
📚 오늘 공부한 내용
1. Redshift 특징
AWS에서 지원하는 데이터 웨어하우스 서비스- 최대 2 PB의 데이터까지 처리 가능하고, 최소로는 160 GB로 시작한다. (고정 비용으로 사용했을 때)
Still OLAP: 응답 속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용하면 장애가 발생할 수 있음.- 컬럼 기반 스토리지
- 레코드 별로 저장하는 것이 아니라 컬럼별로 저장함
- 컬럼별 압축이 가능하고, 컬럼 추가와 삭제가 빠름
- 벌크 업데이트를 지원
- 이건 모든 데이터 웨어하우스가 가지는 특징
- 레코드가 들어 있는 파일을 S3로 복사 후에 COPY Command로 Redshift로 일괄 복사
- 고정 용량/비용 SQL 엔진이지만
Redshift Serverless는 가변 비용 옵션도 제공하고 있음. - 데이터 공유 기능 (Datashare): Snowflake에서 처음 시작함. 내가 가진 데이터를 다른 데이터에 오픈해 주고, 경우에 따라 돈을 받기도 하는 데이터로 매출을 올릴 수 있는 기능.
Primary Key Uniqueness를 보장하지 않는다.Postgresql 8.X와 SQL이 호환되기 때문에 지원하는 툴이나 라이브러리로 액세스 가능하다.
✍ [AWS RedShift] 1. AWS RedShift 개념
일전에 강의를 듣고, 추가적으로 공부해서 작성했던 Redshift의 개념에 대해 Redshift 실습에 앞서 다시 정리하는 느낌이었다.
2. Redshift의 스케일링 방법
- Scale Out
- 용량이 부족해졌을 때 새로운 노드를 추가한다.
- 예를 들어 dc2.large 하나면 최대 0.16 TB인데 이 용량이 부족해졌다면 dc2.large를 한 대 더 추가해 총 0.32 TB로 늘리는 것을 말한다.
- Resizing을 활성화해 Auto Scaling을 on 해 주면 Redshift가 자동으로 처리하게 해 줄 수 있다.
- Scale Up
- 용량이 부족해졌을 때 사양을 높인다.
- 예를 들어 dc2.large인데 이 용량이 부족해졌다면 더 사양이 좋은 dc2.8xlarge 한 대로 교체하는 것을 말한다.
Snowflake과BigQuery와는 방식이 다르다. 왜냐하면 둘은 가변 비용 옵션이기 때문에 특별하게 용량이 정해져 있지 않고 쿼리를 처리하기 위해 사용한 리소스에 해당하는 비용을 지불하면 된다. 훨씬 더 스케일링한 데이터베이스 기술이지만 비용 예측이 불가능하다라는 단점이 존재한다.
3. Redshift 최적화
1) 왜 Redshift는 최적화가 복잡한가?
Redshift가 두 대 이상의 노드로 구성되면 한 테이블의 레코드들을 저장하기 위해서는,- 분산 저장을 해야 한다.
- 어떻게 저장될지 한 노드 내에서 순서를 개발자가 지정해 주어야 한다.
- 그렇기 때문에
데이터 스큐(Data skew)가 발생한다. Snowflake와BigQuery는 이를 개발자가 관리할 필요 없고 자체에서 알아서 처리해 준다.
