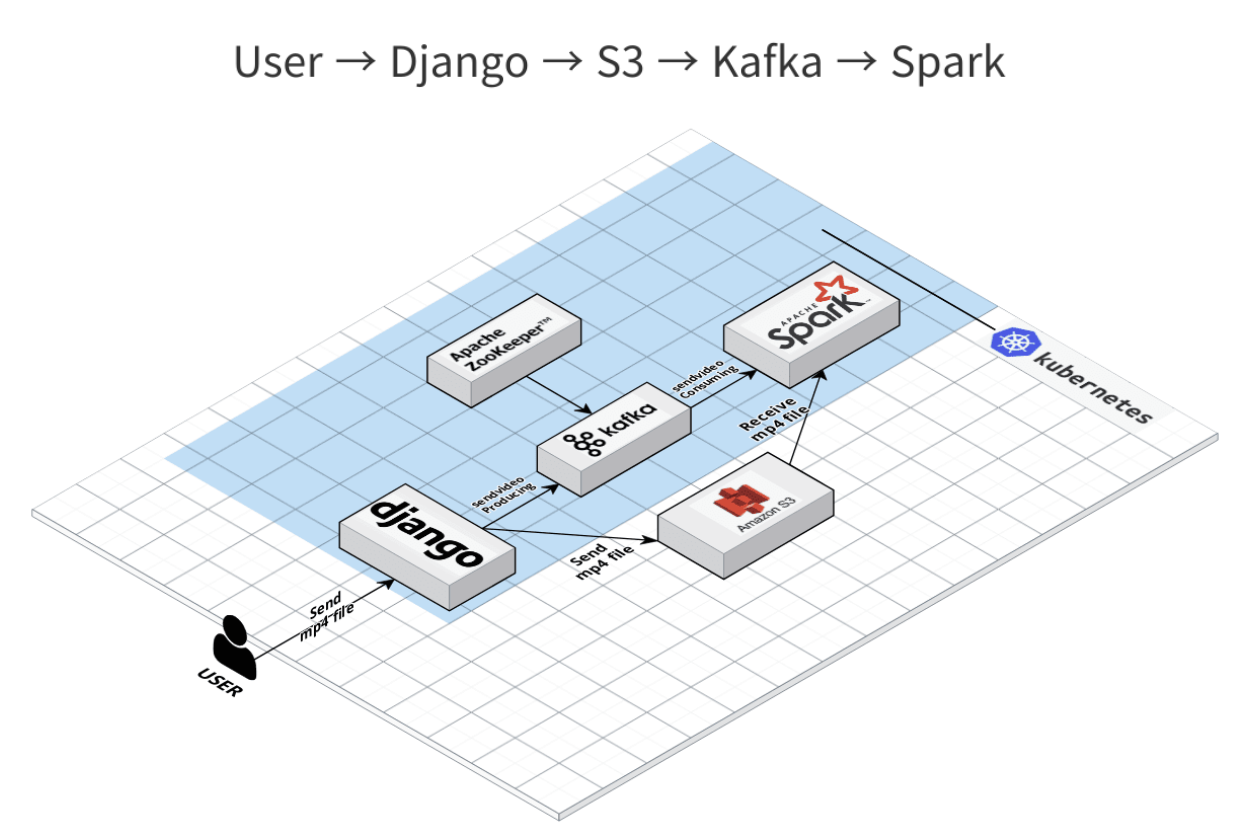
개요
- S3 -> Kafka -> Spark
- S3로부터 mp4 파일을 다운로드 받는 코드 &
- Kafka-python API를 사용하여 Python Consumer 개발 예정
Install
pip install opencv-python코드
- Spark(Python)
# pip install kafka-python
# pip install boto3
# pip install opencv-python
import subprocess
from kafka import KafkaConsumer
from json import loads
import environ
import boto3
import cv2
import os
BUCKET_NAME = os.environ['bucket_name']
s3 = boto3.client(
service_name='s3',
region_name=os.environ['Region_name'],
aws_access_key_id=os.environ['aws_access_key_id'],
aws_secret_access_key=os.environ['aws_secret_access_key'],
)
# Kafka Consumer 셋팅
consumer = KafkaConsumer(
'video',
bootstrap_servers=['브로커주소:포트번호'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: loads(x.decode('utf-8')),
consumer_timeout_ms=1000
)
while True:
for message in consumer:
# Json형식으로 들어온 메세지 큐 하나씩 전달
s3File = message.value['title']
# Kafka에서 받은 데이터의 이름을 s3 다운로드
s3.download_file(BUCKET_NAME, 'BUCKET_URL', 'LOCAL_URL') # upload_file
filepath = '/' + str(s3File)
video = cv2.VideoCapture(filepath) #'' 사이에 사용할 비디오 파일의 경로 및 이름을 넣어주도록 함
# 디렉토리 생성
try:
if not os.path.exists('/' + filepath[:-4]):
os.makedirs(filepath[:-4])
# 안되면 이걸로 subprocess.call('mkdir' + filepath[:-4])
except OSError:
print('Error: Creating directory. ' + filepath[:-4])
# 동영상파일 이미지로 자르기
num = 1
count = 0
while(video.isOpened()):
try:
ret, image = video.read()
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) # 흑백 사진으로 변경
image = cv2.resize(image, (800, 400)) # 이미지 800*400으로 변경
except:
break;
if(int(video.get(1)) % num == 0): # num의 숫자마다 저장됨
cv2.imwrite('/'+filepath[:-4] + "/" + filepath[:-4] + "_%d.jpg" % count, image)
# print('Saved frame number :', str(int(video.get(1))))
count += 1
video.release()
# spark 전처리 시작
# spark 전처리 끝
# 이미지 압축
# subprocess.call('tar -zcvf' + filepath[:-4] + '*' + '.jpg', shell=True)
# 압축파일, 동영상 삭제
# subprocess.call('rm -rf /' + filepath[:-4] + '.tar.gz, /' + filepath[:-4] + ', /' + filepath, shell=True)결과
- 이미지를 로컬에 저장됨
- 이미지를 한프레임마다 나누어서 저장됨
- 이미지는 사이즈 변경이 가능함 > default 값으로 800*400으로 설정
- 이미지 전처리가 빠르게 될 수 있도록 흑백처리
- 동영상의 이름과 동일한 디렉토리에 저장할 예정
- 이미지 전처리 부분은 다른 조원이 맡음

URL

사진은 남아 추억이 메모는 남아 스펙이 된다