import numpy as np #다차원 배열과 행렬 연산을 지원하며, 이러한 배열을 다루는 다양한 함수와 도구를 제공
import pandas as pdcrime_raw_data = pd.read_csv('../ds_study/data/02. crime_analyse_station_bygu_normal.csv', thousands=',', encoding='utf-8')crime = ['강간,추행','강도','살인', '절도','폭력']
crime_analyse_station_bygu_normal = crime_analyse_station_bygu[crime] / crime_analyse_station_bygu[crime].max()crime_rate = ['강간,추행검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
crime_analyse_station_bygu_normal[crime_rate] = crime_analyse_station_bygu[crime_rate]crime_analyse_station_bygu_normal.to_csv('../data/02. crime_analyse_station_bygu_normal.csv', sep=',', encoding='utf-8')
result_CCTV = pd.read_csv('../data/01. Seoul_CCTV.csv', index_col='구분', encoding='euc-kr')crime_analyse_station_bygu_normal[['cctv']] = result_CCTV[['2022년']]result_pop = pd.read_csv('../data/01. Seoul_Population.csv', index_col='자치구', encoding="euc-kr")crime_analyse_station_bygu_normal[['인구수']] = result_pop[['합계']]
crime = ['강간,추행','강도','살인','절도','폭력']
crime_analyse_station_bygu_normal['5대 범죄 평균 발생 건수'] = np.mean(crime_analyse_station_bygu_normal[crime], axis=1)crime_analyse_station_bygu_normal.to_csv('../data/02. crime_analyse_station_bygu_normal.csv', sep=',', encoding='utf-8')crime_analyse_station_bygu_normal = pd.read_csv('../ds_study/data/02. crime_analyse_station_bygu_normal.csv', index_col='구별', encoding="utf-8")import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc #Matplotlib 라이브러리를 사용하여 그래프를 그릴 때 한글 폰트를 제대로 표시하기 위한 설정
plt.rcParams['axes.unicode_minus'] = False
get_ipython().run_line_magic('matplotlib', 'inline')
rc('font', family = 'Malgun Gothic')# 강도, 살인, 폭력에 대한 상관관계 확인
# 강도와 폭력은 상관관계가 있다.
sns.pairplot(data=crime_analyse_station_bygu_normal, vars=['살인', '강도', '폭력'], kind='reg', height=3)
crime_analyse_station_bygu_normal.head()
crime_analyse_station_bygu_normal['인구수'] = crime_analyse_station_bygu_normal['인구수'].str.replace(',', '').astype(float)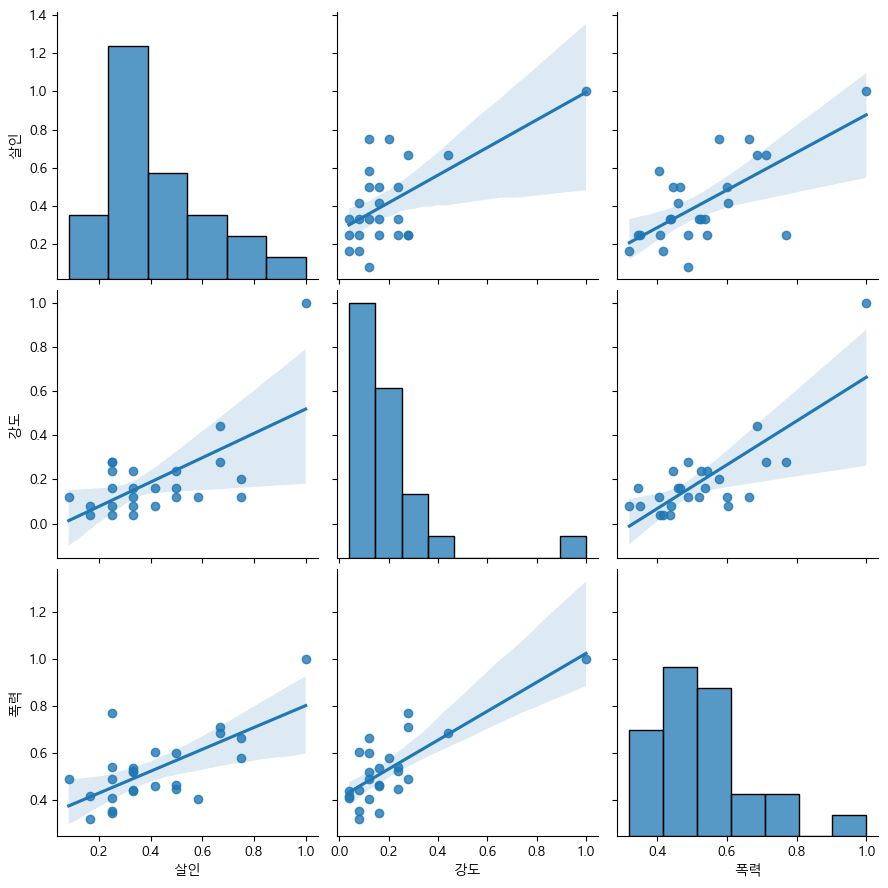
sns.set_style("darkgrid")
def pop_cctv_crime(x1,x2,y1,y2):
sns.pairplot(
data=crime_analyse_station_bygu_normal,
x_vars=[x1,x2],
y_vars=[y1,y2],
kind = 'reg',
height = 4
)
plt.show()
pop_cctv_crime('인구수', 'cctv','살인', '절도' )
