
📚 오늘 공부한 내용
1. Redshift 권한
- 일반적으로 사용자별로 테이블에 권한 설정을 하는 것은 사용자가 많아질수록 복잡해지고, 불필요한 정보에 대해 접근이 가능해져서 정보 누출이 생길 수도 있고, 꼭 필요한 테이블에 접근이 불가한 경우가 생길 수도 있어 사용하지 않는다.
- 역할(Role) 혹은 그룹(Group)별로 스키마에 접근 권한을 주는 것이 일반적이다.
- 그룹은 계승 구조가 지원이 안 되기 때문에 요즈음은
RBAC(Role Based Access Control)이 새로운 트렌드이다. - 개인 정보과 관련된 테이블이라면 별도 스키마를 설정하며 극히 소수의 사람만 속한
역할(role)에 접근 권한을 준다.
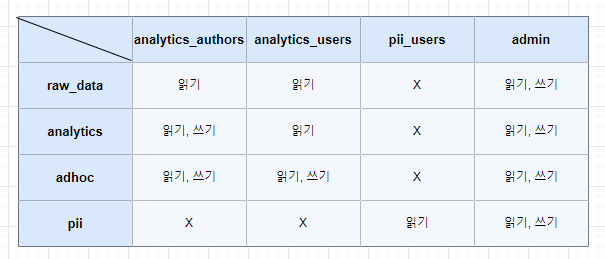
- 다음과 같이 권한을 설정해 주자.
- 각각
raw_data,analytics,adhoc,pii가 스키마이고,analytics_author,analytics_users,pii_users,admin이 역할(role)이 된다. - 권한 부여는
GRANT를 통해 줄 수 있다.
1) analytics_author에 권한 부여
- 권한을 부여해 줄 때 테이블에 대한 모든 권한을 부여해 주려면
GRANT ALL ON SCHEMA를 통해 스키마의 권한을 먼저 부여해 주어야 한다. - 또한 테이블의 조회 권한을 부여해 주려면
GRANT USAGE ON SCHEMA를 해 주어야 한다.
-- analytics 스키마의 모든 권한을 준다.
GRANT ALL ON SCHEMA analytics TO GROUP analytics_authors;
-- 스키마 자체의 권한이 먼저 지정이 되어야 테이블에 대한 모든 권한을 줄 수 있다.
GRANT ALL ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_authors;
GRANT ALL ON SCHEMA adhoc to GROUP analytics_authors;
GRANT ALL ON ALL TABLES IN SCHEMA adhoc TO GROUP analytics_authors;
-- GRANT USAGE 명령이 실행되어야 테이블 조회 권한을 줄 수 있다.
GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_authors;
-- raw_data 스키마에는 모든 테이블에 대해 SELECT 권한을 준다.
GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_authors;2) analytics_users
GRANT USAGE ON SCHEMA analytics TO GROUP analytics_users;
GRANT SELECT ON ALL TABLES IN SCHEMA analytics TO GROUP analytics_users;
GRANT ALL ON ALL TABLES IN SCHEMA adhoc TO GROUP analytics_users;
GRANT ALL ON SCHEMA adhoc to GROUP analytics_users;
GRANT USAGE ON SCHEMA raw_data TO GROUP analytics_users;
GRANT SELECT ON ALL TABLES IN SCHEMA raw_data TO GROUP analytics_users;3) pii_users
- 어떻게 권한을 줄 건지에 따라 다른데 해당 역할(role)에는
PII접근 권한만 허용해 주고, 다른 스키마에 접근해야 하는 경우 목적에 맞게 사용자에게 추가적으로 다른 역할을 부여해 줄 수도 있고,PII_USERS라는 역할 안에 이 모든 권한을 부여해 줄 수도 있다.
GRANT USAGE ON SCHEMA pii TO GROUP pii_users;
GRANT SELECT ON ALL TABLES IN SCHEMA pii TO GROUP pii_users;💻 [AWS RedShift] 7. 그룹(GROUP) 권한 부여 - 실습 포스팅
2. Redshift 보안
1) 컬럼 레벨 보안 (Cloumn Level Security)
- 테이블 내의 특정 컬럼을 특정 사용자나 특정 그룹, 역할에만 접근 가능하게 하는 것이다.
