벳을 소문자로 바꾸고, html을 제거하는 간단한 작업을 수행한다. 이를 standardize 변수에 넣어준다. 이렇게 모델 자체에 text vectorization이 있어 따로 전처리를 할 필요도 없고 모델을 저장하면 예측할 때 어떤 데이터가 오든 모델을 학습시켰던 데이터에 기반한 vocabulary를 따로 불러오지 않고도 예측할 수 있다.
마지막 부분은 데이터셋이 text와 label이 모두 포함되어있는데 학습을 시키는 데에는 text만 필요하므로 label을 제거하고 이걸 vectorize_layer에서 실행시킨다. adapt를 하면 하나의 단어 사전이 만들어진다고 생각하면 쉽다. 문장에서 등장하는 빈도가 높은 단어들이 우선적으로 출력되고 뒤로 갈수록 잘 쓰이지 않는 단어들이 나온다.
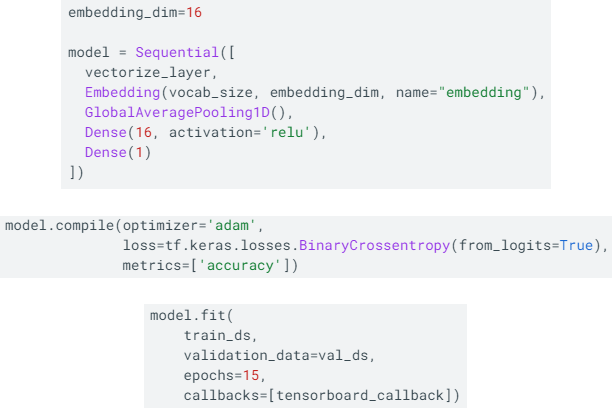
텍스트가 문자 인코딩되어 나온 값을 embedding 레이어에 넣는다. 이후 나머지 레이어를 통과시켜 학습을 시킨다. CoLab에서 돌려봤을 때 val 정확도는 0.7940, val loss는 0.4082가 나왔다.
Word2Vec

텍스트로부터 워드 임베딩을 학습하기 위해 만들어진 예측 모델인 word2vec 개념 설명에 앞서 word2vec이 어떤 일을 하는지에 대해 감이 잡힐 수 있는 예시이다. 더하기, 빼기 연산으로 단어가 갖고 있는 어떤 의미들을 가지고 연산한다. 이는 각 단어 벡터가 단어 간 유사도를 반영한 값을 갖고 있기 때문에 가능한 것이다.
word2vec은 단일 알고리즘이 아니라 대규모 데이터셋에서 워드 임베딩을 학습하는 데 사용할 수 있는 모델 아키텍처 및 최적화 통합본이다. 위 개념을 제안한 논문에서는 단어 표현을 학습하는 두 가지 방법을 제안한다. 첫 번째 방법은 Continuous Bag-of-Words Model로, 주변의 단어를 고려해 중간 단어를 예측한다. 컨텍스트는 중간 단어 앞뒤의 몇 개의 단어로 구성되고, 단어 순서가 중요하지는 않다. 두 번째 방법은 Continuous Skip-gram Model로, 현재 단어 후 일정 범위 내에서 단어를 예측한다.
Continuous Bag-of-Words
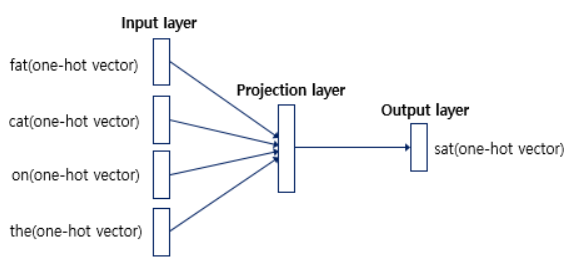
CBOW의 인공 신경망을 간단히 도식화한 것이다. 입력층의 입력으로서 앞, 뒤로 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들의 원-핫 벡터가 들어가게 되고, 출력층에서 예측하고자 하는 중간 단어의 원-핫 벡터가 필요하다. Word2Vec의 학습을 위해서 이 중간 단어의 원-핫벡터가 필요한 것이다.
