👌데이터 살펴보기 앞서서
파이썬에는 여러가지 사투리가 있다. 모듈?
- pytorch
- tensorflow
- keras
- sckiti-run
이번 개 고양이 데이터 분석을 하면서 3가지의 사투리를 접하게 되었다.
- tensorflow
- keras
- sckiti-run
👌1. 우선 필요한 패키지를 설치 합니다.
- keras는 백엔드로 tensorflow를 사용하기 때문에, tensorflow까지 자동으로 설치가 됩니다.
※ 학습데이터를 데이터프레임(데이터의 구조가 엑셀같은 표 형태로 구성)형태로 변환하고 연산하기 위한 pandas가 설치 되어야 하고,
※ 배열 연산을 위한 numpy, 이미지 처리를 위한 image 패키지, 그리고 매트릭스를 그래프로 나타내기 위한 matplotlib,
※ 마지막으로 수치연산을 위한 패키지인 scikit-learn을 설치 합니다.
import sys
!{sys.executable}-m pip install keras pandas numpy image matplotlib sckitit-learn👌2. warning 출력 off
주피터 노트북 셀 실행시 주황색으로 warning이 많이 뜨는데, 보기 싫으니 출력하지 말라고 합니다.
import warnings
warnings.filterwarnings("ignore")👌3. 필요한 패키지 import
본 알고리즘 실행에 필요한 패키지들을 import하고, 데이터 잘 저장 되었는지 확인한다.
import numpy as np
import pandas as pd
from tensorflow.keras.utils import load_img
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import random
import os
print(os.listdir("/content/drive/MyDrive/과제2/cat_dog"))👌4. 글로벌 변수를 선언 합니다.
앞서 압축 풀어놓은 이미지의 가로크기, 세로크기, 사이즈(128x128)와
채널(칼라 사잔이므로R, G, B세개)을 정의 해 놓습니다.
나중에 convolution연산 시 channel정보가 필요하므로, 미리 정의해 놓습니다.
FAST_RUN = False
IMAGE_WIDTH=128
IMAGE_HEIGHT=128
IMAGE_SIZE = (IMAGE_WIDTH, IMAGE_HEIGHT)
IMAGE_CHANNELS=3 👌5. 파일명과 정답 설정
압축 푼 디렉토리 중, train디렉토리에는 dogxxx.jpg, catxxx.jpg등, 개와 고양이를 파일 이름으로 구분짓도록
파일이 저장되어 있습니다.
이를 구분하여 개에 해당되는 파일명과 정답('개', 1)을, 그리고 고양이에 해당되는 파일명과 정답('고양이', 0)을 dataframe에 저장해 놓습니다.
filenames = os.listdir("/content/drive/MyDrive/과제2/cat_dog")
categories = []
for filename in filenames:
category = filename.split('.')[0]
if category == "dog":
categories.append(1)
else:
categories.append(0)
df= pd.DataFrame({"filename":filenames,"category":categories}) 👌6. 저장이 잘 되어 있는지 확인해 봅니다.
데이터 셋의 제일 앞 5개와 제일 뒤 5개를 샘플링 해서 살펴봅니다.
df.head()
df.tail()7. 데이터 balance확인.
분류 문제이 있어서, 각 category별 데이터가 고루 분포가 되어 있어야 학습이 잘 됩니다.
즉, 데이터 내에 개와 고양이가 균일하게 분포가 되어 있는지 확인을 합니다.
보니까, 고르가 잘 분포가 되어 있는거 같네요.
df["category"].value_counts().plot.bar()8. Sample데이터 확인
데이터 디렉토리중 임의로 하나를 뽑아서 확인 합니다.
sample = random.choice(filenames)
image = load_img(""+sample)
plt.imshow(image)- 신경망 모델 구성
모델 구성은...기본적인 룰이 있긴 하지만, 여러번 구조를 바꿔가며,
잘 맞추는 모델이 나올때까지 구조를 변경시키는 것 입니다.
