
📚 오늘 공부한 내용
1. Snowflake
1) Snowflake란?

- 2014 년 클라우드 기반 데이터 웨어하우스로 시작되었다.
- 데이터 팀을 위한 전용 클라우드라고 볼 수 있을 정도로 발전했다.
- 모든 글로벌 클라우드 위에서 동작한다. AWS, GCP, Azure 등. (멀티 클라우드)
- 데이터 판매를 통한 매출을 가능하게 해 주는
Data Sharing, Marketplace를 제공한다.- 이게 가능한 이유는 스노우플레이크를 데이터 웨어하우스끼리는 데이터 공유를 단순하게 만들어 주어 데이터를 복사해 주는 게 아니라 서로 사용할 수 있게 구현했기 때문에
- ETL과 다양한 데이터 통합 기능을 제공한다.
2) Snowflake의 특징
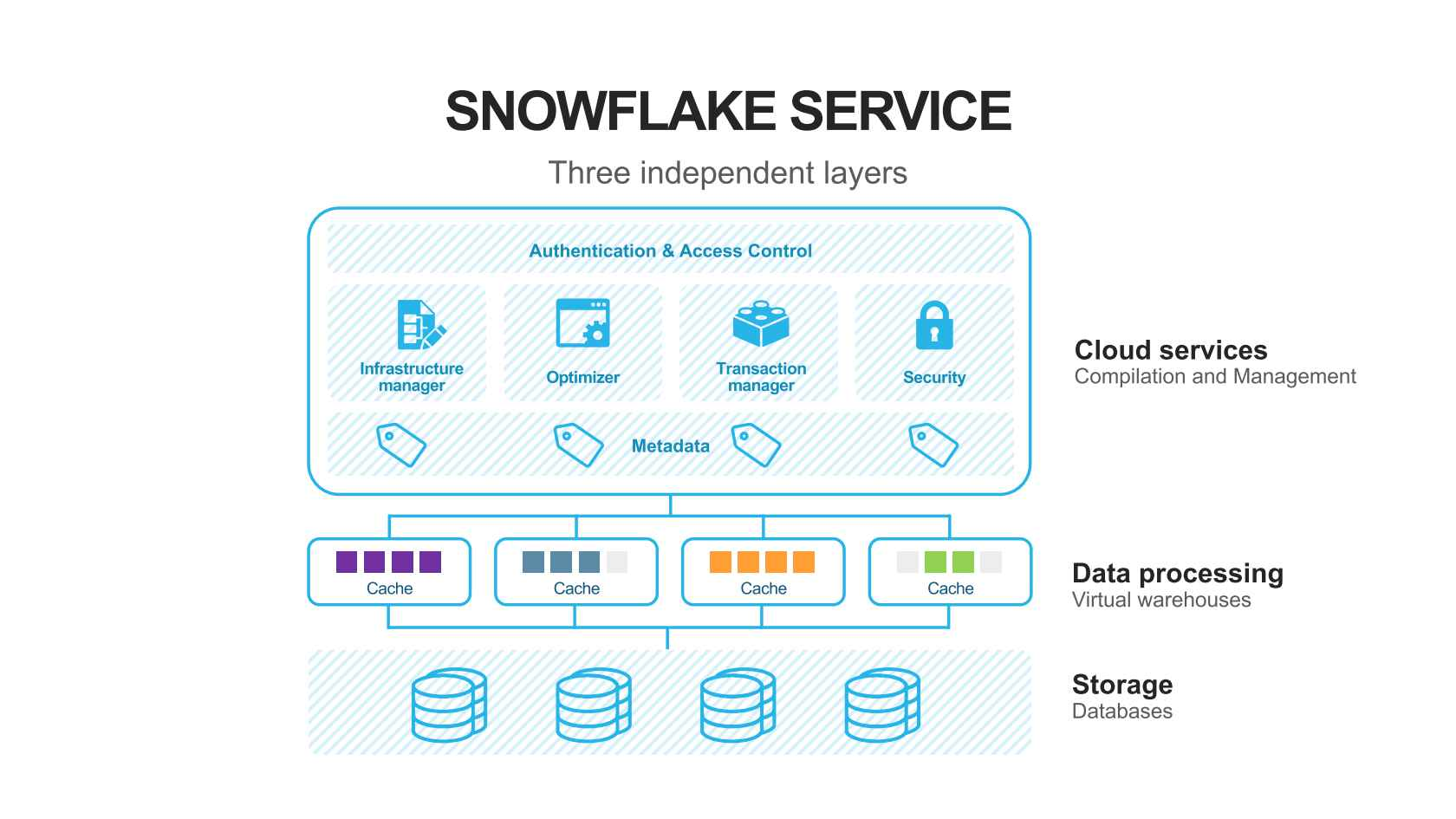
- 스토리지와 컴퓨팅 인프라가 별도로 설정되며 사용한 만큼 비용이 청구되는 가변 비용 모델이다. 즉, 시스템이 부하에 맞게 스케일을 스스로 하는 모델이다.