Word2Vec은 딥러닝 모델은 아니다. 은닉층(hidden Layer)이 1개이기 때문에 얕은 신경망(Shallow Neural Network)이라고 부른다. 또한 Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않으며 룩업테이블이라는 연산을 담당하는 층으로 일반적인 은닉층과 구분하기 위해 투사층(projection layer)이라고 부르기도 한다.
Continuous Skip-gram
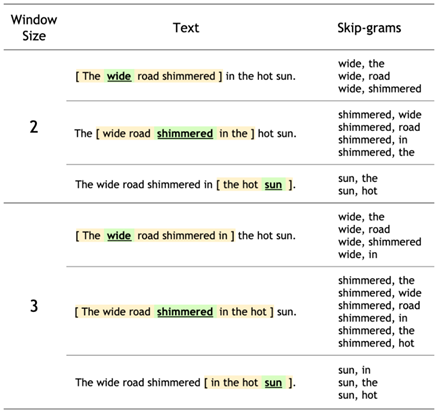
skip-gram은 단어 자체가 주어지면 단어의 컨텍스트를 예측한다. 그래서 skip-gram 모델의 학습 목표는 대상 단어가 주어진 컨텍스트 단어를 예측할 확률을 최대화하는 것이다.
Negative Sampling
Word2Vec가 학습 속도에서 강점을 가지는 것은 추가적으로 사용되는 기법이 존재하기 때문이다. Word2Vec 출력층에서는 소프트맥스 함수를 지난 워드셋 크기의 벡터와 실제값인 원-핫벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에 대한 임베딩 벡터 값을 업데이트하는데, 이는 굉장히 무거운 작업이다.
그래서 사용하는 기법이 Negative Sampling이다. 이는 Word2Vec이 학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법이다. 윈도우 사이즈 내에 존재하지 않는 단어(negative)에 대해 일부만 선택해 소프트맥스를 계산한다. 차이가 있다면 기존 skip-gram은 입력이 중심단어, 모델의 예측은 주변 단어인 구조인데 네거티브 샘플링을 사용하는 스킵그램(SGNS)은 중심 단어와 주변 단어가 모두 입력이다. 그리고 이 두 단어가 실제로 윈도우 크기 내에 존재하는 이웃 관계인지 그 확률을 예측한다.
아래의 그림은 훈련 예제를 생성하는 절차를 요약한 그림이다.


Text Classification with an RNN
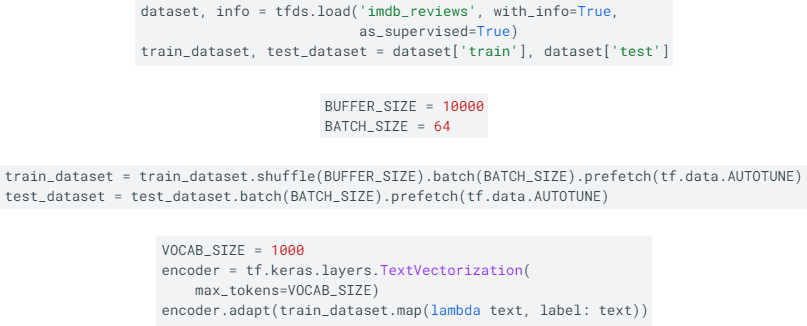
tfdf를 사용해 데이터셋을 다운받고 입력 파이프라인 설정한다. 이후 훈련 데이터들을 셔플하고 (text, label)에 대한 배치를 만든다. 앞서 설명한 TextVectorization 레이어를 사용해 모델에서 사용될 데이터들을 전처리하고 adapt 함수로 레이어의 vocabulary를 설정한다. np로 출력해보면 패딩, unknown token 다음 빈도순으로 토큰 출력된다. 이 과정까지 진행하면 텍스트 인코더까지 만든 것이다.

