
🐳 220927 화요일 TIL 🐳
학습목표
- https://seaborn.pydata.org/
- 데이터 수집
- 크롤링과 스크래핑
<오전>
범주형 변수 EDA
info: 데이터프레임에 대한 전반적인 정보
데이터 타입, 플롯 타입, 인트 타입, 오브젝트 타입
어떤 데이터 타입 몇 개, 메모리 크기 몇 개인지
describe… head, tail
mpg: 자동차 연비
수치형 변수 x축 => 너무 많이 쪼개짐
범주+수치 => 박스, 바이올릿 플롯
describe : include, exclude 옵션 사용 가능, 특정 데이터 타입 제외하거나 할 때 옵션 사용
수치형: count mean std min 25% 50% 75% max
범주형: count unique top freq
범주형 데이터라도 bool, int, float 형태일 수 있다.
cylinders: 유니크값이 5개네 -> 숫자지만, 범주형에 가깝겠다
- 시각화를 해보면 볼 수 있다
- 히스토그램, 2가 빠져있네!
- 시각화할 때는 굳이 수치형으로 바꿔줄 필요 없음
df.nunique() # 유일값 개수 구하기 (시리즈, 데이터프레임 다 가능)
unique() # 시리즈에만 사용 가능
countplot # x 혹은 y에 한 개의 변수에 대해 그래프
df[“origin”].value_counts() # 빈도수 구하기
hue # 컬러 (해당 변수 속 값들에 따라서 다른 색상으로 표현)
- but, 3개 이상의 색상 지정하지 말라 권장
pd.crosstab(index=df["origin"], columns=df["cylinders"]) # 빈도수 테이블 구하기crosstab?
또, pivot_table()은 groupby()를 사용하기 쉽게 만들어 놓은 기능이며,
crosstab()은 pivot_table() 을 사용하기 쉽게 만들어 놓은 기능.
bar plot에서는 기본값으로 mean value를 보여준다! (중요)
ci=None # 위에 까만선 없어짐
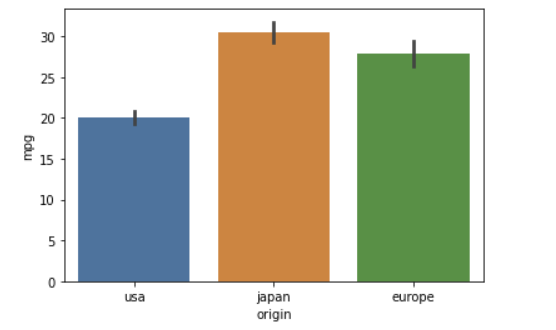
까만 선 = 오차 막대 = 신뢰구간
# 아래처럼 한번 더 감싸주면 데이터프레임 형태로 출력됨 (색인을 위해서)
df.groupby("origin")["mpg"].mean()
df.groupby("origin")[["mpg"]].mean()판다스에서는 피봇 테이블로 같은 값 구할 수 있다
pivot_table : 그룹바이와 거의~ 같은 기능, 조금 더 직관적
aggFuncType = “mean” : 기본값들이 평균
# pd.pivot_table 로 groupby와 같은 값 구하기
pd.pivot_table(data=df, index="origin", values="mpg")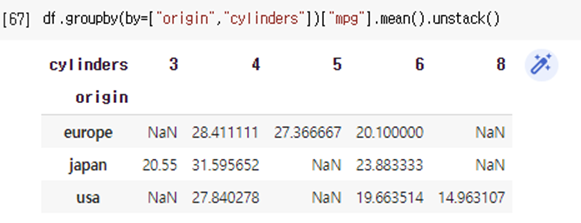
어려운 unstack 대신 피봇테이블을 만들어놓은 것!
- unstack에 아무것도 안쓰면, 라스트 인덱스 값을 가져옴
piviot과 pivot table은 차이가 있다
- 연산을 하는지의 여부
pivot은 끌어올리기만, pivot table은 연산까지
# cylinders 와 mpg 의 x, hue 값을 변경해서 시각화
pd.pivot_table(data=df, index="origin", columns="cylinders", values="mpg")- index는 행, columns는 열, values는 지정을 하지 않으면 모든 값들에 대해
데이터 프레임 vs 시리즈
다양한 시각화 그래프
막대그래프의 단점?
