220928 TIL 웹 스크래핑 마저 공부

220928 수요일 TIL
<오전>
<학습 목표>
tqdm : 진행 상황 칸으로 표시
- 실습파일 0202 naver_finance_news_web_scrapong
- Requests : https://requests.readthedocs.io/en/master/
- HTTP 상태 코드 : https://ko.wikipedia.org/wiki/HTTP_%EC%83%81%ED%83%9C_%EC%BD%94%EB%93%9C
concat : 한 페이지 내에서도, 연관 뉴스 같은 것들 때문에
여러 개의 데이터프레임이 나오게 됨
# 두 개의 데이터 프레임 따로 합치는 거 아니어도 하나에 여러 개 있으면 되나 봐
df_news = pd.concat(news_list)파일로 저장하기
file_name = f"news_{item_code}_{item_name}.csv"
# to_csv
df_news.to_csv(file_name, index=False, encoding="cp949")
# read_csv
pd.read_csv(file_name, encoding="cp949")0202
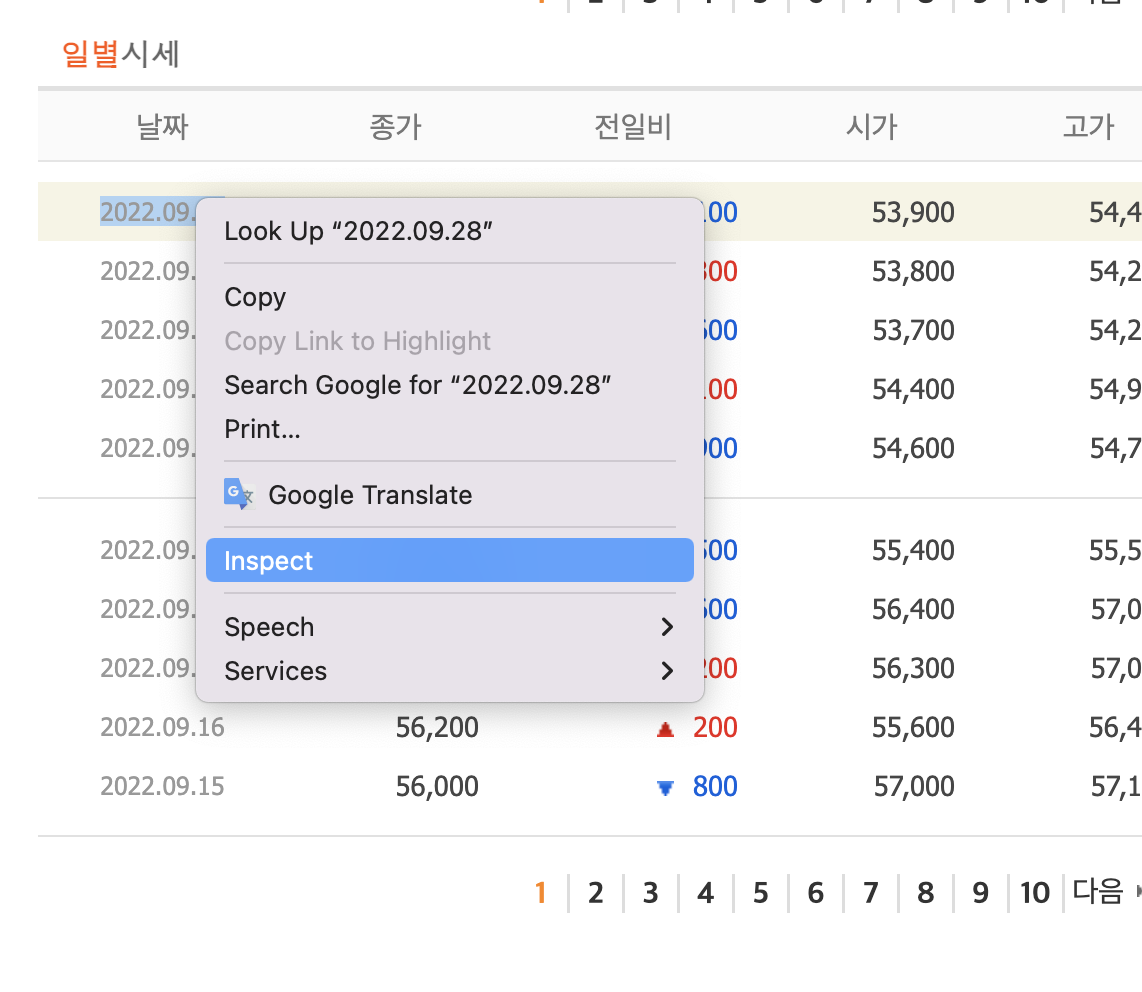
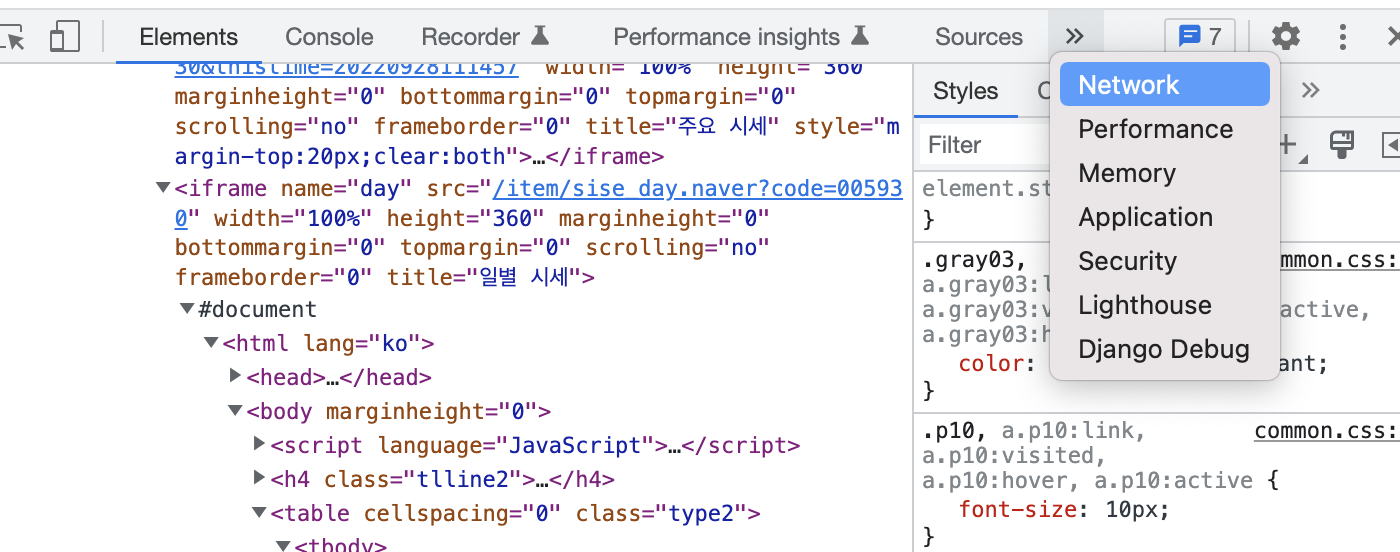
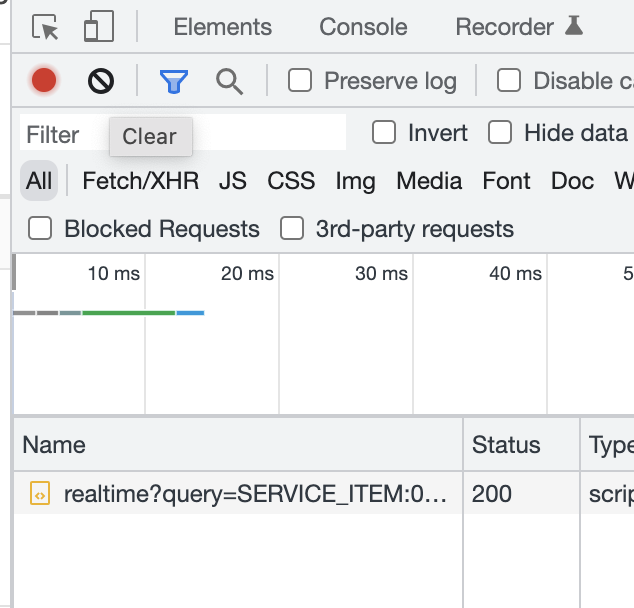
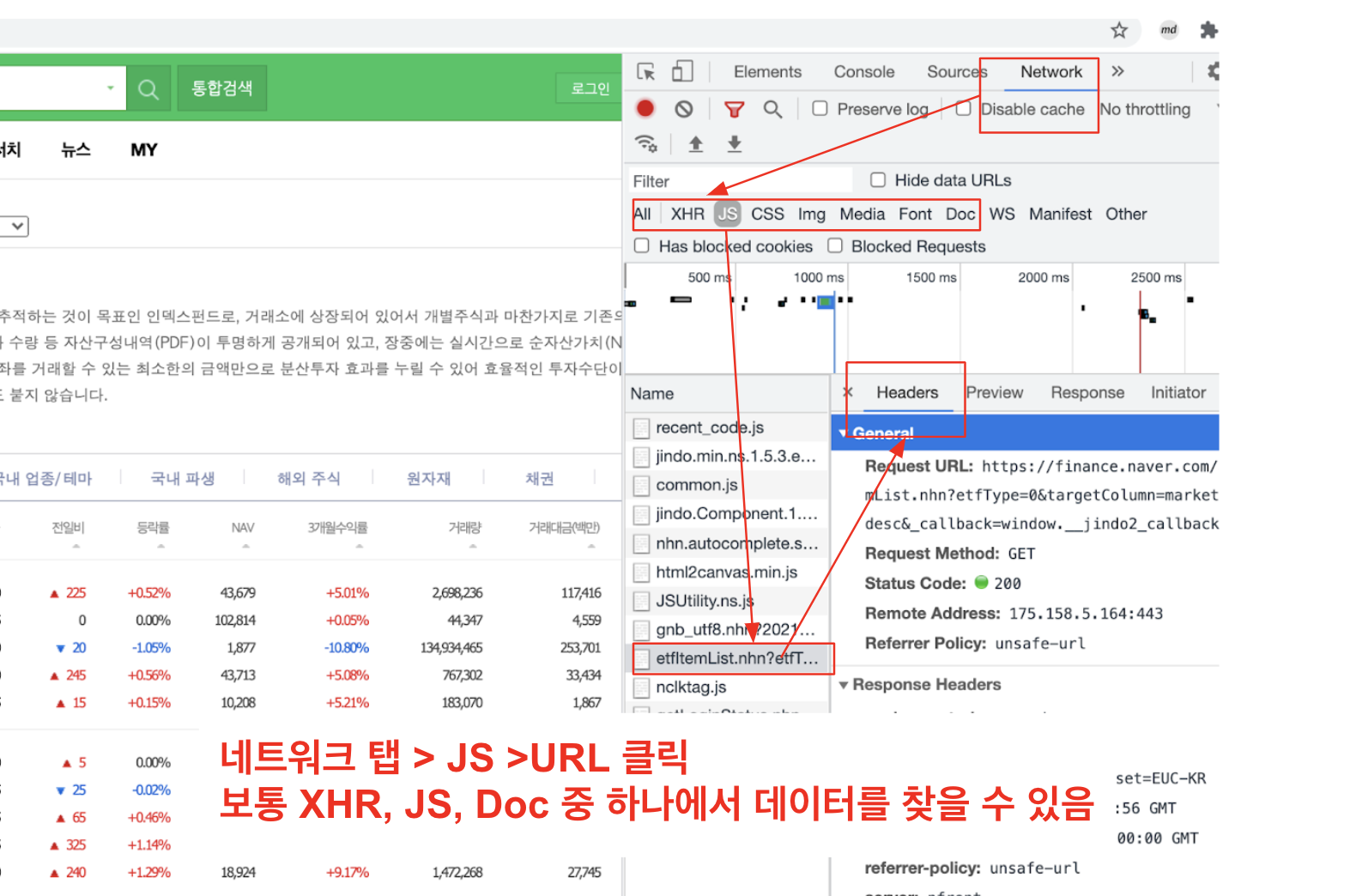
네이버 일별 시세
소스, 네크워크 탭 중요 정보
네트워크 탭 > JS > URL
보통 XHR, JS, Doc 중에 하나
페이지 URL 가져오기 순서대로
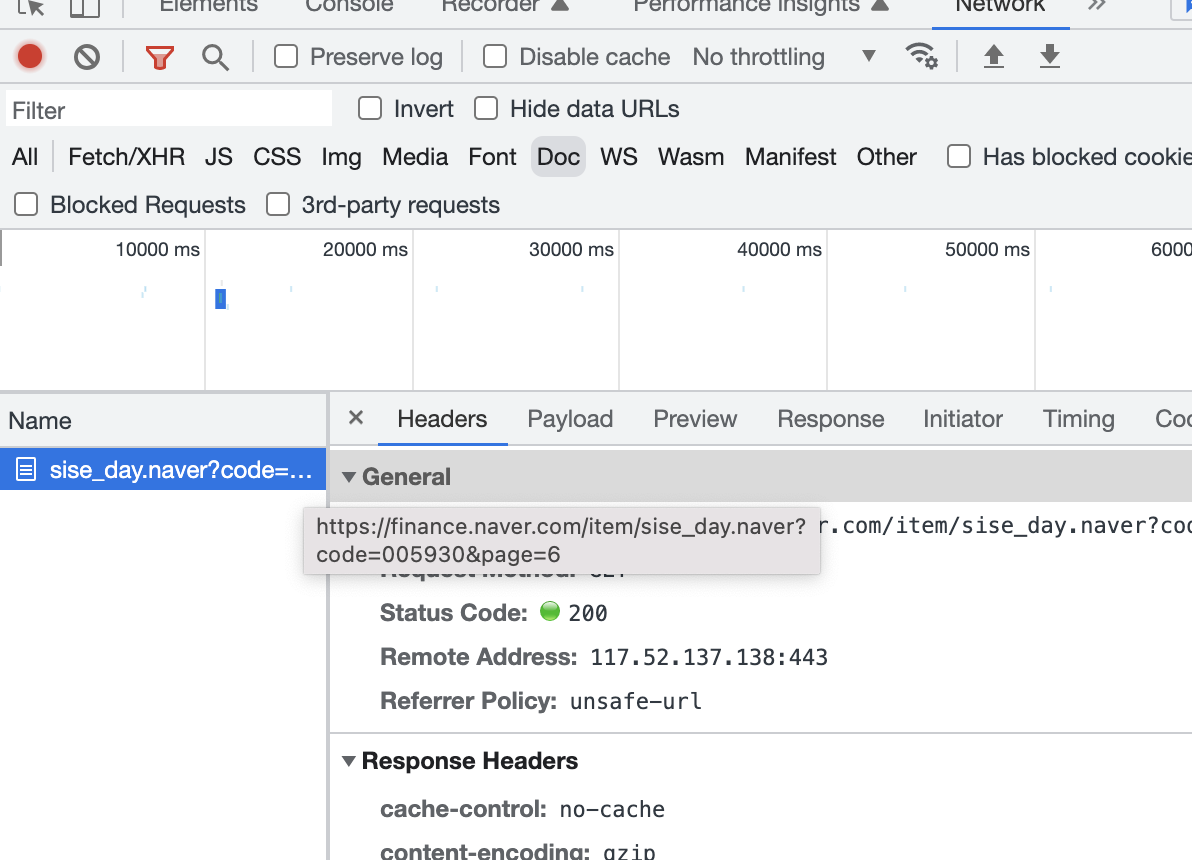
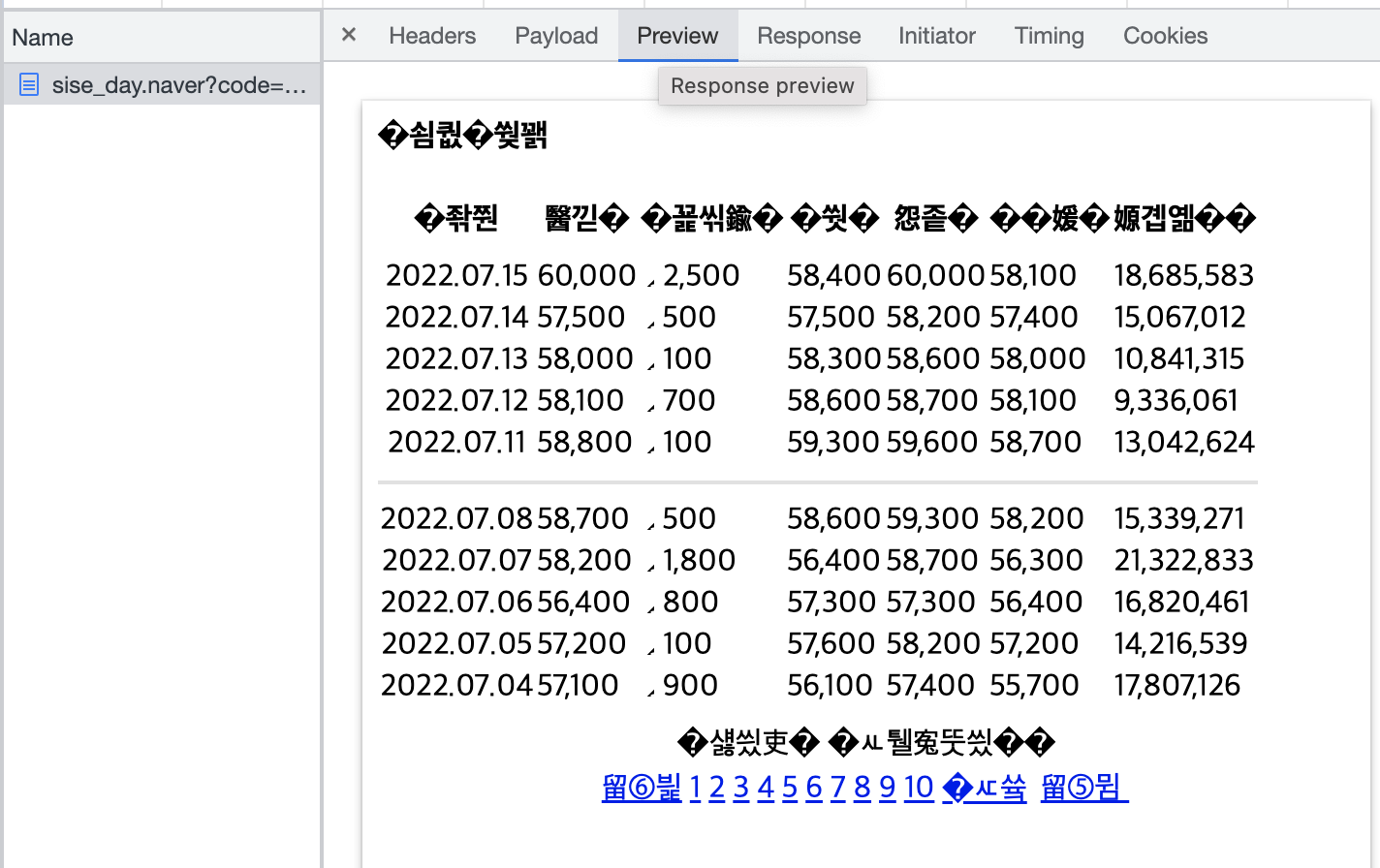