2) RedShift 레코드 분배, 저장 방법
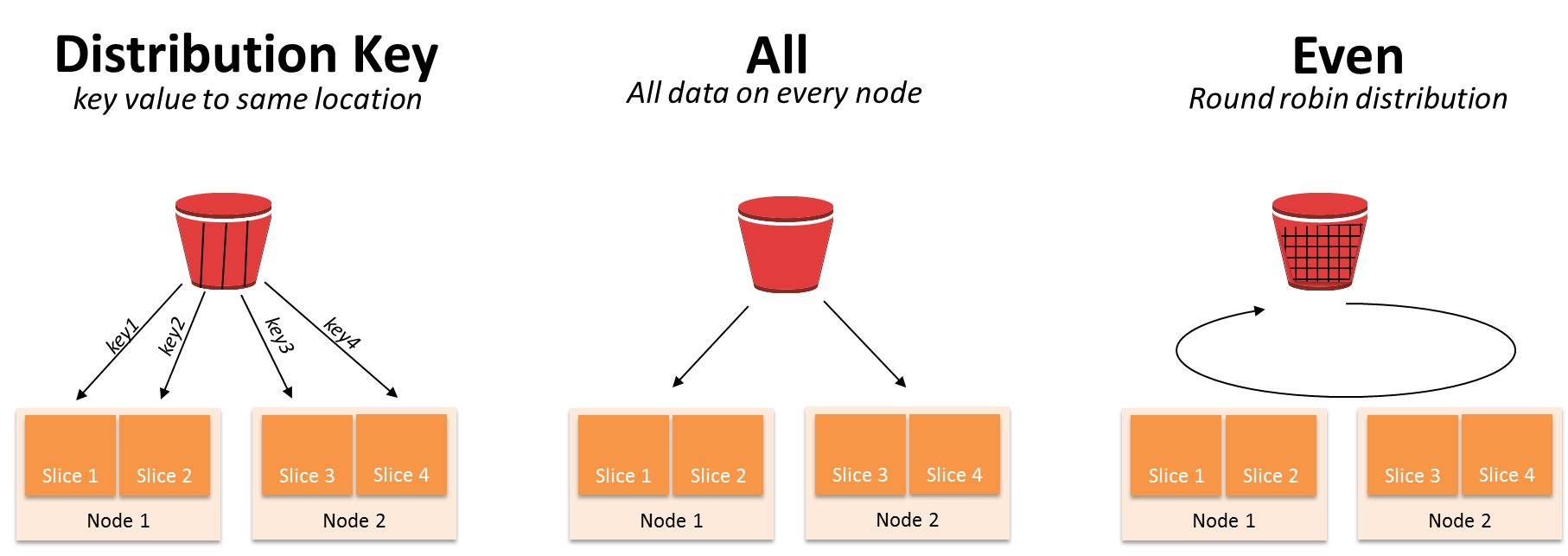
-
Diststyle
- 한 테이블에 속성으로 지정
- 그 속성에 맞게 테이블의 레코드들이 다수의 노드로 분배
all: 모든 레코드들이 모든 노드에 분배 (가장 많이 사용됨)even: 노드별로 돌아가면서 레코드를 하나씩 분배 (default 값)key: 특정 컬럼의 값을 기준으로 레코드들이 다수의 노드로 분배 (보통 primary key처럼 고유한 컬럼을 사용) -> 이때 사용되는 것이Distkey
-
Distkey
- diststyle 속성이 key인 경우만 유효하다.
- 분배 기준이 되는 컬럼의 이름을 지정한다.
-
Sortkey
- 어떤 테이블들에 들어 있는 레코드들이 노드로 분배된 후에 그 안에서 어떻게 정렬이 될지 기준을 정해 주는 속성이다.
- 특정 컬럼의 이름이 오게 되며 보통 타임 스탬프 필드가 된다.
-- 다음과 같은 Query를 작성할 수 있음
-- 이 경우 key 형식으로 col1을 기준으로 레코드들이 분배되고
-- 같은 노드 내에서는 col3를 기준으로 정렬된다는 뜻
CREATE TABLE my_table(
col1 INT,
col2 VARCHAR(50),
col3 TIMESTAMP,
col4 DECIMAL(18, 2)
) DISTSTYLE KEY DISTKEY(col1) SORTKEY(col3);⚡ Diststyle이 key인데 컬럼 선택이 잘못된다면?
Diststyle이 key라는 건 특정 key의 값이 같은 레코드들은 같은 노드에 들어가게 되는 것이다.Group by를 하거나Join을 하면 데이터의 이동이 별로 없어서 좋다는 장점이 있다.- 그런데 만약 그 key의 컬럼에
스큐(skew)가 있다면? 그래서 특정 key를 갖는 레코드가 많아진다면?