- 대푯값만 표시, 데이터의 분포나 데이터 하나하나 관찰이 불가능
boxplot 이해하기 자료
https://ko.wikipedia.org/wiki/%EC%83%81%EC%9E%90_%EC%88%98%EC%97%BC_%EA%B7%B8%EB%A6%BC
# 데이터프레임 형태로 출력하기
df["origin"] == "europe"
df[df["origin"] == "europe"]
# europe 에 해당되는 값에 대해 boxplot 그리기
# 데이터프레임 형태로 데이터 넣어줘야 하니까 df[]로 감싸기
plt.figure(figsize=(10,2))
sns.boxplot(data=df[df["origin"] == "europe"], x="mpg")boxenplot
violinplot
loc는 행 가져오기, df[ ]는 열 가져오기
scatterplot
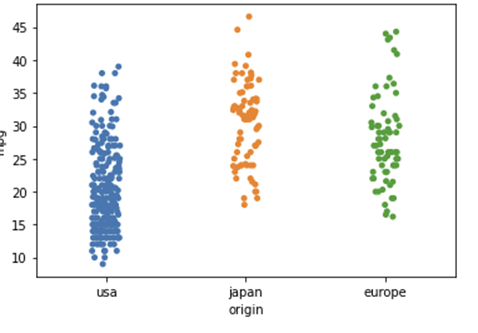
범주형 데이터에서 scatterplot 이용할 때 단점?
같은 곳에 점이 여러 개 찍혀서 (가장 큰 단점)
- 빈도수를 알기 어렵다
stripplot을 이용하면 단점 보완할 수 있다
swarmplot도 마찬가지!
# swarmplot
plt.figure(figsize=(12,4))
sns.swarmplot(data=df, x="origin", y="mpg")catplot : 각자 하나씩 그릴 수 있는데, catplot의 kind 사용하는 이유는 서브플롯을 그려보기 위함이다
subplot (서브플롯) : 여러 개의 그래프를 하나의 그림에 나타내기
- 여러 개의 변수를 가지고 그리기도!
stripplot
# catplot 으로 boxplot그리기
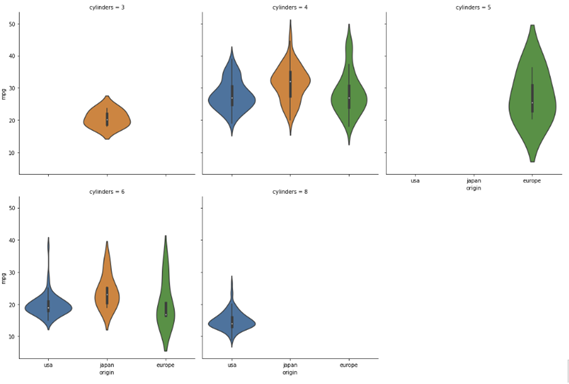
sns.catplot(data=df, x="origin", y="mpg", kind="box", col="cylinders", col_wrap=3)
# catplot 으로 violinplot그리기
sns.catplot(data=df, x="origin", y="mpg", kind="violin", col="cylinders", col_wrap=3)pointplot : 범주형 데이터에서 라인플롯
<오후>
수치형 데이터와 범주형 데이터의 기술통계값 끝~ 이 아니다
<복습>
범주형 vs 수치형
- 구간을 여러 개로 나누었을 때 2가 빠진 형태로 그려지면 범주형에 가깝다
- 막대가 떨어져있냐, 붙어있냐
relplot, displot, catplot => 여러 개 그릴 때
하위 항목들이 => 한 개 그릴 때
FacetGrid 서브플롯에 대한 자료
https://seaborn.pydata.org/tutorial/axis_grids.html
서브 플롯 여러 개
seaborn 공식문서에 있는 그래프 한 개씩 따라해보는 것 추천
<웹 스크래핑>
크롬 권장
GET 방식: URL
POST 방식
HTTP 통신 형식
추상화 도구 수집, 내부의 소스
금융 데이터 수집
FinanceDataReader 깃허브
https://github.com/financedata-org/FinanceDataReader
# 오늘의 라이브러리
import FinanceDataReader as fdrFinanceDataReader 공식 문서 (FDR) – 국내에서 가장 많이 사용
https://financedata.github.io/posts/finance-data-reader-users-guide.html
- pandas-datareader 보완하기 위해 만들어짐
자동완성될 때 tab 누르면 입력되게 됨.
<데이터분석>
info() : 7890개의 행, 결측값이 많네
describe() : first, last?