# 인구수, cctv와 살인, 절도의 상관관계 분석
# 인구수가 많을 수록 절도가 많이 일어난다
# cctv가 많을수록 절도는 적게 일어난다.
#
# 인구가 많은수는 안전하지않은가?
# cctv가 많은 지역은 안전한가?
# 아웃라이어를 제거하면 어떤결과가 나오는가?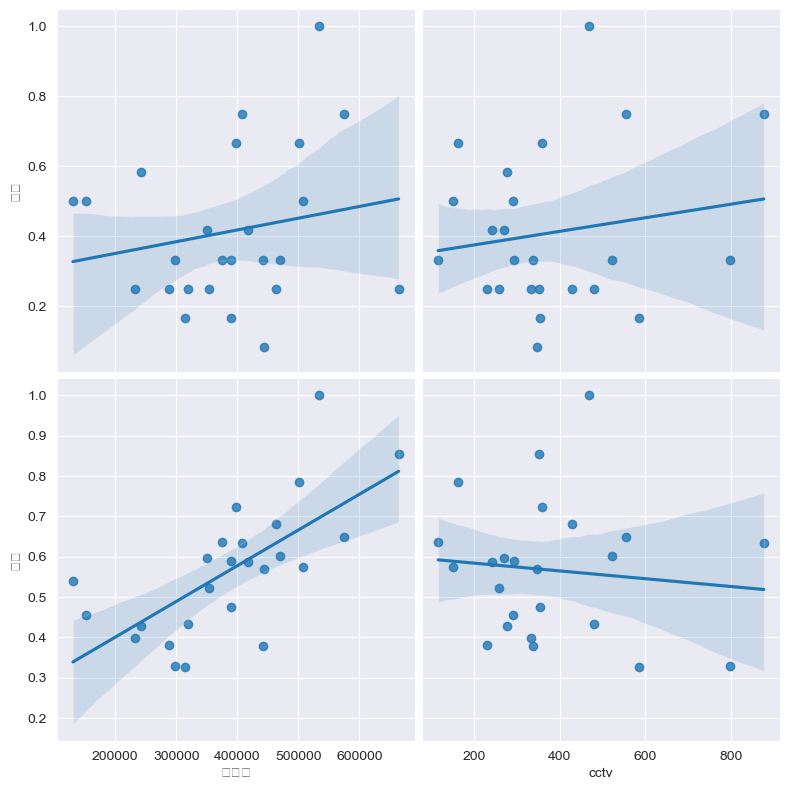
pop_cctv_crime('인구수', 'cctv','살인검거율', '폭력검거율' )
# 아웃라이어 제거 하고 봐야될거같다
# 그러나, cctv가 많을수록 폭력검거율은 높아지는 경향이 있다.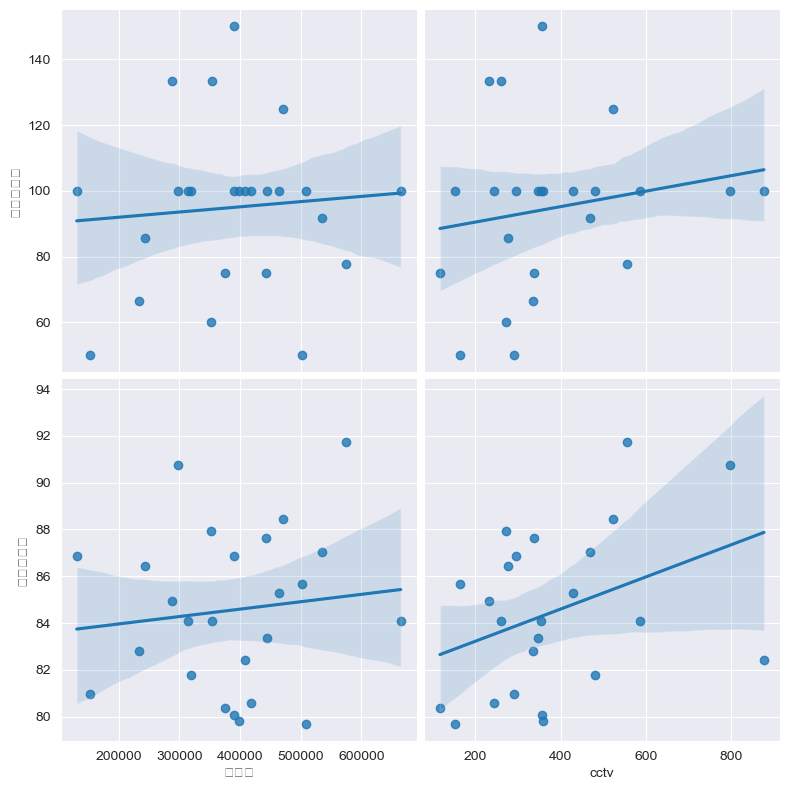
pop_cctv_crime('인구수', 'cctv','절도검거율', '강도검거율' )
# 아웃라이어 빼봐야할거같다. 그런데 빼면 더 상관이 없을거같은데...
#일단 지금은 cctv가 많을수록 절도검거율이 높다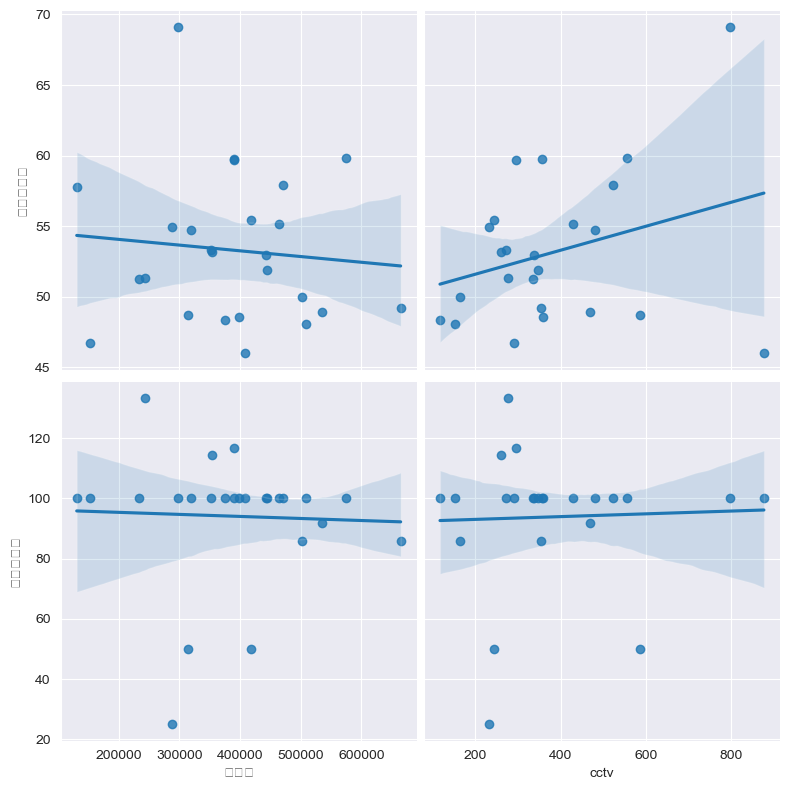
col = ["강간,추행검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_analyse_station_bygu_normal['검거'] = np.mean(crime_analyse_station_bygu_normal[col], axis=1)
crime_analyse_station_bygu_normal.head(1)def crime_heatmap(crime_rate):
crime_rate = ["강간,추행검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율", "5대 범죄 평균 발생 건수"]
crime_analyse_station_bygu_normal_sort = crime_analyse_station_bygu_normal.sort_values(by = '5대 범죄 평균 발생 건수', ascending=False)
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_analyse_station_bygu_normal_sort[crime_rate],
annot = True,
fmt = 'f',
linewidths=0.5,
cmap='RdPu'
)
plt.title('범죄 검거율 비율(정규화된 검가의 합으로 정렬)')
plt.show()