- 노드 1에는 많은 데이터가 들어가고 노드 2에는 작은 데이터가 들어가는 불균형이 생기게 된다.
- 이는 특정 테이블을 처리할 때는 더 많은 시간이 걸리고 다른 테이블을 처리할 때는 빨리 처리되는 등 이후 데이터 처리에 문제가 발생한다.
- 그렇기 때문에 레코드 분배에
스큐(skew)가 발생했는지 확인을 해 주어야 한다.
4. 벌크 업데이트
Redshift에서 벌크 업데이트를 하는 방식은COPY SQL이다. 이 방법은Redshift의 고유한 방법은 아니고 모든 데이터 웨어하우스에서 제공하는 방식이다.
📌 벌크 업데이트 순서
- 데이터 소스로부터 데이터를 추출
- 압축율이 좋은
Binary file로 만든 다음 이를 클라우드 스토리지에 로딩한다. (Redshift라면 S3) COPY SQL을 통해 한 번에Redshift의 원하는 테이블로 업데이트한다.
5. Redshift 기본 데이터 타입
📌 PostgreSQL과 크게 다르지 않지만 CHAR 단위가 Redshift에서는 바이트 단위가 된다는 차이점이 존재한다. (이 부분을 유의해야 함.)
- SMALLINT (INT2)
- INTEGER (INT, INT4)
- BIGINT (INT8)
- DECIMAL (NUMERIC)
- REAL (FLOAT4)
- DOUBLE PRECISION (FLOAT8)
- BOOLEAN (BOOL)
- CHAR (CHARACTER)
- VARCHAR (CHARACTER VARYING)
Redshift에서는 CHAR 단위가 기본적으로 바이트 단위가 된다. 그러므로 한중일(3bytes - 1char) 언어인지, 영어(1byte - 1char)인지에 따라서 CHAR 타입으로 포함하는 문자열의 크기가 달라진다. - TEXT (VARCHAR(256))
최대 CHAR 타입이 65535 bytes가 된다. - DATE
- TIMESTAMP
- GEOMETRY
- GEOGRAPHY
- HLLSKETCH
- SUPER
6. Redshift Serverless 설치
💻 [AWS RedShift] 4. AWS RedShift Serverless 생성
실습이라 따로 포스팅 해 두었습니다.
7. Redshift 초기 설정
1) Redshift Schema
- 스키마란 테이블들을 목적에 맞게 카테고리를 만들어 구조적으로 관리하는 일종의 폴더
- 다른 기타 관계형 데이터베이스와 동일한 구조
- 실습에서는 네 개의 별도 스키마를 만들어 볼 것

- raw_data라는 ETL 결과가 들어가는 스키마
- analytics라는 ELT 결과가 들어가는 스키마
- adhoc라는 테스트용 테이블이 들어가는 스키마
- pii이라는 개인 정보가 들어가는 스키마 - 스키마만 봐도 이 테이블의 목적이 무엇인지를 파악할 수 있도록 하는 것이 목적
2) 스키마(Schema) 생성
- 먼저
CREATE SCHEMA쿼리문을 통해 각각의 스키마를 생성해 준다.
CREATE SCHEMA RAW_DATA;
CREATE SCHEMA ALALYTICS;
CREATE SCHEMA ADHOC;
CREATE SCHEMA PII;- 만약 생성한 스키마를 조회하고 싶다면 다음과 같이
SELECT문과PG_NAMESPACE를 통해 조회할 수 있다.
SELECT *
FROM PG_NAMESPACE;3) 사용자(User) 생성
- 보통은 사용자를 생성할 때 비밀번호에 대한 제약 조건이 존재한다.
PASSWORD뒤에 설정해 줄 비밀번호를 입력해 주면 된다.CREATE USER를 통해 사용자를 생성해 줄 수 있다.
CREATE USER song PASSWORD '...';- 사용자를 조회하고 싶다면 다음과 같이
SELECT문과PG_USER를 통해 조회할 수 있다.
