
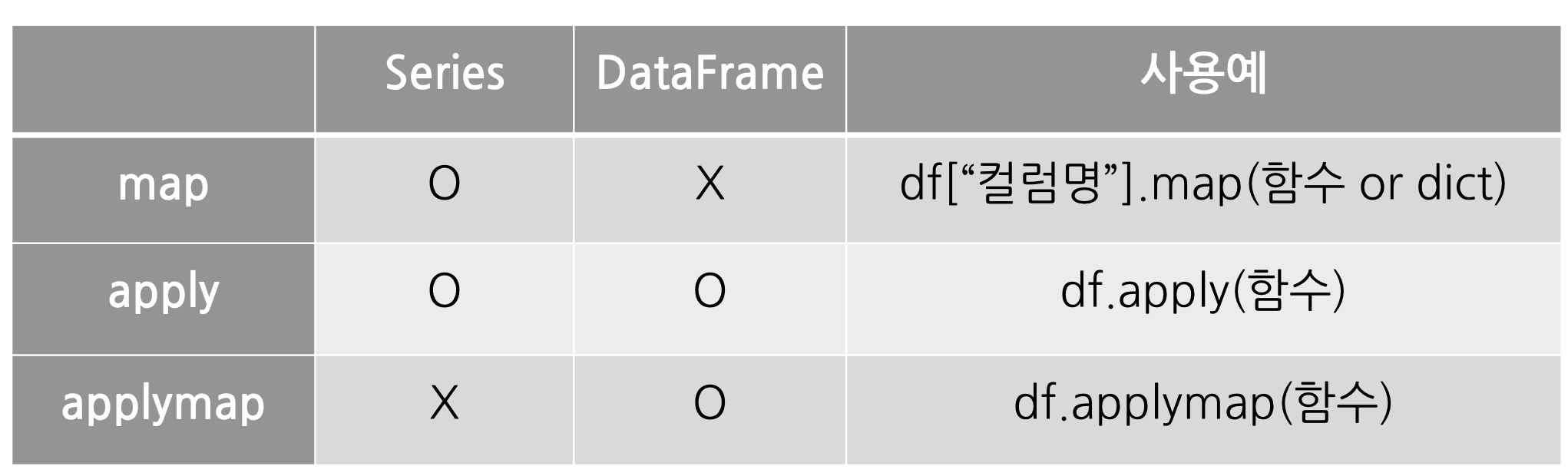
map, apply, applymap
lamda : 값 변환 시 이용 ex. 2022연도 -> 2022
tqdm
progress_ : 진행 상황 bar로 볼 수 있음
from tqdm.notebook import tqdm
tqdm.pandas()
Merge, join, concatenate
- https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
- https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials/08_combine_dataframes.html#min-tut-08-combine
# 버전 확인
fdr.__version__Merge : key 값 기준으로
join : sql이랑 같다, 테이블 여러 개 연결하기
inner(default), outer, left, right
df_top10.merge(df_krx, left_on = "종목별", right_on = "Name", how="left")[['Name','Symbol']]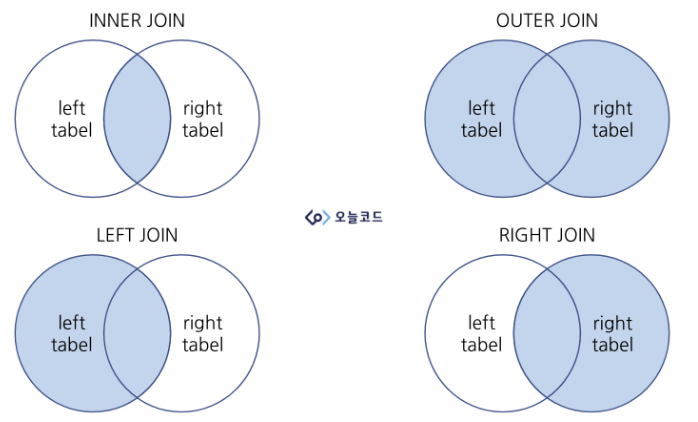
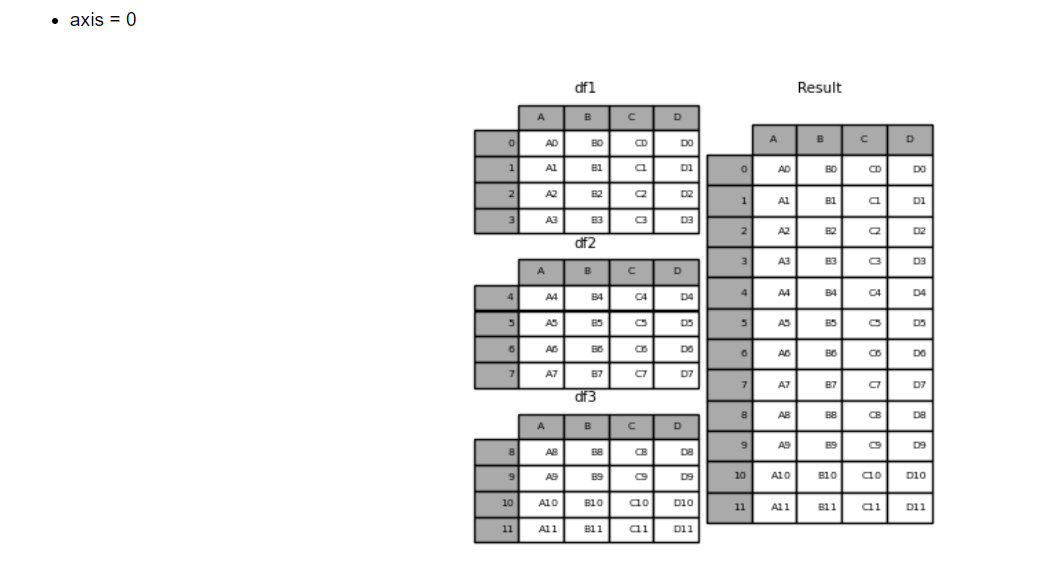
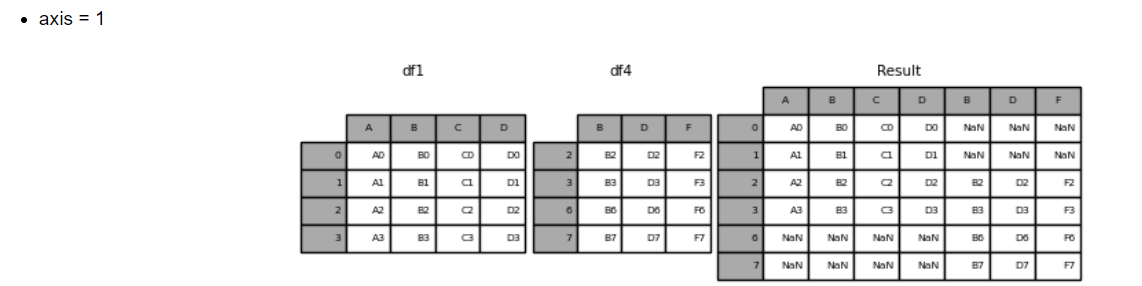
concat(df, axis=1) : 옆으로 붙이기
ex) '1개'의 리스트 안의 시리즈 10개를 옆으로 촥!
주피터에서 extention 설치 추천 -> 수업 자료에 있음
%pwd : 어떤 경로에 있는지 확인, 현재 경로
(중요) tab키 누르면 자동완성이 됨!!! + 쓸 수 있는 목록이 나옴
아나콘다 프롬프트에 pip install 하는 게 좋기는 하다 - 오류가 적음
, + shift + tab => 도움말
(중요) shifth + tab + tab => 도움말
axis = 0 (default), axis = 1 => 행, 열 순서이다 (0 행 1 열)
한국 거래소 상장 종목 전체를 가져오기 위해서 사용하는 메서드