from kersas.models import Sequential
from keras.layer import Con2D, MaxPooling2D, Deoput, Flatten, Dense, Activarion, SatchNormalization
model = Sequential()
model.add (con2D(32,(3,3), activation = "relu", input_shape = (IMAFE_WIDTH,IMAGE_HEIGHT,IMAGE_CHANNELS)))
model.add(BatchNormalization())
model.add(MaxPoolinf2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Con2D(64,(3,3), activation="relu"))
model.add(Batch_normalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128,(3,3), activation="relu"))
model.add(BatshNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512,activation="relu"))
model.add(BatshNormalization())
model.add(Dropout(0.5))
model.add(Dense(2,activation="softmax"))
model. compile(loss="cetegrorical_crossentropy", optimizer= "rmsprop", metrics=["accuacy"])
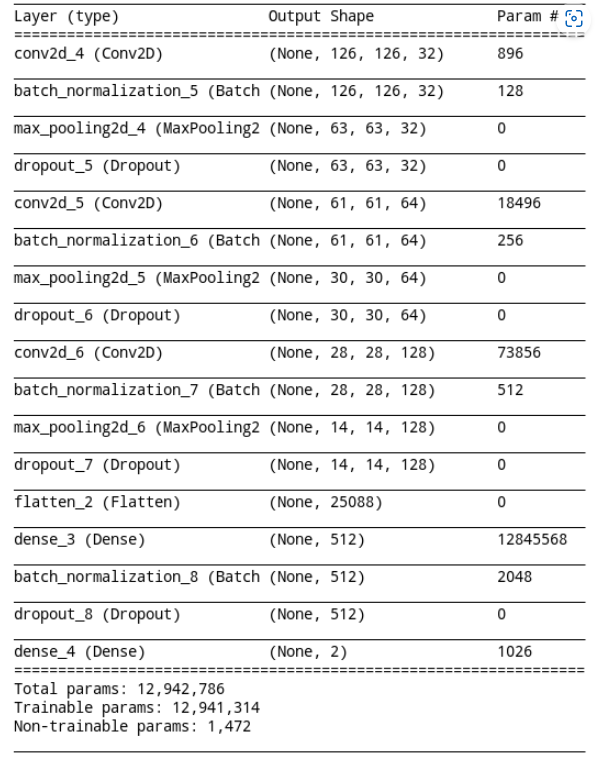
model.summary()10. 신경망 구조를 살펴봅니다.
아래와 같은 구조로 생겼는데, 약 천이백만개의 파라미트를 학습해야 하는군요.
학습데이터(개, 고양이사진)이 제일 위로 들어와서 제일 아래로 나가는 구조 입니다.
제일 처음 conv2d layer의 shape를 보면 (None, 126, 126, 32) 이렇게 되어 있는데,
가운데 126, 126 숫자 두개가 바로 입력되는 개, 고양이 사진의 가로, 세로 크기 입니다.
제일 아래 Dense Layer에 보면 shape에 숫자 2가 있는데, 이게 바로 개냐 고양이냐 하는 두가지 케이스가있기 때문에 shape가 2로 된 것 입니다.
- 콜백 정의
우선 조기종료(Early Stopping)와 학습율 하향조정을 위해 두 콜백 클래스를 import합니다
from keras.callbacks import EarlyStopping, ReduceLROnPlateau12. Early Stopping 정의
Early Stopping이 뭐냐 하면...
전체 개, 고양이 데이터가지고 조금씩 나눠서 여러차례 학습을 하는데,
잘 학습되다가 어느시점 지나면 정확도가 오히려 떨어지는 case가 발생합니다.
이때 10번까지 참다가, 10번 지나서도 계속 떨어지면 고만 학습하고 그 결과를 내라는 말 입니다.
earlystop = EarlyStopping(patience=10)13. Learning Rate 조정 정의
이 클래스는 학습하는 동안 정확도를 잘 감시하고 있다가 어느 기준이 되면 학습율을 조정해주는 클래스 입니다.
learning_rate_reduction = ReduceLROnPlateau(monitor= "val_acc",patience=2, verbose=q, factor=0.5,min_lr=0.00001 )14. callback 설정
앞서 정의한 두 콜백 클래스를 callbacks에 담아 놓습니다.
callbacks = [earlystop, learning_rate_reduction]15. 개, 고양이를 string으로 변환
아까 파일이름과 개인지 고양이 인지를 저장해놓은 dataframe에서
category를 개인 경우 1로, 고양이 인 경우 0으로 변경해 줍니다.