crime_heatmap(crime_rate)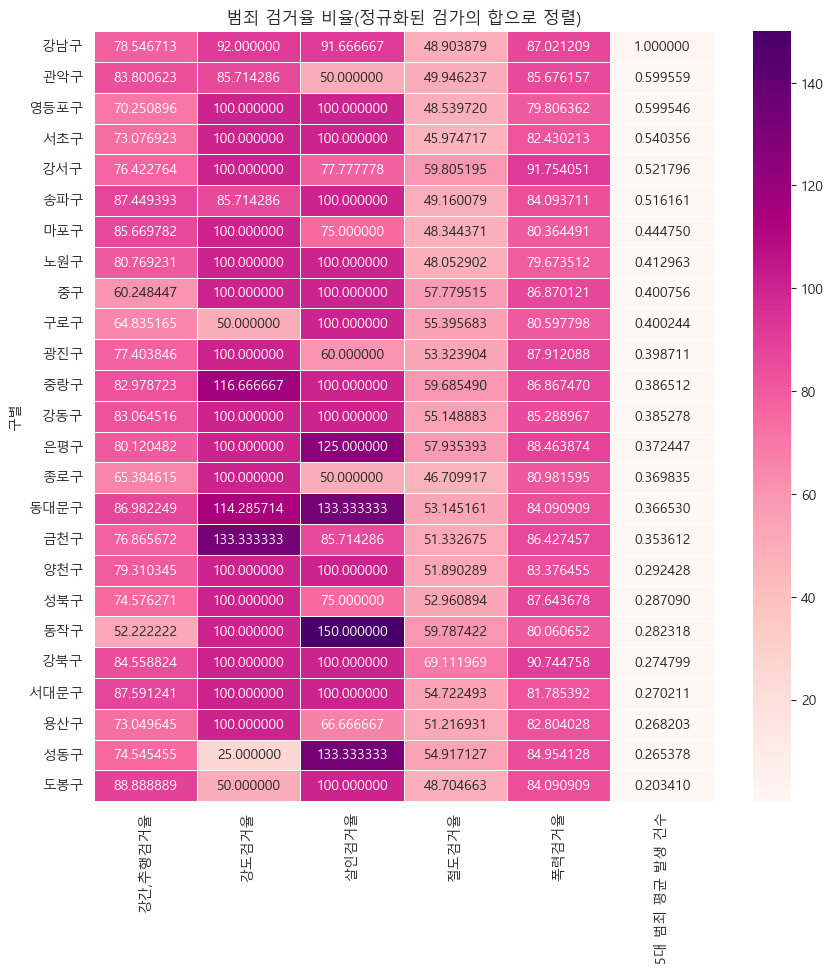
import pandas as pd
import json
conda install -c conda-forge folium
import folium
# folium 지도 시각화
# 지도 시각화 도구는 많지만
# 현재 사용의 편의성이나 활발한 기능 개선 등으로 Folium 만족도가 높은편
# folium은 기본적으로 크롬에서 동작이 좋음
# 근본적으로는 위도 경도를 알려주면 된다.
# html로 저장도 가능map = folium.Map(location=[45.5236, -122.6750])
map.save('../ds_study/data/maptest.html')
folium.Map(location=[45.5236, -122.6750], tiles='CartoDB', zoom_start=13)
# tiles=지도의 타일셋을 선택 ('OpenStreetMap', 'Stamen Toner')
# zoom_start=초기 지도 확대/축소 레벨 0~18test_map = folium.Map(location=[45.5236, -122.6750],zoom_start=12, tiles='Stamen Toner')
folium.Marker([45.5239, -122.6750], popup='<i>test1</i>').add_to(test_map)
folium.Marker([45.6239, -122.6750], popup='<b>test2</b>').add_to(test_map)
#<i> 태그는 이탤릭체(italic)
#<b> 태그는 굵은체(bold)
# HTML 태그
test_map
pip install fontawesome
test_map = folium.Map(location=[45.5236, -122.6750],zoom_start=12, tiles='Stamen Toner')
folium.Marker(
location=[45.5236, -122.6750],
popup='테스트',
icon = folium.Icon(icon='cloud')