SQL기반으로 빅데이터 저장, 처리, 분석이 가능하며 비구조화된 데이터 처리도 가능하다.- 머신 러닝 기능도 제공한다.
CVS,JSON,Avro,Parquet등과 같은 다양한 데이터 포맷을 지원한다.- 배치 데이터 중심이지만 실시간 데이터 처리도 지원한다.
- 과거 데이터 쿼리 기능으로 트렌드를 분석하기 쉽게 해 주는
Time Travel기능이 있다. Worksheet라는 웹 에디터를 제공하며 이 안에서 SQL 및 Python API를 통한 관리, 제어가 가능하고, ODBC와 JDBC도 지원한다.- 자체 스토리지 이외에 클라우드 스토리지를 외부 테이블로 사용 가능하다.
- 대표 고객: Siemens, Flexport, Iterable, Affirm, PepsiCo 등
- IT 기업이 아닌 기업들도
snowflake를 많이 사용한다. snowflake는 사용하기 쉽고 고객 지원 서비스가 잘 되어 있다.- 또 멀티 클라우드를 지원하며 다른 지역에 있는 데이터 공유 (Cross-Region Replication) 기능도 지원하고 있기 때문이다.
- IT 기업이 아닌 기업들도
3) Snowflake의 계정 구성도
-
snowflake계정 구성도가Organization->1 + Account->1 + Databases일반적으로 이렇지만 유연성이 있기 때문에 큰 기업이라면Organization부터 중소 기업이라면Account부터데이터베이스를 구성할 수 있다. -
Organization
- 한 고객이 사용하는
snowflake자원들을 통합하는 최상위 레벨의 컨테이너 - 하나 혹은 그 이상의
Account들로 구성되며Account들의 접근 권한, 사용 트래킹, 비용들을 관리하는 데 사용