- 보통 개인 정보 등에 해당하는 컬럼을 권한이 없는 사용자들에게 감추는 목적으로 사용된다.
- 하지만 이 정보가 실수로 노출된 가능성이 높기 때문에 좋은 방법은 아니다.
- 가장 좋은 방법은 별도의 테이블을 구성하는 것이고, 사용하지 않는다면 데이터 시스템으로 로딩하지 않는 것이다.
2) 레코드 레벨 보안 (Row Level Security)
- 테이블 내의 특정 레코드들을 특정 사용자나 특정 그룹, 역할에만 접근 가능하게 하는 것이다.
- 특정 사용자, 그룹의 특정 테이블 대상으로 SELECT, UPDATE, DELETE 작업에 추가한다.
- RLS(Record Level Security) Policy라는 것을
CREATE RLS POLICY명령어를 통해 생성하고 이를ATTACH RLS POLICY라는 명령을 사용해 특정 테이블에 추가한다.
3. Redshift 백업과 테이블 복구
1) Redshift가 지원하는 데이터 백업 방식
Snapshot을 지원한다.Snapshot은 백업 방식은 마지막 백업으로부터 바뀐 것들만 저장하는 방식- 백업을 통해 과거로 돌아가 그 시점의 내용으로 특정 테이블을 복구 가능
Snapshot시점 내용으로 새로운 클러스터를 생성하는 것도 가능
- 자동 백업
- 기본은 하루지만 최대 35 일까지 변경을 백업하게 할 수 있음
Maintenance->Backup details->Edit
- 백업은 같은 지역에 있는 S3로 이루어짐
- 만약 내가 있는 지역에 문제가 생긴다면 이 백업은 의미가 없어짐
- 그래서 AWS에서는 다른 지역에 있는
S3에도 백업을 할 수 있게Cross-Regional Snapshot Copy를 지원하며 재난 복구에 유용함
- 기본은 하루지만 최대 35 일까지 변경을 백업하게 할 수 있음
- 매뉴얼 백업
- 언제든 원할 때 명령을 실행해서 백업
2) Redshift 백업에서 테이블 복구
- 해당 Redshift 클러스터에서
Action(작업)->Restore Table메뉴를 선택. - 복구 대상이 있는 백업(Snapshot) 선택
- 원본 테이블 (Source table) 선택
- 어디로 복구될지 타깃 테이블 선택
3) Redshift Serverless가 지원하는 데이터 백업 방식
- 고정 비용 Redshift에 비하면 제한적이고 조금 더 복잡하다.
Snapshot이 바로 존재하는 게 아니고Recovery Points로부터Snapshot을 만든 다음에 백업이 가능하다.- 고정 비용은 정해진 스토리지가 있어서 그 안에서 바로
Snapshot을 잡을 수 있지만 가변 비용은 기본적으로 컴퓨팅 자원과 스토리지 자원이 따로 존재한다. 고객이 사용한 만큼 청구되기 때문에 고객에게 고정된 자원이 존재하지 않는다. - 그렇기 때문에 지난 24 시간 동안 고객이 사용한 모든 기록을 저장하는 방식을 사용하며 이를
Recovery Points라고 부른다. 데이터 백업->스냅샷->스냅샷 생성
4. Redshift 기타 서비스
1) Redshift Spectrum
Redshift의 확장 기능S3에 있는 파일들이Redshift의 확장 테이블처럼 SQL로 사용 가능- 따로 로드 없이
S3의 파일을 외부 테이블을 처리하면서Redshift테이블과 조인 가능 S3외부 테이블을Fact 테이블이라고 부르고Redshift테이블을Dimension테이블Redshift클러스터가 있어야 하고S3와 클러스터의 지역(Region)이 동일해야 함
2) Athena

AWS의Presto서비스로 사실상Redshift Spectrum과 흡사한 부분이 많다.Athena가 퍼포먼스적으로는 더 좋다.Redshift를 사용한다면Redshift Spectrum을, 만약Redshift를 사용하지 않는데S3에 있는 데이터를 기반으로 사용하고 싶다면Athena를 사용해 주면 된다.