).add_to(test_map)
test_map
folium.Circle(
radius = 1000,
location = [45.5236, -122.6750],
popup = 'test circle',
fill = True,
color = 'yellow',
fill_color = 'crimson',
tooltip = 'here!' # 마커에 마우스를 올리면 표시
).add_to(test_map)
test_map#클릭했을떄 위도 경도 정보 반환
test_map.add_child(folium.LatLngPopup())
test_map
test_map.add_child(folium.ClickForMarker(popup='Click'))#지도 선택시 마커 생성
import json
state_data = pd.read_csv('../ds_study/data/02. US_Unemployment_Oct2012.csv')
test_map = folium.Map(location=[48, -102], zoom_start=3)
test_map.choropleth(
geo_data='../ds_study/data/02. us-states.json',
data = state_data,
columns = ['State', 'Unemployment'], #코로플레스 맵에서 사용할 데이터의 열 이름을 지정합니다. ['State', 'Unemployment']
key_on = 'feature.id',#지리 데이터와 데이터를 연결하는 키(속성)를 지정합니다. 'feature.id'는 지리 데이터의 특성 ID를 사용
fill_color = 'YlGn',#'YlGn'은 노란색과 초록색
fill_opacity = 0.7,#영역의 채우기 투명도
line_opacity = 0.2,#영역 경계의 투명도
legend_name = 'unemployment rate (%)'
)
test_map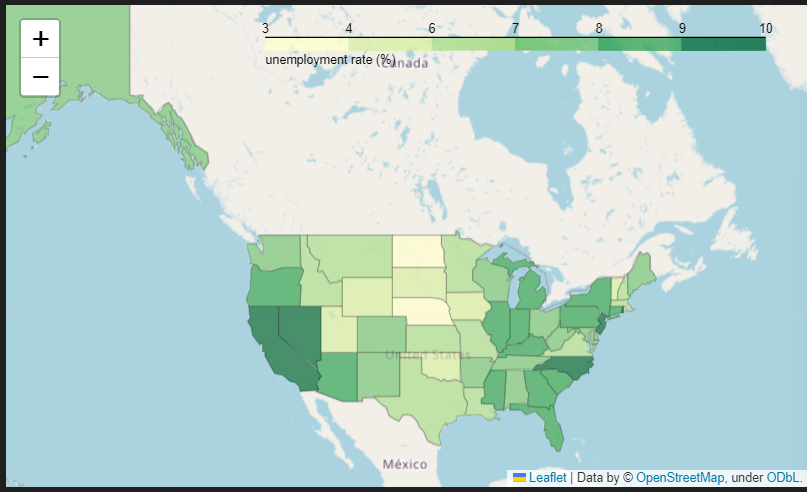
import json
crime_analyse_station_bygu_normal.head()
