
Data Augmentation
- Dataset이 부족해서 overfitting이 발생하는 문제
- 가진 데이터로 가상의 다양한 데이터를 만들어서 해결
- Is it plausible? 데이터셋에 추가해도 성능향상이 일어날까.
Techniques
Shift and crop|Flip|Rotation|Color Jitter
|Adding noise - Data augmentation doesn't solve everything.
Weight Initialization
Effect of Initial Weights
- Local minima에 빠질 수 있다.
- Converge(수렴)이 느려질 수 있다. Loss가 느리게 감소.
- Achieved generalization can be poor.
파라미터 설정 방법 세 가지
LeCun initialization
- LeCun Normal Initialization: 정규분포를 따른다.
- LeCun Uniform Initialization: 균등분포를 따른다.
- 처음에는 파라미터들을 랜덤하게 초기화하고, 이후 N_in(이전 layer의 파라미터 개수)을 사용하여 초기화하자.
Xavier initialization
- 이것도 normal / uniform 두 가지 있음
- N_in과 N_out(다음 layer의 파라미터 개수) 모두 사용해서 초기화하자.
He initialization
- ReLU activation function을 사용할 때 효과적
- 다시 N_out을 없애고,
LeCun에 2를 곱해준 형태 - In most recent models,
Heinitialization is mainly selected.
Scratch Learning
- 초기 정보 없이 시작
- Beginning with no knowledge of the subject at hand.
- Beginning trainiing from initialization.
Transfer Learning & Fine Tunning
- 초기 정보 있음
- Scratch Learning과의 차이: Parameter Initialization만 다르다.
- Pre-trained model. 내가 풀고자 하는 문제와 비슷 & 사이즈가 큰 데이터로 학습된 모델을 활용해서 나의 모델을 학습시킨다. ->
Fine Tunning은 이 학습 과정 - Large dataset으로 학습시키면, low level은 비슷. high level만 달라짐
- 그렇다면, layer의 뒷 부분만 fine tunning 하면 된다.
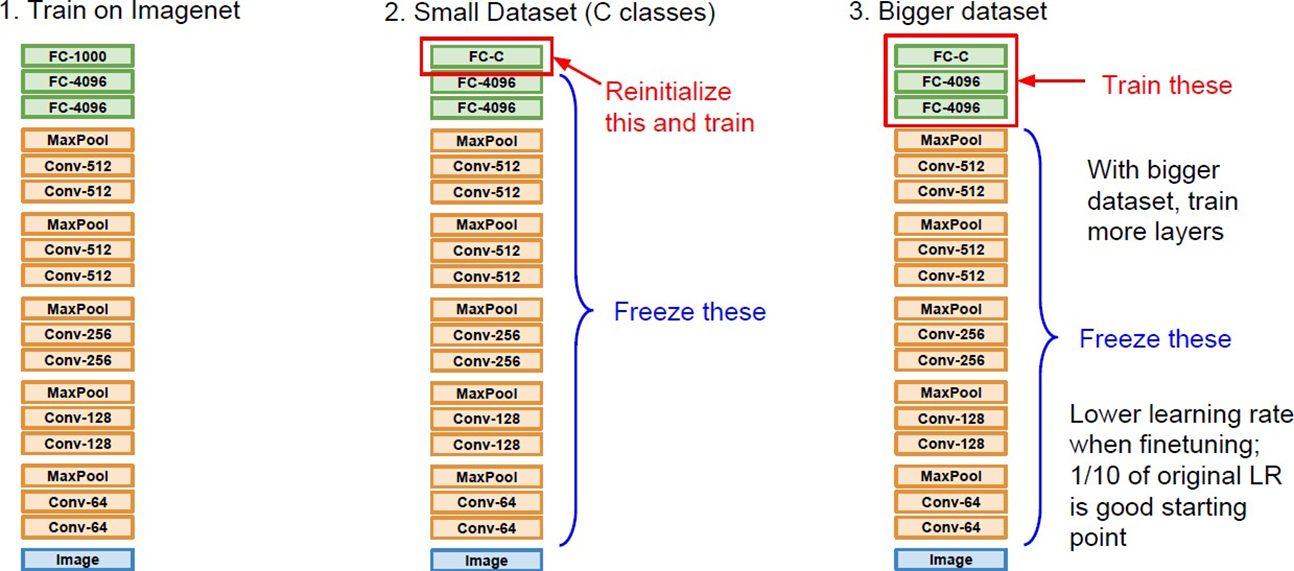
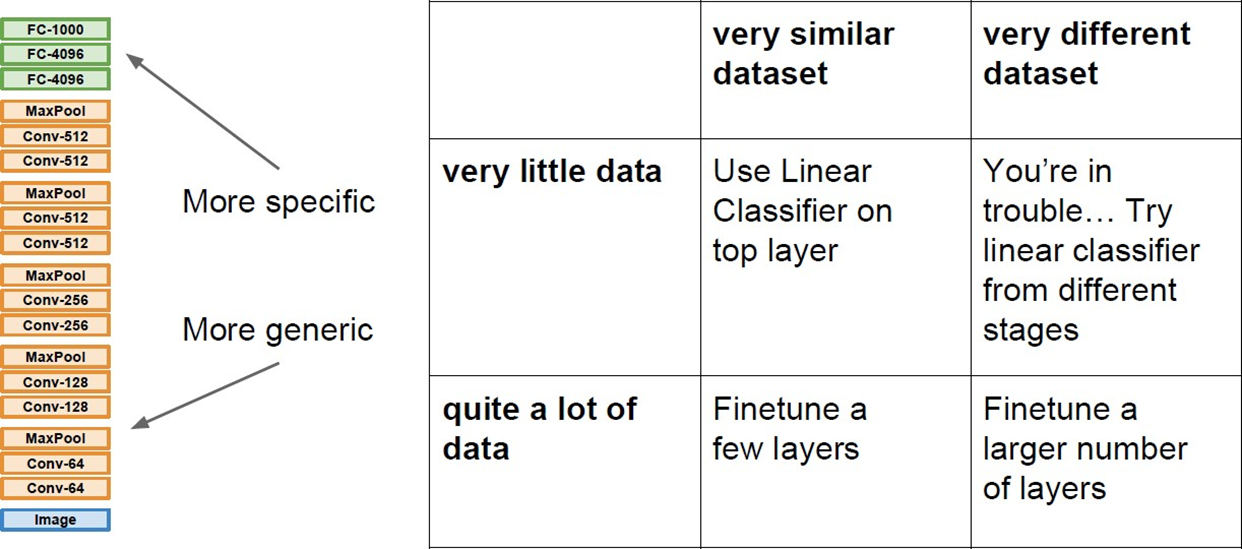
- Dataset 사이즈와 유사도에 의해 학습 범위가 결정된다.

Übermensch