모델의 구조에 대한 그림과 코드이다. 첫 번째 층은 인코더이다. 앞서 TextVectorization으로 text를 token으로 나눈 것에 해당한다. 다음으로 있는 임베딩 레이어는 단어당 하나의 벡터를 저장한다. 호출되면 단어 인덱스 시퀀스를 벡터 시퀀스로 변환한다. 이러한 벡터는 훈련이 가능해서 훈련 후에는 유사한 의미를 가지는 단어는 종종 유사한 벡터를 갖기도 한다.
RNN이기 때문에 요소를 반복하여 시퀀스 입력을 처리한다. 그림에서 볼 수 있듯 RNN은 한 타임스텝의 출력을 다음 타임스텝의 입력으로 전달한다. 코드상에서는 Bidirectional로 구현해 입력을 앞뒤로 전파하고 최종 출력을 연결한다. 이러한 양방향 RNN의 장점은 입력 시작 부분의 신호가 출력에 영향을 미치기 위해 모든 타임스텝을 통해 처리될 필요가 없다는 점이다. 다만, 단어가 끝에 추가될 때는 예측을 효율적으로 스트리밍 할 수 없다는 단점도 존재한다.
해당 모델 컴파일하고 훈련시켰을 때 CoLab에서 Test loss는 0.3184, Test accuracy는 0.8581이 나왔다.
BERT
BERT는 Bidirectional Encoder Representations from Transformers의 약자로, 구글이 공개한 NLP 사전 훈련 모델이다. 이는 사전 훈련된 Embedding을 통해 성능을 더 좋게 할 수 있는 언어 모델이다. BERT 모델은 일반적으로 대량의 텍스트에 대해 사전 학습된 다음 특정 작업에 맞게 미세 조정된다. BERT 언어 모델 출력에 추가적으로 RNN 같은 모델을 쌓아 원하는 Task를 수행하는 것이다. BERT 모델은 여러 종류가 있어서 로드할때 선택할 수 있다.
Input
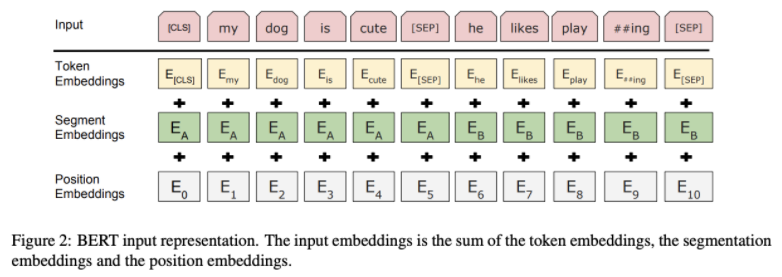
BERT는 Token Embedding + Segment Embedding + Position Embedding 이렇게 세 가지 임베딩을 합치고 이에 Layer 정규화와 Dropout을 적용해 Input으로 사용한다.
Token Embedding은 Word Piece 임베딩 방식 사용한다. 각 Char(문자) 단위로 임베딩하고, 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다. 자주 등장하지 않는 단어는 다시 sub-word로 만든다. 이는 이전에 자주 등장하지 않았던 단어를 모조리 'OOV(Out of Vocabulary)'처리하여 모델링의 성능을 저하했던 'OOV'문제도 해결할 수 있다.
Segment Embedding은 Sentence Embedding이라고도 정의할 수 있으며, 토큰 시킨 단어들을 다시 하나의 문장으로 만드는 작업이다. BERT에서는 두 개의 문장을 구분자 [SEP]를 넣어 구분하고 그 두 문장을 하나의 Segment로 지정하여 입력한다. BERT에서는 이 한 세그먼트를 512 sub-word 길이로 제한하는데, 한국어는 보통 20 sub-word가 한 문장을 이룬다고 하며 대부분의 문장은 60 sub-word가 넘지 않는다고 하니 BERT를 사용할 때, 하나의 세그먼트에 128로 제한하여도 충분히 학습이 가능하다고 한다.)
마지막으로 Position Embedding은 Token 순대로 인코딩하는 것을 뜻한다.