3) Redshift ML
SQL만 사용해서 머신 러닝 모델을 훈련하고 사용할 수 있게 해 주는 서비스이다.AWS에 있는SageMaker에 의해 지원된다.SageMaker은 머신 러닝 데이터를 훈련하면Auto Pilot을 통해 최적화된 모델을 결정해 주거나 생성해 주는 기능을 제공한다.- SageMaker에서 생성한 모델을
Redshift안에 마치 SQL의 함수처럼 임베딩을 해서 어떤 테이블에 있는 레코드, 컬럼을 ML 모델에 input으로 주면 ML 결과가 output으로 나오게 된다. - 모델 트레이닝도 가능하고, 이미 만들어진 모델을 SQL 함수처럼 사용할 수도 있다. (BYOM: Bring Your Own Model)
5. Fact 테이블과 Dimension 테이블
Fact 테이블
- 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블
- 사용자들이 한 행동들이 기록이 되는 테이블로 크기가 클 수 있다.
- Fact 테이블을 다양한 관점에서 분석할 수 있도록 해 주는 테이블이 있다.
Dimension 테이블
- 사용자나 상품에 대한 상세 테이블을 말하며 즉 Fact 테이블에 대한 상세 정보를 제공하는 테이블
- Fact 테이블보다는 크기가 작다.
- Fact 테이블의 데이터 맥락을 제공해 사용자가 다양한 방식으로 데이터를 조각 내고 분석 가능하게 해 준다.
- Fact 테이블의
primary key가 Fact 테이블의foreign key에서 참조
-> Fact 테이블과 Dimension 테이블은 결국 둘을 JOIN 해 주었을 때 더 통찰력 있는 데이터 분석을 하게 해 주는 경우가 많다.
❓ 이게 왜 Redshift Spectrum과 관련이 있는가
Fact 테이블이 굉장히 클 수 있기 때문에 이 데이터를 모두 데이터 웨어하우스에 저장하는 게 비용적, 시간적으로 의미가 없을 수 있기 때문에 비용이 저렴한
S3에 저장해서Redshift에 로드하는 방식이 선호된다.
6. 외부 테이블 (External Table)
1) 외부 테이블(External Table)이란?
- 외부에 있는 굉장히 큰 데이터가 있는 경우 굳이 시스템 안으로 읽어오지 않고 잠깐 읽고 쓰기 위함이 목적이다.
- 데이터베이스 엔진이 외부에 저장된 데이터를 마치 내부 테이블처럼 사용하는 방법을 말한다.
SQL명령어로 데이터베이스에 외부 테이블 생성 가능하다- 외부 테이블을 사용해 데이터 처리 후 결과를 데이터베이스에 적재하거나 외부에 저장하는 것도 가능하다. 대체로는 데이터베이스 안에 저장하기 위해 사용한다.
- 외부 테이블은 굉장히 큰 경우 성능 문제를 일으킬 수 있다. 특히 네트워크를 타고 외부에서 넘어오는 데이터이기 때문에 성능에 문제를 일으킬 수 있는 요소가 있기 때문에 테스트를 충분히 해 보아야 한다.
- 외부 테이블이기 때문에 읽기 전용으로 접근된다.
Hive에서 처음 시작한 개념으로 대부분의 빅데이터 시스템에서 사용됨.
2) 외부 테이블 조작을 위한 Redshift Spectrum 사용 방법
- 먼저 Redshift 클러스터를 S3와 같은 Region에 생성
S3에 있는 파일들을 마치 테이블처럼 SQL로 처리가 가능S3 Fact데이터를 외부 테이블로 정의
💻 [AWS RedShift] 8. Redshift Spectrum으로 S3 외부 테이블 조작 - 실습 포스팅
7. Redshift ML
1) 머신 러닝이란?
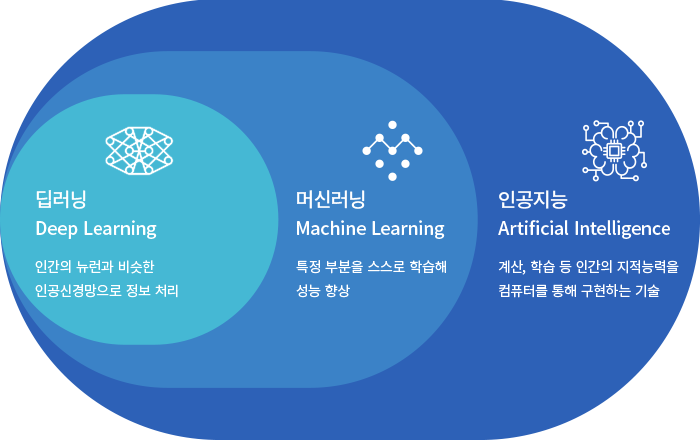
- 배움이 가능한 기계 혹은 알고리즘의 개발
- 데이터의 패턴을 보고 흉내 내는 방식으로 학습
- 학습 데이터를
트레이닝셋(Training Set)이라고 부름. - 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
딥러닝은 머신 러닝의 일부로 비전, 자연 언어 처리 등의 분야에서 적용되고 있다.