SELECT *
FROM PG_USER;4) 그룹(Group) 생성 및 설정
- 사용자에게는 테이블 접근 권한을 주어야 하는데 사용자가 많아지게 되면 개개인에게 일일이 권한을 부여하기가 어려워진다.
- 이를 해결하는 방법은 테이블별로 접근 권한을 정하는 것이 아니라 스키마 권한을 정하고, 사용자들도 사용자별로 권한을 정하는 것이 아니라 그룹으로 권한을 정하는 것이다.
- 한 사용자는 다수의 그룹에 속할 수 있다.
- 예를 들면 다음과 같은 그룹이 존재할 수 있다.
- 데이터 활용을 하는 개인을 위한
analytics_users - 데이터 분석가를 위한
analytics_authors - 개인 정보 스키마까지 접근할 수 있는
pii_users
- 데이터 활용을 하는 개인을 위한
- 그룹은 계승이 안 된다. 즉, 그룹끼리의 교집합이 존재해도 해당 부분까지 반복해서 설정해 주어야 한다. 그래서 너무 많은 그룹이 생기면 관리가 힘들어진다.
- 이 문제를 해결하기 위해 나온 것이
역할(Role)이다. 역할은 계승이 가능하다. CREATE GROUP구문을 통해 그룹을 생성할 수 있다.
CREATE GROUP analytics_users;
CREATE GROUP analytics_authors;
CREATE GROUP pii_users;- 그룹 내에 사용자를 넣어 주기 위해서는
ALTER GROUP groupname ADD USER username을 사용해 준다. 이후GRANT쿼리문을 통해 각각 권한을 부여해 줄 수 있는데 이 단계는 뒤에서 나올 예정이다.
ALTER GROUP analytics_users ADD USER song;
ALTER GROUP analytics_authors ADD USER song;
ALTER GROUP pii_users ADD USER song;- 이후 그룹 목록을 확인하려면
SELECT와PG_GROUP을 통해 볼 수 있다.
SELECT *
FROM PG_GROUP;5) 역할(Role) 생성 및 설정
- 그룹과 거의 동일하나 계승 구조를 만들 수 있다.
- 역할은 사용자에게 부여될 수 있고 다른 역할에 부여할 수도 있다.
- 한 사용자는 그룹과 동일하게 다수의 역할에 소속 가능하다.
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;- 개인과 역할에 각각 권한을 부여해 줄 수 있다.
- 개인에게 부여할 경우
GRANT ROLE rolename TO username,GRANT ROLE rolename TO ROLE otherrolename으로 쿼리문을 사용해 주면 된다.
-- staff 역할을 song이라는 사용자에게 부여한다.
GRANT ROLE staff TO song;
-- staff 역할을 manager 역할에게 부여한다
GRANT ROLE staff TO ROLE manager;- 이때 생성된 역할들을 목록으로 보고 싶다면
SELECT와SVV_ROLES로 확인할 수 있다.
SELECT *
FROM SVV_ROLES;💻 [AWS RedShift] 5. SQL로 Redshift 초기 설정 - 실습 포스팅
8. 벌크 업데이트 (Bulk Update) 구현
COPY명령을 통해raw_data스키마 밑 3 개의 테이블에 레코드를 적재
1) raw_data 스키마 밑 테이블 생성
- 3 개의 테이블에 저장할 것이기 때문에 3 개의 테이블 생성
raw_data의 목적은 ETL을 통해 외부에서 읽어온 데이터를 저장한 스키마이다.CREATE TABLE을 통해 생성해 준다.