- 한 고객이 사용하는
-
Account
- 하나의
Account는 자체 사용자, 데이터, 접근 권한을 독립적으로 가짐 - 또한 한
Account는 하나 혹은 그 이상의Database로 구성
- 하나의
-
Databases
- 하나의
Database는 한Account에 속한 데이터를 다루는 논리적인 컨테이너 - 다수의 스키마와 거기에 속하는 테이블, 뷰 등으로 구성
- 하나의
Database가 PB 단위까지 스케일 가능하며 독립적인 컴퓨팅 리소스를 가지게 되는데 이 컴퓨팅 리소스를웨어하우스(Warehouse)라고 부르며웨어하우스(Warehouse)와Database는 일대일 관계는 아님
- 하나의
4) Data Marketplace / Data Sharing
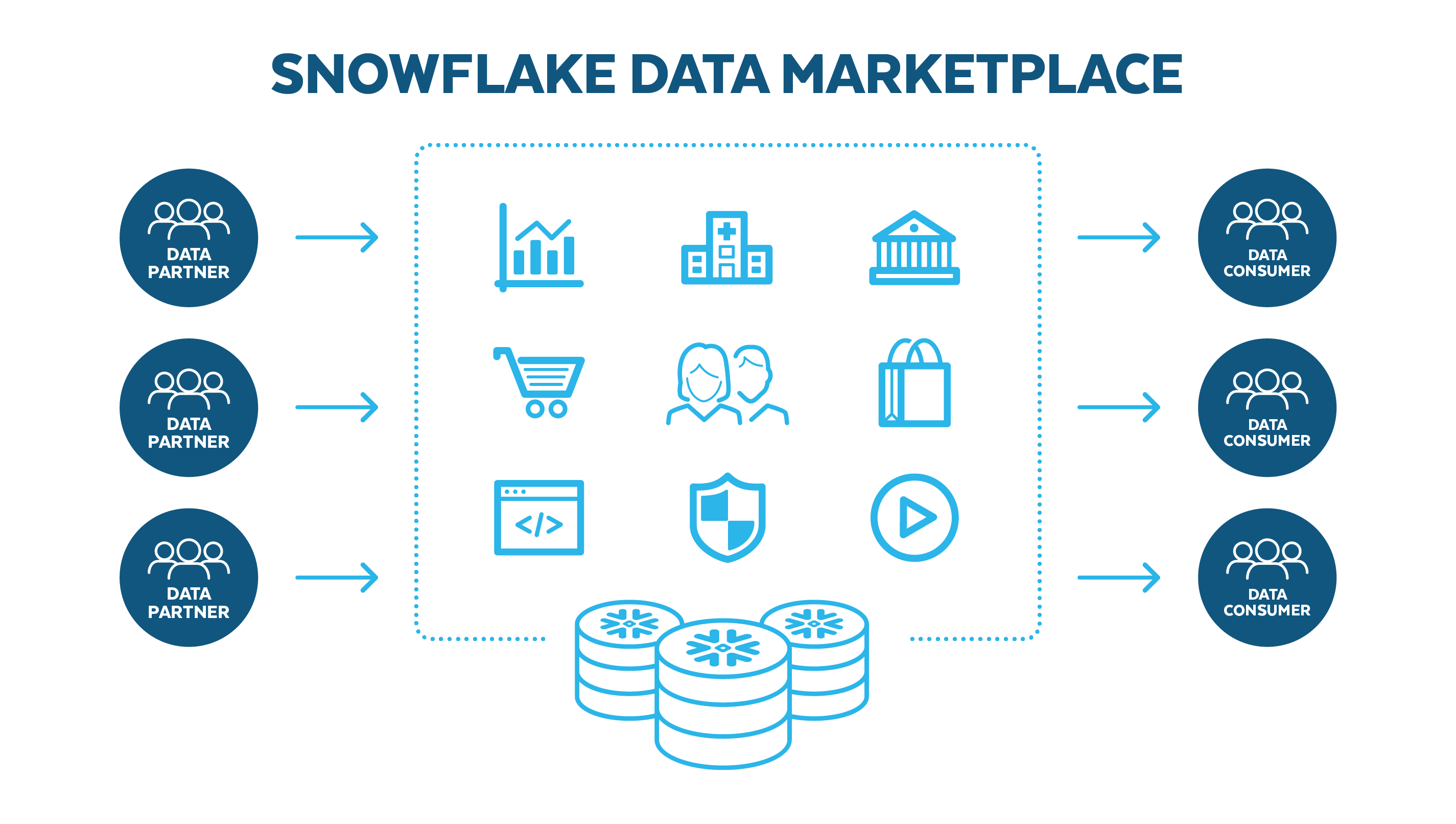
- 데이터를 보내는 사람과 받는 사람이 같은 지역이 있다면 데이터를 전송하는 게 아니라 공유한다.
- 데이터를 내가 카피해서 가지고 가는 것이 아니라 그 사람이 접근 권한을 열어 주면 방문하는 것이다.
- 즉, Share, Don't Move.로
Data Sharing은 데이터 셋을 사내 혹은 파트너에게 스토리지 레벨에서 공유하는 방식을 말한다. - 이때
Data Sharing의 기능을 사용하여 내가 가지고 있는 데이터를 무료 혹은 유료로 다른 사람에게 거래하는 것이Data Marketplace이다.
5) Snowflake의 기본 데이터 타입
✔ 지원해 주는 데이터 타입이 Redshift와 비교했을 때 더 강력하다.
✔ Array를 지원한다는 것은 Nested Structure를 처리할 수 있다는 것을 의미한다.
