개요
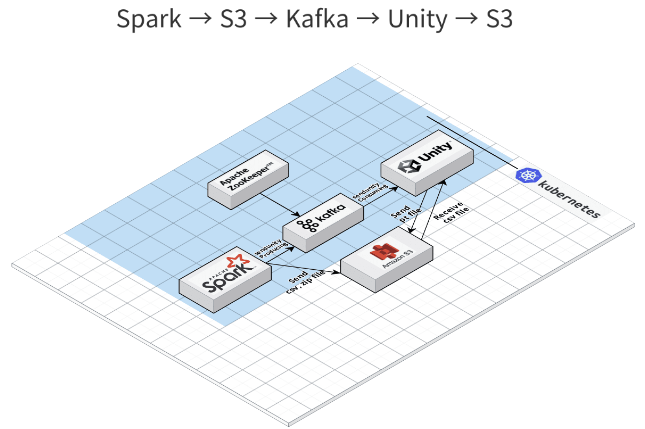
- Spark -> S3 -> Kafka
- 데이터를 전처리하고 나온 csv파일을 S3에 저장
Install
pip install kafka-python
pip install boto3코드
- Spark(Python)
- 이전 코드에서 추가된 내용임
- 이전 코드
# pip install kafka-python
# pip install boto3
# pip install opencv-python
import subprocess
from kafka import KafkaConsumer
from kafka import KafkaProducer
from json import loads
import environ
import boto3
import cv2
import os
BUCKET_NAME = os.environ['bucket_name']
s3 = boto3.client(
service_name='s3',
region_name=os.environ['Region_name'],
aws_access_key_id=os.environ['aws_access_key_id'],
aws_secret_access_key=os.environ['aws_secret_access_key'],
)
# Kafka Producer 셋팅
producer = KafkaProducer(
acks=0,
compression_type='gzip',
bootstrap_servers=[os.environ['Kafka_IP']], # IP주소
value_serializer=lambda v: dumps(v).encode('utf-8'),
)
bucket_name = os.environ['bucket_name'] # 버켓 이름
csvfile = 'csv파일' # 저장할 csv 데이터
csvfilepath = '/' + csvfile # 저장할 파일 이름
# s3에 업로드
s3.upload_file(csvfile, bucket_name, 'csv' + csvfilepath)
producer.send('sendunity', {
'csv': str(num) + '.csv',
})
time.sleep(0.2) # 부하를 막기 위해 0.2초 쉬기
producer.flush() # 데이터 비우기
# 이미지 압축
subprocess.call('tar -zcvf' + filepath[:-4] + '*' + '.jpg', shell=True)
# s3에 이미지 파일 백업
s3.upload_file(zipfile, bucket_name, 'zip' + csvfilepath)
# 압축파일, 동영상 삭제
subprocess.call('rm -rf /' + filepath[:-4] + '.tar.gz, /' + filepath[:-4] + ', /' + filepath, shell=True)
subprocess.call('rm -rf /*.csv', shell=True)결과
-
S3
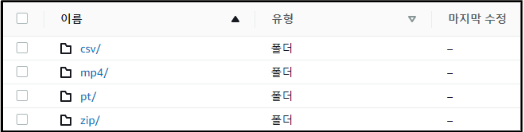
- 각각의 디렉토리가 만들어지고 저장된 것을 확인할 수 있음
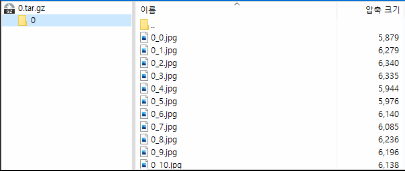
- 압축하여 저장된 이미지 파일

- 각각의 디렉토리가 만들어지고 저장된 것을 확인할 수 있음
-
Broker
- topic 리스트는 sendvideo, sendunity로 2개인 것을 확인할 수 있음
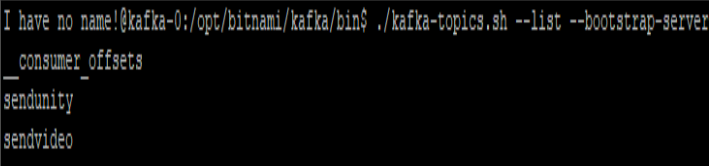
- topic 리스트는 sendvideo, sendunity로 2개인 것을 확인할 수 있음
URL

사진은 남아 추억이 메모는 남아 스펙이 된다