Pre-Training
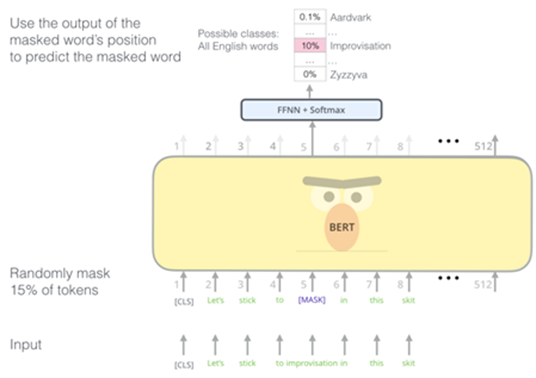
데이터들을 임베딩하여 훈련시킬 데이터를 모두 인코딩하였으면 사전훈련을 시킨다. 기존의 방법들은 보통 문장을 왼쪽에서 오른쪽으로 학습하여 다음 단어를 예측하는 방식이거나, 예측할 단어의 좌우 문맥을 고려하여 예측하는 방식을 사용한다. 하지만 BERT는 언어의 특성을 잘 학습하도록 MLM(Masked Language Model), NSP(Next Sentence Prediction) 두 가지 방식을 사용한다. 위 그림은 MLM에 해당하며, 입력 문장에서 임의로 토큰을 버리고(Mask) 그 토큰을 맞추는 방식으로 학습을 진행한다.
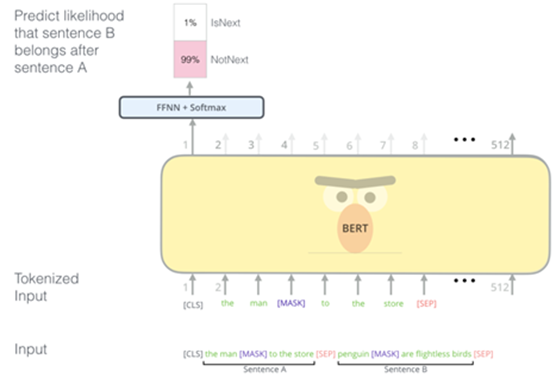
위 그림은 NSP이다. 두 문장이 주어졌을 때, 두 문장의 순서를 예측하는 방식이다. 두 문장 간 연관성이 고려되어야 하는 NLI와 QA의 파인 튜닝을 위해 두 문장의 연관성을 맞추는 학습을 진행한다.
Transfer Learning
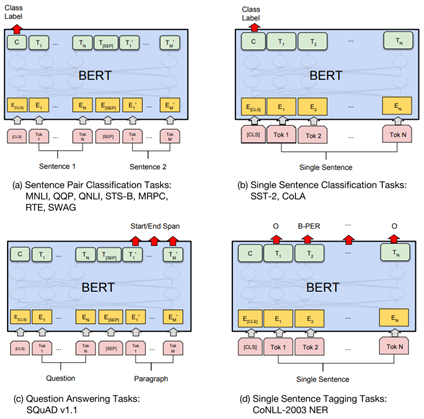
학습된 언어 모델을 전이학습시켜 실제 NLP Task를 수행하는 과정이다. 사전에 학습된 BERT에 풀고자 하는 태스크의 데이터를 추가로 학습시켜 테스트하는 단계인 파인 튜닝 단계라고 보면 되는데, 4가지로 구분할 수 있다. 기존에 언어 모델을 만드는 부분은 스스로 라벨링을 하는 준지도학습이었지만, 전이학습 부분은 라벨이 주어지는 지도학습 부분이다.
Sentence Pair Classification Tasks
문장 쌍에 대한 분류 또는 회귀 문제에서 쓰이며, 자연어 추론이 대표적인 태스크이다. 이는 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류하는 것을 의미한다. 모순 관계, 함의 관계, 중립 관계가 있다. 텍스트의 쌍을 입력받는 이러한 태스크의 경우에는 입력 텍스트가 1개가 아니므로, 텍스트 사이에 [SEP] 토큰을 집어넣고, Sentence 0 임베딩과 Sentence 1 임베딩이라는 두 종류의 세그먼트 임베딩을 모두 사용하여 문서를 구분한다.