- Numeric: TINYINT, SMALLINT, INTEGER, BIGINT, NUMBER, NUMERIC, DECIMAL, FLOAT, DOUBLE, REAL
- Boolean: BOOLEAN
- String: CHAR, VARCHAR, TEXT, BINARY, VARBINARY
- Date and Time: DATE, TIME, TIMESTAMP, TIMESTAMP_LTZ, TIMESTAMP_TZ
- Semi-structured data: VARIANT (JSON, OBJECT)
- Binary: BINARY, VARBINARY
- Geospatial: GEOGRAPHY, GEOMETRY
- Array: ARRAY
- Object: OBJECT
2. Snowflake 시작 (무료 시험판)
❄️ [Snowflake] 1. Snowflake 시작 - 실습 포스팅
3. Snowflake 초기 설정
❄️ [Snowflake] 2. Snowflake 초기 환경 설정 및 벌크 업데이트 - 실습 포스팅
4. Snowflake 권한 생성
그룹(Group)은 오래된 기술 중 하나이다.Snowflake는그룹(Group)을 지원하지 않는다. 하지만AWS는 이전에 시작했다 보니 호환성 레거시 이슈 때문에사용자 그룹(Group)을 없앨 수는 없어 그대로 두되역할(Role)을 추가해 주었다.그룹(Group)과역할(Role)은 매우 흡사하나역할(Role)은 계승이 가능하다.Redshift에서는그룹(Group)을 통해 실습해 주었는데 이번Snowflake에서는역할(Role)을 통해 권한 설정 실습을 해 주었다.
❄️ [Snowflake] 3. Snowflake 사용자 권한 설정
5. Data Governance
1) Data Governance이란?
- 데이터가 중요해지면서 데이터의 품질이 믿고 사용할 정도인지, 아니면 데이터를 과도하게 사용해서 개인 정보가 불필요하게 노출이 되고 그로 인해 법률적인 이슈를 만들지는 않는지가 중요해짐.
- 즉, 필요한 데이터가 적재적소에 올바르게 사용됨을 보장하기 위한 데이터 관리 프로세스를
Data Governance라고 함. - 데이터 기반 결정이 일관성 있게 해 주고, 데이터를 이용한 가치를 만들어 준다.
- 데이터 관련 법규를 준수할 수 있도록 도와준다.
- 관련 기능은
Object Tagging,Data Classification,Tag based Masking Policies,Access History,Object Dependencies이 있는데Snowflake의Enterprise에서 쓸 수 있는 기능이다.
2) Object Tagging
- 다양한
Object(Database, Schema, Table, View 등)에 태그를 붙일 수 있는 기능을 말한다. - 이때 태그는
CREATE TAG를 통해 생성 가능하며 해당TAG는 모든 구조에 따라 계승이 가능하다. - 메타데이터를 만들기 위해 해당 기능을 사용한다.
- 민감한 정보나 개인 정보 같이 중요한 정보들을 관리하기 위해
TAGGING하려는 목적이 크다.
3) Data Classification
Object Tagging이 개인 정보 관리를 위해 사용하기는 하지만 매뉴얼하게 관리하기가 쉽지 않아 이 문제를 해결하기 위해Data Classification을 사용한다.- 3 가지 단계로 구성되어 있다.
- Analyze: 특정 테이블에 Data Classification를 적용하면 그 테이블의 레코드를 보고 이 컬럼에 개인 정보나 민감 정보가 있는지 컬럼별로 분류한다.
- Review: 이후 사람(대부분 데이터 엔지니어)이 Analyze 단계의 정보를 보고 최종적으로 리뷰한다. 이때 결과를 수정할 수도 있다.
- Apply: 최종 결과를
시스템 태그(System Tag)로 적용한다. 이때 두 개의 카테고리가 존재한다.PRIVACY_CATEGORY: 상위 레벨 (IDENTIFIER 개인 정보 개인 식별자, QUASI_IDENTIFIER 유일하게 개인을 식별할 수 있는 ID는 아니지만 이런 식별자가 여러 개가 모이면 개인을 지칭할 수 있어지는 개인 준식별자, SENSITIVE 개인 정보는 아니나 민감한 정보)SEMANTIC_CATEGORY: 하위 레벨로 좀 더 상세한 정보
4) Tag based Masking Policies
- 먼저
Tag에 액세스 권한을 지정해 주고, 이런 개인 정보 같은Tag가 붙은 Object에 누가 접근할 수 있는지에 대한 권한을 부여해 주는 것을 말한다.