geo_path = '../ds_study/data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
geo_path
geo_str
pop_crime = crime_analyse_station_bygu_normal['5대 범죄 평균 발생 건수'] / crime_analyse_station_bygu_normal['인구수']crime_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
crime_map.choropleth(
geo_data = geo_str,
data = pop_crime,
colums = [crime_analyse_station_bygu_normal.index, pop_crime],
fill_color = 'PuRd',
key_on = 'feature.id',
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = '인구수 대비 범죄 발생 건수(정규화)'
)
crime_map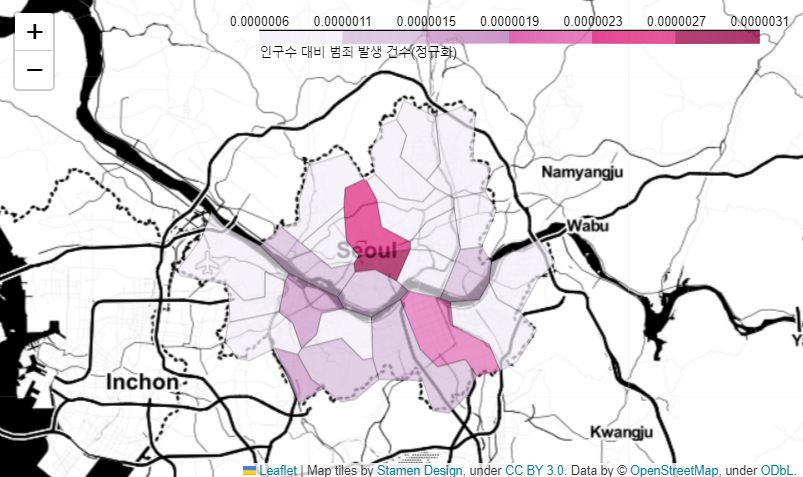
crime_analyse_station = pd.read_csv(
'../ds_study/data/02. crime_in_Seoul_1st.csv', index_col = 0, encoding = 'utf-8'
)catch = ['강간검거', '살인검거', '절도검거', '폭력검거']
catch_rate = crime_analyse_station[catch] / crime_analyse_station[catch].max()
crime_analyse_station['평균 검거율'] = np.mean(catch_rate, axis = 1)crime_catch_map = folium.Map(location=[37.5502, 126.982], zoom_start=11,)
for idx, rows in crime_analyse_station.iterrows():
folium.CircleMarker(
[rows['lat'], rows['lng']],