Single Sentence Classification Tasks
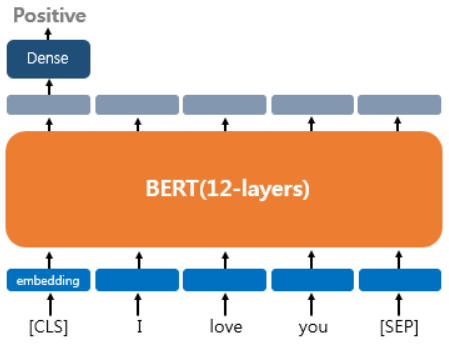
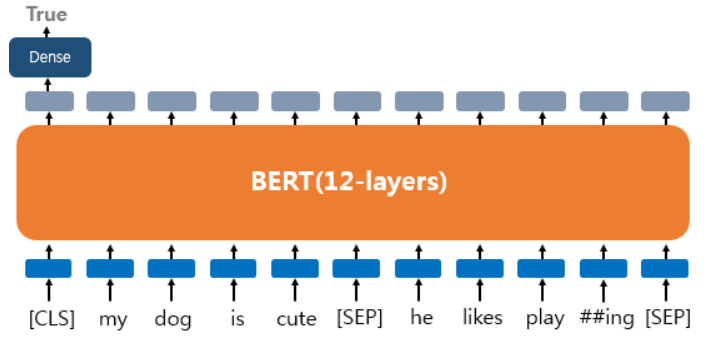
하나의 문서에 대한 텍스트 분류 유형이다. 영화 리뷰 감성 분류같이 입력된 문서에 대해서 분류를 하는 유형으로 문서의 시작에 [CLS]라는 토큰을 입력한다. [CLS] 토큰은 BERT가 분류 문제를 풀기 위한 특별 토큰이다. 텍스트 분류 문제를 풀기 위해서 [CLS] 토큰의 위치의 출력층에서 밀집층(Dense layer) 또는 완전 연결층(fully-connected layer)이라고 불리는 층들을 추가하여 분류에 대한 예측하게 된다.
Single Sentence Tagging Tasks
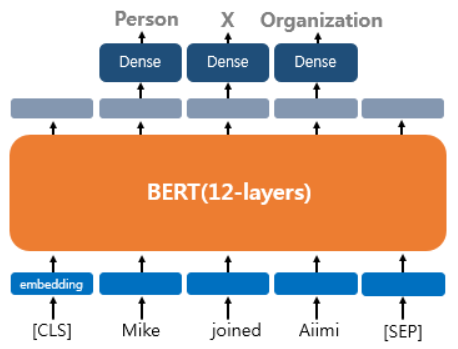
태깅작업이다. 대표적으로 문장의 각 단어에 품사를 태깅하는 품사 태깅작업과 개체를 태깅하는 개체명 인식 작업이 있다. 출력층에서는 입력 텍스트의 각 토큰의 위치에 밀집층을 사용하여 분류에 대한 예측을 하게 된다.
Question Answering Task
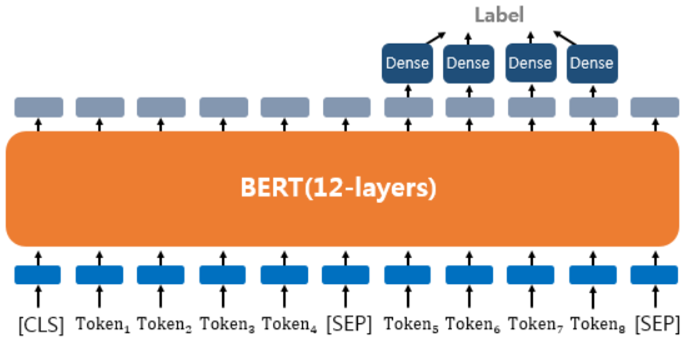
텍스트의 쌍을 입력으로 받는 또 다른 태스크이다. 질문과 본문이라는 두 개의 텍스트의 쌍을 입력한다. 질문과 본문을 입력받으면, 본문의 일부분을 추출해서 질문에 답변을 한다.