2) 머신 러닝 모델이란?
- 머신 러닝의 최종 산물을 머신 러닝 모델이라고 하며 학습된 패턴에 따라 예측해 주는 블랙박스이다.
- 이때 선택한
머신러닝 학습 알고리즘에 따라 내부가 달라진다. - 또한
트레이닝셋품질이 머신 러닝 모델의 품질을 결정한다. - 머신 러닝 모델 종류
- 지도 머신러닝(Supervised Machine Learning): 입력 데이터를 주면 그를 기반으로 예측하는 것
- 비지도 머신러닝 (Unsupervised Machine Learning)
- 강화 학습 (Reinforcement Learning)
- 머신 러닝 모델 트레이닝 혹은 빌딩이란?
- 머신 러닝 모델을 만드는 것
- 입력은 트레이닝셋
📌 예시: 타이타닉 호 승객 생존 여부 예측

- 입력이 주어지는 학습에 대상이 되는 예제가 주어지는데 이를
트레이닝셋이라고 한다. - 그리고 이를 통해 예측해야 하는 대상이 명확하게 주어지는 학습 방법을 지도 학습 방법,
Supervised Machine Learning이라고 한다.
3) Amazon SageMaker란?
- 머신 러닝 모델 개발을 처음부터 끝까지 해결해 주는 AWS 서비스이다.
- Amazon SageMaker 기능
- 트레이닝 셋 준비
- 모델 훈련
- 모델 검증
- 모델 배포 및 관리
- 다양한 머신 러닝 프레임워크인 Tensorflow/Keras 등을 지원한다.
- 그렇다면 Amazon SageMaker을 어떻게 개발할 수 있는가?
SageMaker Studio라는 웹 기반 환경 제공Python Notebook을 통해 모델 훈련스칼라/자바 SDK도 제공Auto Pilot을 통해 최적화된 모델을 결정해 주거나 생성 (이를 사용하면 코드도 구현해 줌)
📌 AutoPilot이란?
- SageMaker에서 제공하는 AutoML
- 훈련용 데이터 셋을 입력하면
- 데이터 분석을 수행하고 이를 파이썬 노트북으로 만들어 줌
- 다수의 머신 러닝 알고리즘과 하이퍼 파라미터 조합에 대해 작업을 수행
- 이 과정에서 머신 러닝 모델을 만들어 훈련하고 테스트 후 결과를 기록
- 선택 옵션에 따라 모델 테스트까지 다 수행하기도 하지만 코드를 만드는 단계에서 마무리하는 것도 가능
- 이 모든 단계를 거쳐 사용자는 모델을 선택 후 API로 만들 수도 있고, 로그를 설정할 수 있다.
8. Redshift 중지/제거하기
✔ 중지는 고정 비용 옵션에만 존재하며 가변 비용 옵션은 중지가 없음
1) Redshift 관련 유지 보수
- Redshift 서비스는 주기적으로 버전 업그레이드를 위해 중단되고, 이를
Maintenance window라고 부른다. Serverless라는 가변 비용 옵션 환경에서는 존재하지 않는다. 왜냐하면 가변 비용 옵션에서는 소유한 리소스가 없기 때문에.
2) 테이블 청소 및 최적화 - VACUUM
파라미터에 따라 다양한 업무를 수행할 수 있다.
- 테이블 데이터 정렬
- 데이터가 삽입, 업데이트, 삭제될 때 데이터는 불규칙하게 분산되어 저장될 수 있는데 이때 데이터를 정렬해 남아 있는 행을 모아 쿼리 실행 시 검색해야 할 블록 수를 줄이는 작업을 수행한다.