나중에 one-hot 인코딩으로 변환을 하기 위해서 입니다.
df["category"]= df["category"].replace({0:"cat", 1:"dog"})16. train-validation 데이터 분리
이제, train데이터중 20%를 쪼개서 학습중 파라미터 검증을 위한 validation셋을 마련해 놓습니다.
train_df, validate_df = train_test_split(df, test_size =0.20, random_state= 42 )
train_df = train_df,reset_index(drop= True)
validate_df = validate_df.reset_index(drop=True)17. train데이터의 분포 확인
train데이터에 존재하는 개와 고양이 수를 그래프로 그려 봅니다.
train_df["category"].value_counts().plot.bar()18. validation 분포 확인
아까 잘라낸 20%의 데이터에도 개와 고양이의 분포를 확인 합니다.
validate_df["category"].value_counts().plot.bar()19. 학습, 검증데이터의 확인
학습데이터 및 validation의 형상을 확인하고,
한번에 학습할 batch의 size를 설정 합니다.
total_train= train_df.shape[0]
total_validate = validate_df.shape[0]
batch_size=1020. 학습데이터 뻥튀기
아시다 시피 학습은 데이터가 많을수록 잘 될 가능성이 큽니다.
학습데이터를 augmentation해서 수를 늘립니다.
부풀리기는 이미지를 약간 회전시키거나, 줌을 하거나, 상하/좌우 반전을 시키는 방법으로 늘립니다.
train_datagen = ImageDataGenerator(rotation_rang = 15, rescale=1./255),shear_range=0.1, zoom_range=0.2,horizontal_flip=True, windth_shift_range=0.1, height_shift_range=0.1)
train_generator = train_datagen.flow_from_dataframe(train_df,"",x_col="fillename", y_col= "category",target_size=IMAGE_SIZE,class_mode="categorical",batch_size=batch_size)21. Validation데이터 뻥튀기
validation이미지도 마찬가지로 작업을 해줍니다.
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(validation_df,"",x_col="fillename", y_col= "category",target_size=IMAGE_SIZE,class_mode="categorical",batch_size=batch_size)22. 샘플 확인
위에 데이터 부풀리기가 잘 되었는지 확인하기 위한 부풀리기를 수행합니다.
example_df = train_df.sample(n=1).reset_index(drop=True)
example_generator = train_datagen.flow_from_dataframe(example_df,"",x_col="fillename", y_col= "category",target_size=IMAGE_SIZE,class_mode="categorical")23. 이미지 확인
작업된 이미지를 확인 해 봅니다.
자세히 보면 같은 개인데, 좌우 반전이나 줌이 되어 있는걸 볼 수 있죠.
plt.figure(figsize=(12,12))
for i in range(0.15):
plt.subplot(5,3,i+1)
for X_batch, Y-batch in ezample_generator:
image = X_batch[0]
plt.imshow(image)
break
plt.tight_layout()
pit.show() 24. 학습시작
25. 모델 저장
학습이 끝나면, 제일먼저 할일은 모델을 저장하는 것입니다.
모델을 저장해 놓으면, 다음에 24번의 오래오래 걸리는 학습 단계를 생략할 수 있습니다.
26. 학습 내용 확인
이제 그동안 학습시킨 내용을 확인해봐야겠죠.
train loss, validation loss와 train accuracy, validation accuracy 그래프를 그려봅니다.
27. 그래프 확인
아주 예쁘게 잘 확인 된거 같습니다.
파란색 그래프는 학습할때의 그래프고, 빨간색은 validation 그래프 입니다
28. Test
이제 학습된 모델을 가지고 test데이터를 한번 맞춰봅시다.
test1 디렉토리에 있는 개와 고양이 사진으로 한번 평가를 해 봅니다.
29. 평가 데이터 준비
테스트 데이터와 validation데이터와 마찬가지로 데이터를 준비 합니다
-
모델 예측
아까 학습한 모델로, 위에서 생성한 test 셋을 넣어 봅니다. -
평가 생성
prediction의 결과는 각 record별, 개일확율 얼마, 고양이일 확율 얼마 이런식으로 결과가 담겨져 있습니다.
편의성과 정확도 검증을 위해 개와 고양이일 확률중 보다 큰값에 해당하는 레이블을 선택해서 값을 치환합니다.
(개일 확율 0.73, 고양이일 확률 0.27이면, '개'의 label인 dog을 넣습니다.) -
레이블 변환
평가를 위해서 dog, cat 이렇게 들어가 있던 데이터를 다시 1, 0으로 변경합니다.

-
정답비율 확인
개와 고양이를 어느정도 비율로 예측했는지 한번 살펴 봅니다

-
정답 확인
예측한 결과를 눈으로 확인해 봅니다.
https://github.com/semi0612/ML_study/blob/main/Kaggle_Chest_Xray_Abnormalities_Detection/README.md -> 우리 내용 정리한거
오류)
unindent does not match any outer indentation level
:들여쓰기가 외부 들여쓰기 수준과 일치하지 않습니다.
-> 들여쓰기 문제