5) Access History
- 데이터 액세스에 대한 감사 추적을 제공해서 보안과 규정을 준수할 수 있게 해 준다.
- 이때 *누가, 언제 접근을 했는지에 대한 다양한 기록들이 저장이 된다. (사용자 신원, IP 주소, 타임 스탬프 등)
Access History를 통해 추적된 활동에 대해 알림을 보내 주기도 한다.- 대부분의 클라우드에 있는 기능이다.
6) Object Dependencies
Data Governance와 시스템 무결성 유지를 목적으로 한다.- 예를 들어 테이블 이름이나 컬럼 이름을 변경하거나 삭제해 주는 경우 혹은 뷰를 수정하는 경우 이로 인해 연관이 있는 시스템에 오류가 발생할 수 있다.
- 그래서
Object Dependencies는 이로 인해 발생하는 영향을 자동으로 식별해 준다. - 보통 다른 데이터 웨어하우스는 데이터 웨어하우스 내에서 이걸 처리해 주지 못하고 외부 프로그램을 사용하는데
snowflake는 데이터 웨어하우스 내에서 이 기능을 제공한다.
6. Marketplace
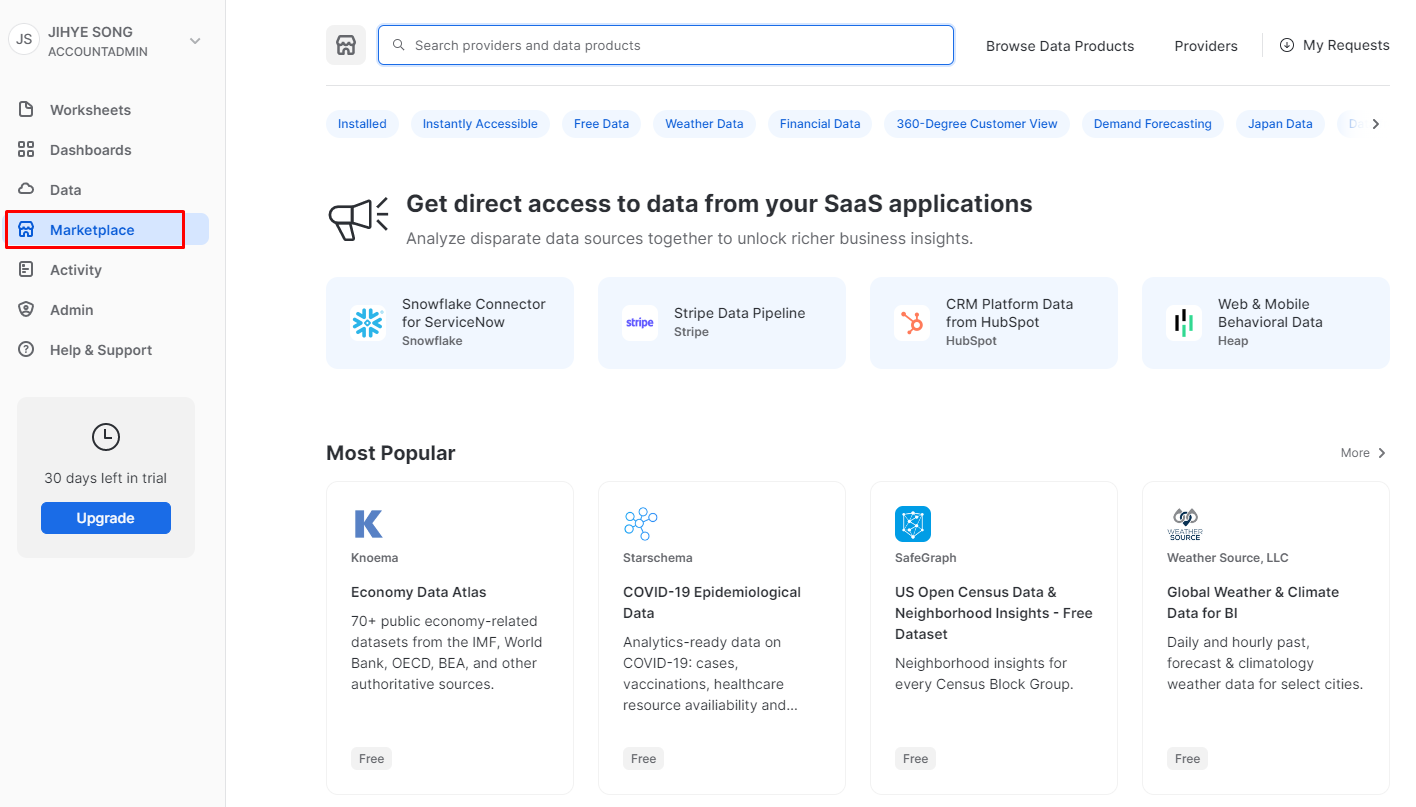