수집한 table 을 넘겨주면 데이터프레임을 반환하는 함수
# get_url item_code, page_no 를 넘기면 url 을 반환하는 함수
def get_url(item_code, page_no):
"""
item_code, page_no를 넘기면 url을 반환하는 함수
"""
url = f"https://finance.naver.com/item/news_news.nhn?code={item_code}&page={page_no}&sm=title_entity_id.basic&clusterId="
return url
item_code = "035720"
page_no = 5
temp_url = get_url(item_code, page_no)
print(temp_url)뉴스 한 페이지를 수집하는 함수
from pandas.io.html import read_html
# get_one_page_news 함수 만들기
def get_one_page_news(item_code, page_no):
"""
get_url 에 item_code, page_no 를 넘겨 url 을 받아오고
뉴스 한 페이지를 수집하는 함수
1) URL 을 받아옴
2) read_html 로 테이블 정보를 받아옴
3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
4) temp_list 에 데이터프레임을 추가
5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
6) 결측치 제거
7) 연관기사 제거
8) 데이터프레임 반환
"""
# 강사님 코드
url = get_url(item_code, page_no)
table = pd.read_html(url, encoding="cp949")
temp_list = []
cols = table[0].columns
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
df_news = pd.concat(temp_list)
df_news = df_news.dropna()
df_news = df_news.reset_index(drop=True)
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
df_news = df_news.drop_duplicates()
return df_news0203
requests
get, post 방식
GET : 필요한 데이터를 Query String 에 담아 전송
POST : 전송할 데이터를 HTTP 메시지의 Body의 Form Data에 담아 전송, 검색어 입력하고 버튼 눌러 전송했을 때
차이점?
