
외국계 기업에서의 IT Service는 최근 Ticket_Based를 원칙으로 하고 있다. 이런 Ticket base를 제공하는 회사가 몇개 있는 것으로 알고 있는데 ServiceNow도 그중 하나이고 가장 유명한 디지털 워크플로우를 제공하고 있다.
온보딩, 오프보딩프로세스, IT 하드웨어/모바일 에셋 Request, OS Installation, Virtual machine, 저작권있는 Software등, 많은 에셋들과 소프트웨어들은 중앙에서 관리되는 경우가 많다.
서비스를 사용하다가 어떤 장애가 발생하는 경우도 흔하고 말이다. 이럴때 보통 Ticket을 올린다고 말한다. 물론 이메일로 자신의 에로사항을 말할수도, 휴대폰으로 말할 수도 있다. 하지만 좋은 서비스를 유지하려면 나는 무조건 Ticket_BASED 시스템을 쓰라고 추천하고 싶다. 이 포스팅은 그를 위함이다.
Servicenow Ticket
1. ⭐ 구성 ⭐

이 티켓하나에는 다양한 Attribute(속성)들이 숨어있다. 나는 여기에 어떤 것이 있는지 알아보고 이런 Attribute 때문이라도 유저들에게 Ticket을 쓰라고 말하고 싶다.
2. 👽 Jupyter Notebook
이 과정을 위해서 나는 Jupyter Notebook 이라는 것을 구동해 간단한 NLP를 진행할 예정이다.
Anaconda3 에서
이렇게 Jupyter notebook을 키면
이런식으로 Jupyter 환경이 구성된다.
이곳에서 Python3를 작동시켜서 간단하게 Ticket 칼럼 분석을 해보겠다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
%matplotlib inline
raw_data = pd.read_excel('incident.xlsx')<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2870 entries, 0 to 2869
Data columns (total 91 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Number 2870 non-null object
1 Active 2870 non-null bool
2 Activity due 0 non-null float64
3 Additional assignee list 0 non-null float64
.
.
.
32 Description 2870 non-null object
33 Dispatch SLA breached 2870 non-null bool
34 Duration 2870 non-null int64
.
.
82 Urgency 2870 non-null object
83 User Application Spec Info 0 non-null float64
84 User Category 1150 non-null object
85 User Impact 1123 non-null object
86 User Subcategory 697 non-null object
87 User Subsubcategory 501 non-null object
90 Short Description (automatically translated) 2870 non-null object
dtypes: bool(8), datetime64[ns](11), float64(15), int64(6), object(51)
memory usage: 1.8+ MB무려 90개가 되는 칼럼이 있다.. ;; 유저가 티켓하나를 올리면 이 90개의 정보가 생성되는 것이다. 여기에는 당연히 미리 고정되어서 나오는 고정값도 존재하고 (Organization, User name, Area..) 선택값도 존재하고 (Category, Subcategory, subsub, VIP Support) 종속값도 존재하지만 (Duration, SLA breached) 내가 주목하고 싶은건
3. 💙 비정형적 데이터
바로 비정형화된 데이터이다.

이건 I Love You를 나타낸 것인데 이런 비정형적 데이터는 다루기 힘든 언어중에 하나이다.
너를 사랑해.
너를 죽이고 싶을정도로 사랑해.
사랑하지~(영혼없음)
같은 말이라도 너무 말의 쓰임새가 다양하기에 이런 경우에는 군집화과정이 필요하다.
특히나 여기는 외국계라 티켓을 올릴때 한국어로 올리기도 하고 영어로 올리기도 하고 가지각색이다. 이런 비정형적 언어를 처리하기 위해선 분류 및 전처리가 필수적이다. 나는 이 티켓에서 Description 부분을 전처리를 진행하였다.
Python3 코드는 생략하겠다. (영업기밀.. ㅎ)
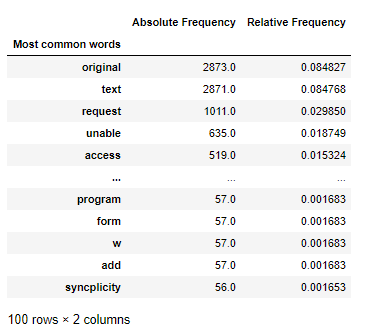
이런 식으로 Description에 많이 나오는 단어와 상대적 빈도수를 체크한 후
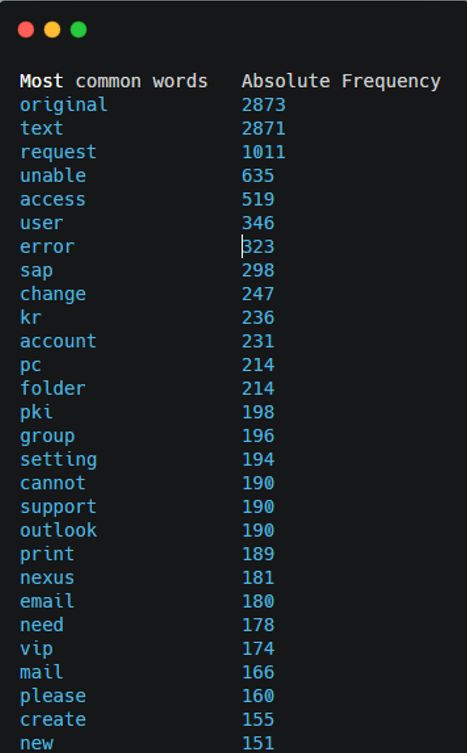
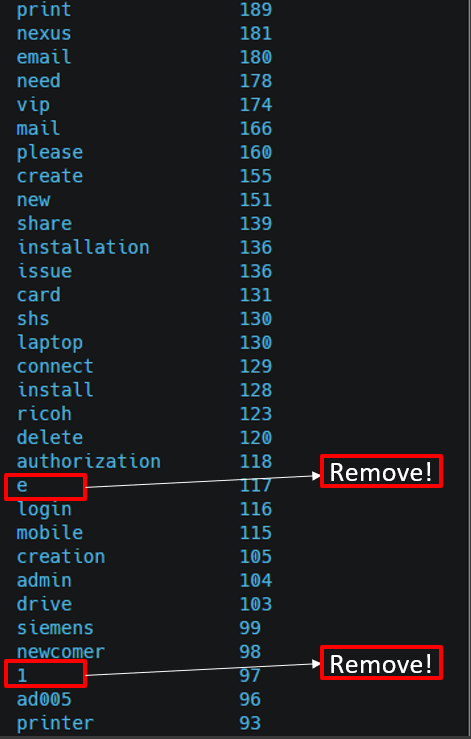
이렇게 분류 한 뒤 쓸모없는 1글자 정보나 이런 부분은 제거해버린다.
물론 이 과정 전에 전처리를 할수도 있다.
4. 군집화
그 이후 군집화 과정을 진행하고 유저들의 많은 이슈를 분기별, 주기별, 월별 등으로 분류 및 강조할수가 있다.

내가 파악한걸로는 이러한 정보들이 이슈화 되고 있었다.
이런 간단한 데이터 분석으로도 유의미한 결과와 비즈니스를 이끌어낼 수 있다... !!

그럼 이만 포스팅 마침...