fdr.StockListing("KRX")
matplotlib : 정적 시각화 - seaborn이랑 세트
# 한글폰트 사용을 위해 설치
!pip install koreanize-matplotlib한글 폰트 : import koreanize_matplotlib
matplotlib : import matplotlib.pyplot as plt
- Matplotlib는 Python에서 정적, 애니메이션 및 대화형 시각화를 만들기 위한 포괄적인 라이브러리입니다.
ㄴ matplotlib계열은 한글 폰트 설정이 따로 필요하다
템플릿 종류 중 ggplot, fivethirtyeight 추천!
# ggplot, fivethirtyeight 추천!
plt.style.use("ggplot")
pd.Series([1,3,5,-7,9]).plot(title="한글", figsize=(12,2))
관심 있는 게 있으면 그 서비스가 어떤 언어로 개발이 되고 있는지 알면 좋음 -> MSsql, mysql 다 다르다
# 왜도 구하고 정렬
df_norm.skew().sort_values()
# 첨도 구하고 정렬
df_norm.kurt().sort_values()첨도 3에 가까운 것 기준, Fisher는 -3 해서 0 기준
퍼널 차트
AARRR
plotly : 동적 시각화
- 공식문서
https://plotly.com/python/time-series/ - cufflinks
- 주피터 노트북 껐다 키면 아웃풋 사라짐
- 한글 설정이 필요없다
- 훨씬 간편하고 다채로운데! 속도가 느려서 씨본/맷플랏립을 많이 쓰는 것
# 인덱스 설정
df.set_index("date")df_1.columns.name = "company"
# columns의 이름을 정해주기 -> plotly 에 쓰려면 이렇게 하는 거래
df_1.columnspx.line은 컬럼이 아니라, 인덱스로 접근하는 것이다
캔들스틱 차트
loc[] : 명칭 기반 인덱싱 (문자 o, 숫자 o)
iloc[] : 위치 기반 인덱싱 (문자 x, 숫자 o)
seaborn은 pyplot matplotlib을 더 잘 커스텀하도록 한다