- 목록에서
Marketplace를 선택해 주면Marketplace가 나온다. Snowflake를 사용하는 회사들이 많다 보니 해당 회사들이 외부 데이터 소스를 쉽게 연동할 수 있는plugin과 같은 기능을 제공한다.- 예를 들어
Stripe Data Pipeline의 경우 구매 기록을Stripe에 남길 때 해당 파이프라인을 데이터 엔지니어가 작성하게 되는데 패턴이 워낙 많고 작성하는 데 걸리는 시간이 있다 보니 다음과 같이Marketplace에서 해당Stripe Data Pipeline을 클릭해 주어configuration set up을 해 주면 그 회사의 파이프라인, 트랜잭션들이 스키마 밑에 테이블들로 복제되어 사용할 수 있게 된다. - 이를 통해 코딩을 최소화할 수 있다.
7. Data Sharing
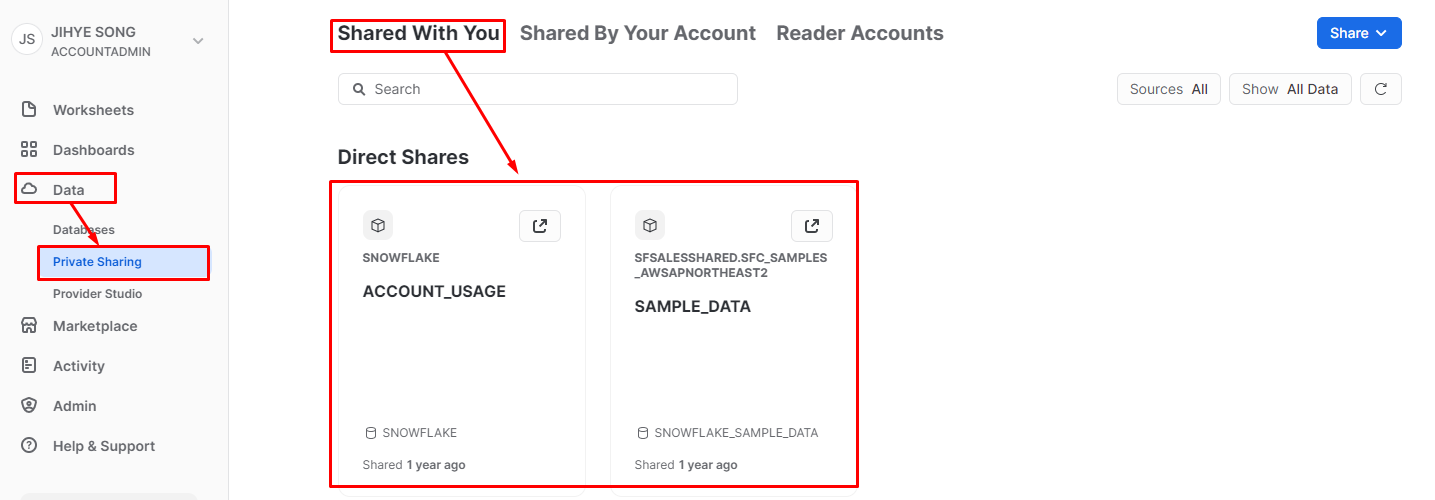
Data->Private Sharing을 통해 내가 공유한 데이터와 공유받은 데이터들을 볼 수 있다.- 내가 만든 데이터를 다른
Account와 공유하고 싶을 때는 우측 상단에 있는Share버튼을 눌러 공유할 수 있다.