CREATE TABLE raw_data.user_session_channel(
USERID INTEGER
, SESSIONID VARCHAR(32) PRIMARY KEY
, CHANNEL VARCHAR(32)
);
CREATE TABLE raw_data.session_timestamp(
SESSIONID VARCHAR(32) PRIMARY KEY
, TS TIMESTAMP
);
CREATE TABLE raw_data.session_transaction(
SESSIONID VARCHAR(32) PRIMARY KEY
, REFUNDED BOOLEAN
, AMOUNT INT
);2) 적재할 S3 bucket 생성 및 csv 파일 S3로 복사
COPY SQL을 통해 데이터를 적재해 주기 위해서는 csv를 S3에 업로드 해 주는 과정이 필요하다.AWS콘솔에서S3 bucket을 생성해 주어야 한다.- 하나의
bucket에 csv 파일을 담을 폴더를 생성해 주고 1에서 생성한 테이블에 상응하는 csv 파일들을 해당 폴더에 업로드 해 준다. - 그런데 이 과정에서 Redshift가 S3에 접근할 수 있는 권한이 없다면
COPY가 불가능하다. 그래서 먼저 권한을 부여해 준다.
3) Redshift에 S3 접근 권한 부여
- Redshift가 S3에 접근할 수 있는 역할을
IAM (Identity and Access Management)을 통해 생성해 주어야 한다. - 그 후 이 역할을 Redshift 클러스터에 지정해 주어야 한다.
IAM Role만들기
-IAM웹 콘솔 방문- 왼쪽 메뉴에서
Roles선택 Create Role선택 후AWS Service를 선택한 후Common use cases에서Redshift-Customizable를 선택해 준다. (해당 역할을 Redshift에 주고 싶은 권한이라는 뜻)- 정책 설정에서
AmazonS3FullAccess를 선택해 준다. (S3에 접근할 수 있는 권한을 부여할 것이기 때문에) - 검토 화면이 뜨면 Role의 이름을 부여한다.
redshift.read.s3로 설정.
- 왼쪽 메뉴에서
- Redshift 콘솔에서 해당 클러스터의
보안 및 암호화(Security and Encryption탭 아래Manage IAM roles라는 버튼을 선택해 준다. Associate IAM roles에서 앞서 만든redshift.read.s3역할을 지정해 준다.
4) COPY 명령을 사용해 CSV 파일을 테이블로 복사
- S3로 로딩한 파일들을
벌크 업데이트를 수행해 테이블에 적재하는 과정이다. COPY SQL사용한다.- csv 파일이기 때문에 delimiter(구분 문자)로는 콤마(,)를 사용해 준다.
- 문자열이 따옴표로 둘러싸인 경우 제거하기 위해
removequotes를 지정해 준다. - csv 파일의 헤더를 무시하기 위해
IGNOREHEADER 1을 지정해 준다. CREDENTIALS에 앞서Redshift에서 지정한역할(Role)을 사용해 주는데 이때 역할의ARN을 읽어와야 함.
COPY raw_data.user_session_channel
FROM 's3://s3의 csv 위치`
CREDENTIALS 'aws_iam_role=arn:aws:iam:xxxxxx:role/redshift.read.s3'
DELIMITER ','
DATEFORMAT 'auto'
TIMEFORMAT 'auto'
IGNOREHEADER 1
REMOVEQUOTES;- 위의
SQL구문을 세 개의 csv 파일과 세 개의 테이블에 진행해 주어야 함. - 보통은 csv 파일이 아니라
binary file format을 쓴다.
5) 만약 COPY 과정에서 에러가 발생했다면?
- STL_LOAD_ERRORS 테이블을 보고 에러에 대해 확인한다.
- 이를 통해 어떤 field에서 에러가 났는지를 확인할 수 있다.
SELECT *
FROM STL_LOAD_ERRORS
ORDER BY STARTTIME DESC;- 보통 이런 오류는 csv 파일과 테이블 field의 데이터 타입이 다르거나 정해진 데이터 타입의 길이를 초과하는 경우 발생한다.
💻 [AWS RedShift] 6. 벌크 업데이트 (Bulk Update) 구현 - 실습 포스팅
9. analytics 테스트 테이블 만들기
raw_data에 있는 테이블을 조인해서 필요한 정보들을 가지고 새로운 테스트 테이블을analytics스키마에 만들어 보자.- 이 과정을
ELT라고 하며 간단하게CTAS로 구현 가능하다.