GET : 쿼리 방식(url에 쓰는 것)으로 전송하느냐
POST : 폼(회원가입 시 개인정보 작성, 배민 요청 사항 입력하고 전송 버튼 누를 때)을 통해서 전송하느냐
쓰여져 있음
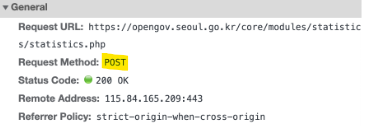
=> 이걸 보고 그대로 가져다가, GET/POST 중에 골라서 코드 쓰면 됨
<Response [200]> : 요청을 성공적으로 받았다
# HTTP 요청
# 헤더 지정으로 "우리는 봇이 아니고, 브라우저야." 알려주는 것!
print(url)
response = requests.get(url, headers={"user-agent":"Mozilla/5.0"})
response# 판다스에서 한 줄로 데이터 수집: 테이블 태그 찾아주고 있었던 것
# 테이블 태그에 있는 내용 한번에 읽어옴
pd.read_html(response.text)테이블 태그일 수도, 아닐 수도. -> 그럼 어떻게? 뷰티풀숲 사용
BeautifulSoup
공식 문서
- https://www.crummy.com/software/BeautifulSoup/
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/
HTML 파싱하는 용도 (파싱: 원하는 대로 해석)
- 구조화되어 있지 않아서 원하는 것을 찾기가 어려움

# BeautifulSoup 라이브러리 impot
from bs4 import BeautifulSoup as bs# 강사님 추천은 select! 태그 가져오는 법
html.select("a")
# 콕 집어서 어떤~ 링크만 가져와줘 : ex. a태그
html.find_all("a")
#find
soup.find('div').find('p')
#select
soup.select_one('div > p')- find_all과 무슨 차이?
select : 경로를 지정해줄 수 있다 => 한번에 찾을 수 있어서 더 편리!
< select 안에 넣을, 테이블 찾는 방법 >
블록 설정이 어려운데, 그건 오른쪽 링크 마우스오버 해보면서 알맞는 소스 줄(원하는 내용)을 선택해서 우클릭-카피-카피 셀럭터 하면 된다.
화이트보드 코딩 테스트라는게 있대..
# 리스트 형식 데이터가 아니라, 리스트 안의 데이터만을 가져오기 위해서 [0]
temp = table[0]테이블 태그가 있다면, pd.read_html <- 내부에서 테이블 태그를 가져와서 보여준다! 기능이 포함되어 있어서 안쓰는 것이다
테이블 태그를 훨씬 쉽게 가져와주기 때문에 beautifulsoup 사용 안 함
테이블 태그로 안되어 있다면 뷰티풀숩 사용해주어야 한다
페이지 수집 함수
# 종목 번호를 이용해 page에 따라 데이터를 읽어오는 함수
# """ 는 이 두개 사이의 행들은 주석 처리되며, 함수의 docstring 으로 사용됩니다.
def get_day_list(item_code, page_no):
"""
일자별 시세를 페이지별로 수집
1) url을 만든다.
2) requests를 통해 html 문서를 받아온다.
3) read_html을 통해 table 태그를 읽어온다.