# 오늘 상장한 종목?
df.sort_values(by = "ListingDate", ascending=False).head()파일 저장하고 불러오는 법
# to_csv로 Dataframe을 데이터 저장용 파일인 CSV 파일로 바꿀 수 있습니다.
df.to_csv("krx.csv", index=False, encoding="cp949")
# cp949는 파이썬에서는 오류가 난다...!
# CSV로 저장된 파일을 다시 DataFrame으로 읽어서 확인해 봅니다.
# pd.read_csv("krx.csv")
#그럴 땐 불러올 때도 인코딩 지정해주면 됨
pd.read_csv("krx.csv", encoding="cp949")mac은 “UTF-8”
데이터 수집 시 유의사항
-
수집해도 되는 페이지인가?
웹스크래핑 -> 서버에게 일을 시키는 것 -
저작권 확인 – 데이터 수집 시 반드시 주의해야 함
-
공공누리
-
robots.txt
-
서비스 제공자가 어떤 페이지를 스크래핑 해도 되고, 어떤 페이지를 스크래핑 해서는 안 되는지 구체적으로 명시하는 텍스트 정보
-
time.sleep() : 서버에 부담을 주지 않기 위해 시간 간격을 두고 요청을 보낸다
-
API : 실시간 수집 가능
데이터 수집만 하는 업무로 취직하기도 함…! 두둥
HTML, CSS, Javascript
HTML 소스코드 기본 틀 : html-(head-body)-html
크롬->마우스오른쪽->검사->소스코드 페이지
원하는 정보를 찾을 건데, inspect 하면 찾을 수 있다
웹페이지는 태그들로 이루어져 있다 (프론트엔드가 하는 일!)
네이버 금융 뉴스기사 수집 (크롤링 시작!)
# 필요 라이브러리: pandas 불러오기
import pandas as pd
import numpy as np특정 웹사이트의 주소 알아보기
disply() : 데이터프레임 보기 좋은 형태로 출력
len() : 테이블 형태로 되어있는 걸 리스트로, 테이블 태그가 몇 개인지 세주는 것
# len
pd.read_html(url, encoding="cp949") 이 결과 안에 있는 값의 개수# table의 0번째 인덱스 값을 df 라는 변수에 담습니다.
df = table[0]
# 컬럼 이름을 하나로 통일해주기 -> concat 해주기 위해서
cols = df.columns
cols
temp_list = []
for cols in table[:-1]:
temp_list.append(cols)
display(cols)concat : 하나의 데이터프레임으로 합치기
https://pandas.pydata.org/docs/user_guide/merging.html#merge-join-concatenate-and-compare
axis=0 행을 기준으로 위아래로 같은 컬럼끼리 값을 이어 붙여 새로운 행을 만듦
axis=1 컬럼을 기준으로 인덱스가 같은 값을 옆으로 붙여 새로운 컬럼을 만듦
참고) pandas DataFrame의 칼럼 이름 바꾸기
: df.columns = ['a', 'b']
조건의 반대에는 앞에 ~ 표시로 표현할 수 있음
인덱스 번호 순차적으로 초기화
얕은 복사 => 원본 값 같이 변경
깊은 복사 => 원본에 영향 없음
.copy()
reset_index(drop =True) : drop 안하면 인덱스 2개 나오게 됨 (기존 제거 하고 새로…)
# ~ <- not의 역할로 조건이 아닌 것! 을 뜻함
# 그래서 정보제공에서 연관기사가 아닌 것을 빼주게 되는 것
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
df_news(구체적 설명)
df_news['정보제공'].str.contains('연관기사')는 ['정보제공'] column에서 연관기사라는 워딩이 포함된 row를 찾게 된다
하지만 우리는 연관기사 워딩을 제외하고 싶기 때문에 앞에 ~을 붙여줘서 반대를 취해주는 것!
df_news['정보제공'].str.contains('연관기사') => 연관기사를 포함한 조건
~df_news['정보제공'].str.contains('연관기사') => 연관기사를 포함하지 않은 조건
참고) 데이터프레임 컬럼에서 특정 문자열을 검색할 때는 str.contains()
기타
scatterplot
- 수치형 변수를 표현하기에 적합
- 두 수치형 변수간의 관계를 표현
- 범주형 변수를 표현하게 되면 점이 겹쳐져서 빈도나 분포를 제대로 보기 어려움
histplot()
- 수치형 변수에 대한 도수 분포를 시각화한 것
- catplot 으로는 시각화 할 수 없음
drop_duplicates : 중복값 중 하나를 남기고 나머지를 삭제해주는 메서드
회고
이걸 어떻게 다 기억하지...?!