CREATE TABLE ANALYTICS.MAU_SUMMARY AS
SELECT TO_CHAR(A.TS, 'YYYY-MM') AS MONTH
, COUNT(DISTINCT B.USERID) AS MAU
FROM RAW_DATA.SESSION_TIMESTAMP A
JOIN RAW_DATA.USER_SESSION_CHANNEL B
ON A.SESSIONID = B.SESSIONID
GROUP BY 1
ORDER BY 1 DESC;🔎 어려웠던 내용 & 새로 알게 된 내용
1. 데이터 스큐 (Data Skew)
스큐(skew)는 직역으로 해석하면 비뚤어진, 비스듬한이라는 뜻이다.- 그렇다면
데이터 스큐 (Data Skew)는 비스듬한, 비뚤어진 데이터를 말한다.- 예를 들어 어떤 테이블의 데이터를 세 개의 노드로 나눠 저장한다고 할 때 분배가 잘못되면 한 테이블에 많은 데이터가 들어가고 다른 테이블에는 소수의 데이터만 들어가게 된다면 분산 저장하는 이유가 없어진다.
- 이렇게 한쪽에만 많은 데이터가 쌓이는 경우, 데이터의 비대칭이 일어나는 경우를
스큐(skew)라고 한다.
2. removequotes
- 입력 데이터의 문자열에서 묶고 있는 인용 부호를 제거하고, 인용 부호 안의 문자는 구분자를 포함해 모두 유지하도록 하는 SQL 구문
- 예를 들어 "흰색"이라는 문자열이 있다면 removequotes를 사용하면 큰 따옴표를 제외하고 흰색이 반환된다.
- 다만 문자열에 선행하는 작은 따옴표나 큰 따옴표만 있고 후행하는 인용 부호가 없을 때는 오류가 발생한다.
- 예를 들어 "파란색에 대해 removequotes를 사용하면 오류가 발생한다.
- 하지만 파란색"에 대해서는 removequotes를 사용해도 오류는 발생하지 않고, 파란색"이라고 그대로 나오게 된다.
- 즉, 선행되는 작은 따옴표나 큰 따옴표가 없고 후행하는 인용 부호만 있을 경우는 오류가 나진 않지만 인용 부호 역시 제거되지 않는다.
3. ARN
Amazon 리소스 이름을 말하며AWS 리소스의 고유 식별자이다.- 대개
IAM 정책,RDS 태그 및 API 호출과 같은AWS 리소스를 명료하게 지정해야 하는 경우에 사용한다.- ARN의 형식
arn:partition:service:region:account-id:resource-type:resource-idarn:partition:service:region:account-id:resource-type/resource-idarn:partition:service:region:account-id:resource-id
✍ 회고
- 강사님께서 과제로 내어 주셨던 가상의 데이터 파이프라인을 작성하는 것을 해 보았다. 평소 관심 있고 좋아하는 분야에 대해 구성하다 보니 생각보다 주제가 쉽게 잡혔던 것 같다. 물론 가상이지만 ETL/ELT를 포함한 파이프라인을 구상하는 것은 쉽지 않았다. 테이블 구조의 경우 일단 단순하게 들어가야 할 정보 위주로만 가긴 했지만 ERD를 통해 이 부분을 구체화한다면 아마 PRIMARY KEY도 필수적으로 추가해야 할 것이고, 좀 더 생각해 보아야 할 게 많았다. 실제 프로젝트를 통해 파이프라인을 구성하게 된다면 더 신경 써야 될 부분이라고 생각했다.
- 실습을 통해 하니까 좀 더 redshift를 어떻게 써야 하는지에 대해 감이 잡히기 시작했다. 사실 저번 강의 때 벌크 업데이트에 대한 이야기가 짧게 나온 적이 있는데 그때는 몰라서 벌크 업데이트에 대해서 찾아 보았었다. 오늘 확실하게 개념과 사용하는 방법이 잡힌 느낌이다.

송의 개발 LOG