from bs4 import BeautifulSouppage = open('../data/03. test_first.html', 'r').read() # open with read(r) or write(w)
soup = BeautifulSoup(page, 'html.parser') #html.parser : Beautiful Soup의 html을 읽는 엔진 중 하나. 그 외로는 lxml
print(soup.prettify()) #prettify : html 출력을 이쁘게 만들어줌 이쁘게?
soup.body # 파싱된 HTML 문서에서 <body> 요소 도출
# <body> 요소는 웹 페이지에 실제로 표시되는 내용
soup.find('p') #<body> 요소의 하위 요소, 즉 <div>, <p>, <a>, <ul>
# 첫 번째로 일치하는 요소를 찾아 반환
soup.find_all(id = 'pw-link') #모든 요소를 찾아 리스트로 반환 #태그, id 가능
# html 내에서 속성 id는 딱 한번만 나타난다.
#그래서 find_all 함수는 의미가 없지만, 검색 결과를 listㄹ 받고싶으면 id라도 find all 함수를 사용하면 된다.#<p> 요소를 찾아 각 요소마다 반복하면서 출력
for each_tag in soup.find_all('p'): #for 루프를 사용하여 each_tag라는 변수를 통해 리스트의 각 요소를 반복하면서 접근
print('-------------')
print(each_tag.get_text())
links = soup.find_all('a') # <a> 요소는 하이퍼링크를 나타내는 요소
links #PinkWink는 <a> 요소의 시작 태그와 종료 태그 사이에 있는 텍스트
# 텍스트는 사용자에게 보여지는 링크의 텍스트로서, PinkWink라는 내용이 텍스트로 표시# 외부로 연결되는 링크의 주소를 알아내는 방법
for each in links :
href = each['href']
text = each.string #요소 내의 텍스트를 가져와서 text 변수에 할당
print(text + '->'+href)BeautifulSoup 예제 1-1 - 네이버 금융
from urllib.request import urlopen
url = 'https://finance.naver.com/marketindex/'
page = urlopen(url)
page.status #200이 나오면 정상적으로 주고 받았다는 뜻 # HTTP 응답 상태 코드를 반환
soup = BeautifulSoup(page, 'html.parser', from_encoding='euc-kr')
print(soup.prettify())print(soup.prettify())
import requests
from bs4 import BeautifulSoupfor n in len(soup.find_all('span', 'blind')):
soup.find_all('span', 'blind')[n].string + \
':'+soup.find_all('span', 'value')[n].string + \
soup.find_all('span', 'blind')[n+1].string+' '+\
soup.find_all('span', 'change')[n].string+\
soup.find_all('span', 'blind')[n+1].stringre = len(soup.find_all('span', 'blind'))
re+re
exchangelist = soup.select('#exchangeList > li') #id 안에서 가져오는거면 #, class 에서 가져오면 .
exchangelist
title = exchangelist[0].select_one('.h_lst').text
exchange = exchangelist[0].select_one('.value').text
change = exchangelist[0].select_one('.change').text
updown = exchangelist[0].select_one('div.head_info.point_dn > .blind')
print(updown)# link
find = soup.find_all('ul', id='exchangeList')
find[0].find_all('span','blind')
import pandas as pd
from urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupfood_list = pd.read_csv('../data/03. best_sandwiches_list_chicago.csv', index_col=0)
food_list.head()req = Request(food_list['URL'][0], headers={'User-Agent': "Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')
price_tmp = soup_tmp.find('p','addy').get_text()
price_tmpimport re
price_tmp = re.split(',.', price_tmp)[0]
price_tmp
price= re.search('\$\d+\.(\d+)?', price_tmp).group()
#$와 숫자로 시작하다가 .을 만나면 그 뒤에 숫자가 있을 수도 있고 아닐 수 도 있다.
price_tmp[len(price)+ 2:]
#가격이 끝나는 위치부터 그 뒤로는 주소로 생각
#+2 = 띄어쓰기#일반적으로 사용되는 몇 가지 정규 표현식 문자 클래스는 다음과 같습니다:
\d : 0부터 9까지의 숫자에 매칭합니다.
\w : 숫자, 알파벳 대문자, 알파벳 소문자, 밑줄(_)에 매칭합니다.
\s : 공백 문자에 매칭합니다.