8. Query/Copy/Task History
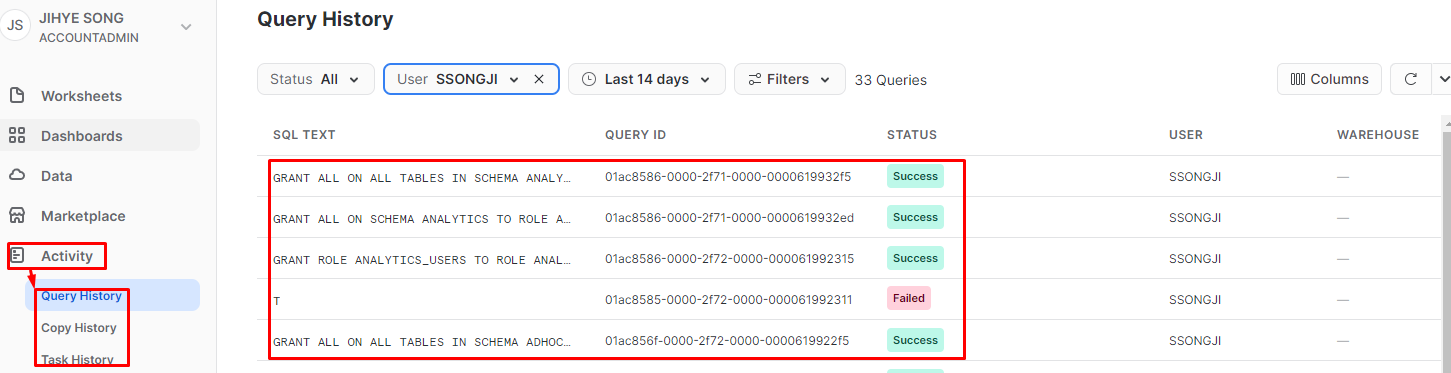
Activity->Query/Copy/Task History를 선택해 확인할 수 있다.- 먼저
Query History란 SELECT, DELETE, UPDATE 등과 같은SQL 쿼리문에 대한 로그 기록이 남는 것이고, 다음과 같이STATUS라고 해당SQL 쿼리문이 성공했는지, 실패했는지에 대한 로그도 남게 된다. Copy History란COPY명령어를 통해 벌크 업데이트를 했을 때의 기록이 남는다.TasK History는 특정한 SQL을 내가 주기적으로 실행해 주는 것을TASK라고 하고 이것에 대한History기록을 보여 주는 것이다.- 이때
Access History와Query History의 차이는Query History는 단순하게 쿼리문에 대한 기록만 남지만Access History는 더 상세하게 어떤 테이블에 어떤 컬럼이 접근돼 있었고, 그 컬럼의 특성까지 자세하게 기록한 것이다.
🔎 어려웠던 내용 & 새로 알게 된 내용
- 오늘은 실습 위주라 어려웠던 내용이 없었다. 새로 알게 된 내용도 모두
snowflake관련이라 학습한 내용에 기재되어 있다.
✍ 회고
- snowflake를 처음으로 사용해 보았는데 redshift와 snowflake의 전체적인 기능은 크게 다르지 않았고, COPY 명령 SQL문이 조금의 차이가 있었다. 그런데 개인적으로 snowflake의 사용이 조금 더 간편하다고 느꼈다. 아마 프로젝트를 진행하게 된다면 redshift를 사용하게 될 것 같지만 이후에 snowflake를 통한 데이터 웨어하우스 환경도 접할 기회가 있으면 좋겠다고 생각했다.
- 오늘 학습한 내용과 별개로 알게 된 게 있는데 고객 지원을 영어로 바꾼 말이 velog에서는 사용이 불가한 단어인지 비공개 설정이 된다. 계속 비공개 설정이 되는 말들이 꽤 있던데 처음 겪는 일이라 하나씩 제외해 보는 과정이 좀 번거로웠다.

송의 개발 LOG