radius = rows['평균 검거율'] *50,
popup = rows['구분']+':'+'%.2f'%rows['평균 검거율'],
color = 'yellow',
fill = True,
fill_color = 'Yellow'
).add_to(crime_catch_map)
crime_catch_map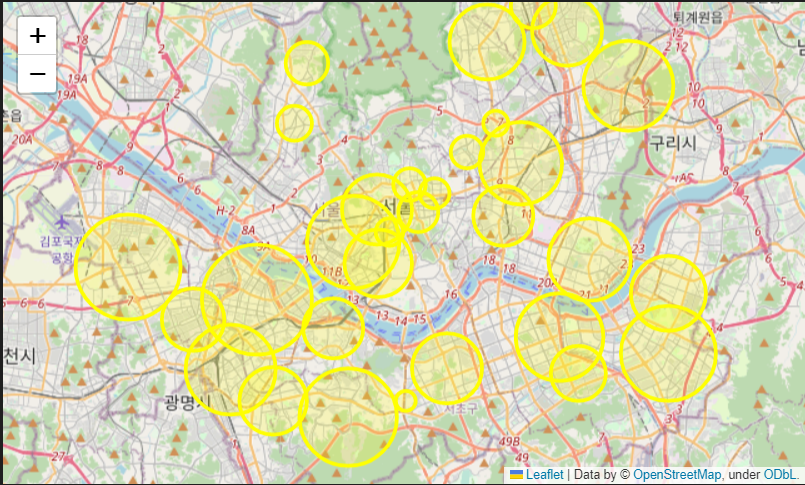
crime_loc = pd.read_csv(
'../ds_study/data/02. crime_in_Seoul_location.csv', thousands=',', encoding= 'euc-kr'
)crime_loc['범죄명'].unique()
crime_loc['장소'].unique()
crime_loc = crime_loc.pivot_table(
crime_loc, index=['장소'], columns = ['범죄명'], aggfunc = [np.sum]
)
crime_loc.head()
crime_loc.columns = crime_loc.columns.droplevel([0,1])crime = ['살인', '강도', '강간.추행', '절도', '폭력']
crime_loc_normalize = crime_loc[crime]/crime_loc[crime].max()
crime_loc_normalize['종합'] = np.mean(crime_loc_normalize, axis = 1)
crime_loc_normalize_sort = crime_loc_normalize.sort_values(by='종합', ascending = False)
def crime_heatmap():
plt.figure(figsize=(10,10))
sns.heatmap(crime_loc_normalize_sort, annot = True, fmt = 'f', linewidth = 0.5, cmap = 'RdPu')
plt.title('범죄 발생 장소')
plt.show()
crime_heatmap()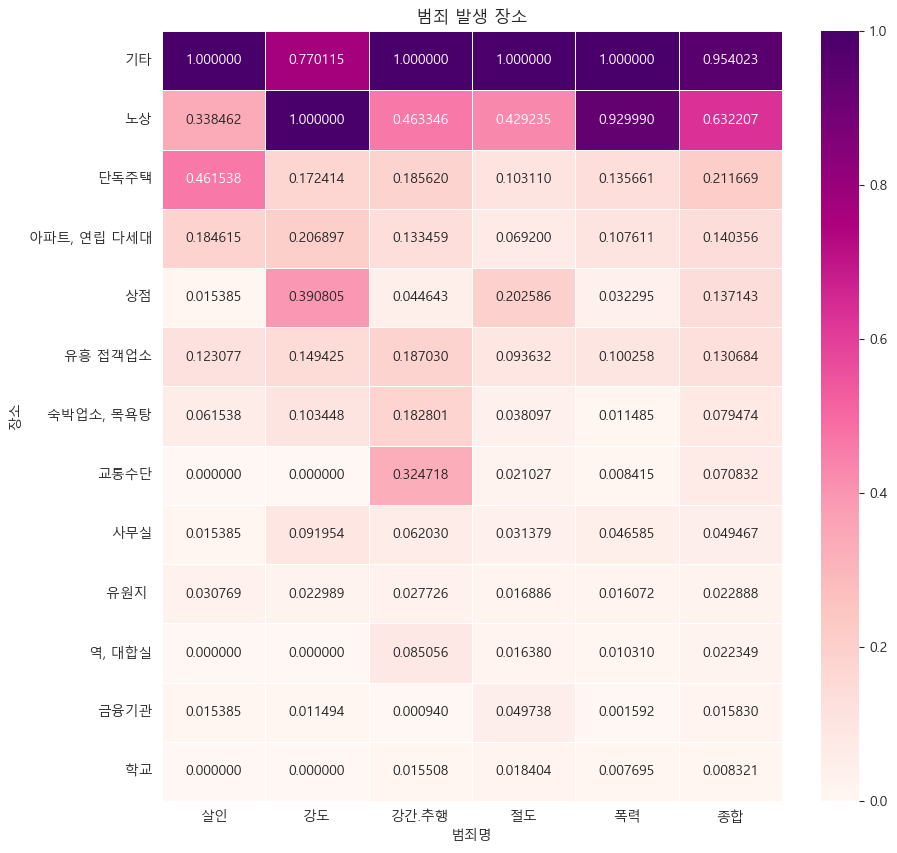
수야는 코린이에서 더 나아갈거야