\b : 단어 경계에 매칭합니다
\ (역슬래시 자체를 매칭하기 위해)
. (임의의 한 문자를 매칭하기 위해)
'*' (앞의 패턴이 0회 이상 반복되는 것을 매칭하기 위해)
'+' (앞의 패턴이 1회 이상 반복되는 것을 매칭하기 위해)
? (앞의 패턴이 0회 또는 1회 나타나는 것을 매칭하기 위해)
(, ) (그룹화를 위해)
[, ] (문자 클래스를 표현하기 위해)
{, } (패턴의 반복 횟수를 지정하기 위해)
| (두 개의 패턴 중 하나를 매칭하기 위해)
^ (문자열의 시작을 매칭하기 위해)
$ (문자열의 끝을 매칭하기 위해)
pip install tqdm
from tqdm import tqdmprices = []
address = []
for n in food_list.index:
req = Request(food_list['URL'][n], headers={'User-Agent': "Chrome"})
html = urlopen(req).read()
soup_tmp=BeautifulSoup(html, 'lxml') # lxml'은 매우 빠르고 유연한 파서로 알려져 있습니다. 그러나 'lxml' 외에도 'html.parser' 등의 다른 파서를 선택할 수도 있습니다. data = soup_tmp.find('p','addy').get_text()
tmp = re.split('.,', data)[0]
price = re.search('\$+\d+\.(\d+)?', tmp).group()
prices.append(price)
address.append(tmp[len(price)+2:])
print(n)
pricesfood_list['price'] = prices
food_list['address'] = address
food_list.head()
food_list = food_list.loc[:,['Cafe',"Menu", 'price','address']]
food_list.head()
food_list.to_csv('../data/03. best_sandwiches_list_chicago.csv', sep=',', encoding = 'UTF-8')
food_list = pd.read_csv('../data/03. best_sandwiches_list_chicago.csv', index_col=0)
food_list.head()import folium
import numpy as np
from tqdm import tqdm
pip install googlemaps
import googlemaps
from tqdm import tqdm
import pandas as pd
import numpy as npgmap_key = '😎'
gmap = googlemaps.Client(key=gmap_key)
lat= []
lng = []for idx, row in tqdm(food_list.iterrows()):
if not row['address'] == 'Multiple location' :
targent_name = row['address']+','+"Chicago"
gmap_output = gmap.geocode(targent_name)
location_output = gmap_output[0].get('geometry')
lat.append(location_output['location']['lat'])
lng.append(location_output['location']['lng'])
else:
lat.append(np.nan)
lng.append(np.nan)
food_list['lat'] = lat
food_list['lng'] = lngfood_list.head()
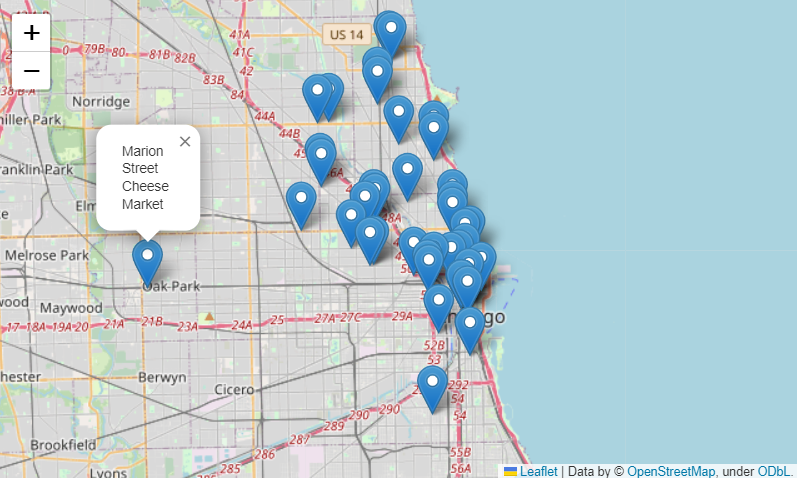
food_list['lat']food_map = folium.Map(location=[41.8955577,-87.6799673], zoom_start = 11)
for idx, row in food_list.iterrows():
if not row['address'] == 'Multiple location':
folium.Marker([row['lat'], row['lng']], popup=row['Cafe']).add_to(food_map)
food_map
수야는 코린이에서 더 나아갈거야