- 디스크 공간 해제
- 테이블에서 행이 삭제되면 디스크 공간이 즉시 해제되지 않는다.- 그렇기 때문에 더 이상 필요하지 않은 행을 제거하고 사용한 디스크 공간을 제거하기 위해 VACUUM 명령어를 사용한다.
- 삭제된 행에서 공간 회수
- 테이블에서 행이 삭제되면 VACUUM 명령 실행 전까지 공간이 회수되지 않는다. - 테이블 통계 업데이트
- 테이블 통계를 업데이트해 Query Planner가 쿼리를 최적화할 수 있도록 지원한다.
다만 큰 테이블에 대한 VACUUM 명령은 리소스를 많이 잡아먹는다.
3) Redshift (고정 비용) 클러스터 중지/재실행/삭제
작업->중지에서중지상태로 만들어 줄 수 있다. 다만중지상태가 되면 스토리지에 대한 비용은 부담해야 한다.재실행을 하고 싶은 경우작업->재시작(reboot)를 해 주어야 한다.삭제를 원할 시작업->삭제를 선택해 주어야 하는데 이때 스냅샷(Snapshot)을 통해 저장해 둘 수 있고 이를 통해 삭제되기 직전 시점으로 새로운 클러스터를 생성할 수도 있다.
4) Redshift Serverless (가변 비용) 클러스터 삭제
- 가변 비용 옵션인 Redshift Serverless의 경우 중지라는 개념이 존재하지 않는다.
- 삭제 시 먼저 모든
작업 그룹을 삭제해 주어야 한다. - 이후
네임 스페이스를 삭제한다.
🔎 어려웠던 내용 & 새로 알게 된 내용
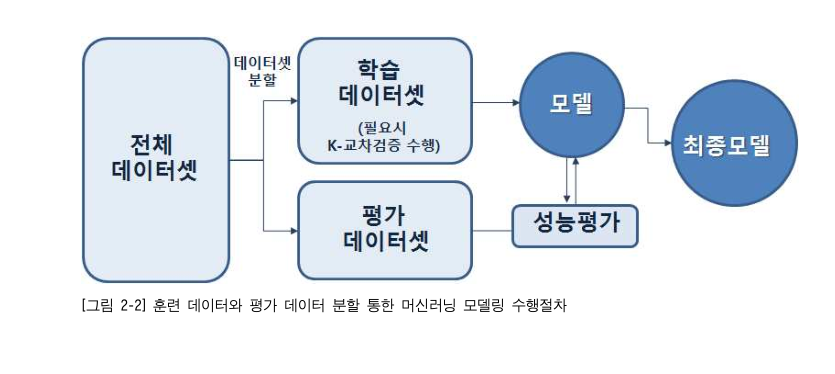
1. Hold-out(홀드 아웃) 테스트
- 다음과 같이 전체의
데이터 셋을학습 데이터 셋과평가 데이터 셋으로 나누었을 때학습 데이터 셋을 통해머신 러닝 모델을 만들게 된다.- 이때
평가 데이터 셋을 통해머신 러닝 모델을 테스트하여학습 데이터 셋에서의 성능을 비교해 성능 평가를 하는 것을 말한다.- 그러나
학습 데이터 셋과평가 데이터 셋으로만 나눠서 모델의 성능을 평가하다보면,평가 데이터 셋이 모델의 파라미터 설정에 큰 영향을 미치게 되어오버 피팅(overfitting)이 될 수 있다.- 이를 해결해 주기 위해 모델의 최적 파라미터들을 찾아 주는
검증 셋을 추가해학습 데이터 셋,검증 셋,평가 데이터 셋으로 나누기도 한다.
✍ 회고
- 과제로 내주신 것들과 실습을 하면서 데이터 웨어하우스를 만들게 된다면 어떤 스키마가 필요한지 그리고 그 안에는 어떤 테이블이 들어가게 될지를 계속해서 생각해 볼 수 있다는 점이 좋다. 다만 Redshift ML 실습은 강의만 듣고 직접 해 보지 못해서 이번 주에 하고 포스팅 올리고 Redshift를 삭제할 예정이다. AWS 서비스에 무료 크레딧 300이 있긴 이전 계정에서 돈이 청구된 경험이 있어서 유독 AWS에서만큼은 실습 시 설정한 환경을 제거할 때 조금 더 꼼꼼히 하게 되는 것 같다.

송의 개발 LOG