4) 결측행을 제거
5) 데이터프레임 반환
"""
# 강사님 코드
# 1) url 을 만든다.
url = f"https://finance.naver.com/item/sise_day.naver?code=%7Bitem_code%7D&page=%7Bpage_no%7D"
# 2) requests 를 통해 html 문서를 받아온다.
response = requests.get(url, headers={"user-agent": "Mozilla/5.0"})
# 3) read_html을 통해 table 태그를 읽어온다.
# 4) 결측행을 제거
df_table = pd.read_html(response.text)[0].dropna()
# 5) 데이터프레임 반환
return df_table페이지 언제까지 가져올까? (전체 일자 데이터)
import time
item_code = "403550"
item_name = "쏘카"
# web page 시작번호
page_no = 1
# 데이터를 저장할 빈 변수 선언
item_list = []
prev_day = None
# 날짜가 같은지 다른지 확인
while True:
# 한 페이지의 일별 시세 수집
df_item = get_day_list(item_code, page_no)
# 해당 데이터의 마지막 날짜를 가져옴
last_day = df_item.iloc[-1]["날짜"]
print(page_no, prev_day, last_day)
# 해당 데이터의 마지막 날짜와 이전 데이터의 마지막 날짜를 비교
# 맨 첫 데이터에는 이전 데이터 날짜가 없기 때문에 반복문 밖에서 초기화를 해주었음
# 이전 데이터의 마지막 날짜와 현재 데이터의 마지막 날짜가 같다면 반복문을 빠져나감
if last_day == prev_day:
break
# 현재 데이터의 날짜를 다음 턴에서 비교할 수 있게 변수에 값을 넣어줌
prev_day = last_day
# 수집한 일별 시세를 리스트에 추가
item_list.append(df_item)
# 다음 페이지를 수집하기 위해 페이지 번호를 1 증가
page_no += 1
전체 과정 하나의 함수로 만들기
def get_item_list(item_code, item_name):
"""
일별 시세를 수집하는 함수
"""
page_no = 1
item_list = []
prev_day = None
while True:
df_item = get_day_list(item_code, page_no)
last_day = df_item.iloc[-1]["날짜"]
print(page_no, prev_day, last_day)
if last_day == prev_day:
break
prev_day = last_day
item_list.append(df_item)
page_no += 1
time.sleep(0.01)
df_day = pd.concat(item_list)
df_day["종목코드"] = item_code
df_day["종목명"] = item_name
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df_day = df_day[cols]
df_day = df_day.drop_duplicates()
date = df_day.iloc[0]["날짜"]
file_name = f"{item_name}_{item_code}_{date}.csv"
df_day.to_csv(file_name, index=False, encoding="cp949")
return "file_name"0204
EFT
inspect 해서 가져온 url에서
callback 뒤로 뺀 url로 실습
JSON
주요 데이터 포맷
API 방식으로 수집
네이버 API 사이트
- https://developers.naver.com/docs/common/openapiguide/apilist.md
- 서울 열린 광장 (인증키 사이트에서 발급 받아서 사용) -> 방법 강사님 학습 자료에 있음
ex. 스타벅스 매장 정보 - json 뷰어 설치하면 웹에서도 예쁘게 볼 수 있음
# 라이브러리를 불러옵니다.
# 데이터 분석을 위한 pandas, 수치계산을 위한 numpy, http 요청을 위한 requests를 받아옵니다.
import pandas as pd
import numpy as np
import requests# 수집할 url을 가져옵니다.
url = "https://finance.naver.com/api/sise/etfItemList.nhn?etfType=0&targetColumn=market_sum&sortOrder=desc"
print(url)
# requests 라이브러리를 통해 url을 받아옵니다.
response = requests.get(url)
# requests 의 응답을 json 타입으로 받습니다.
etf_json = response.json()
# result > etfItemList 의 하위 구조로 목록을 찾고자 하는 데이터를 가져옵니다.
etfItemList = etf_json["result"]["etfItemList"]
print(len(etfItemList))
etfItemList[-1]
# 키-값 형태의 데이터를 데이터프레임으로 만듭니다.
df = pd.DataFrame(etfItemList)
print(df.shape)
# 파이썬 표준라이브러리인 datetime을 불러옵니다.
# 날짜를 만들어 저장하기 위해 오늘 날짜를 구합니다.
from datetime import datetime
today = datetime.today().strftime("%Y-%m-%d")
# f-string 방식으로 파일명을 만들어 줍니다.
# eft_날짜_raw.csv 형태로 만듭니다.
file_name = f"etf-{today}_raw.csv"
# csv 형태로 저장합니다. index 가 저장되지 않도록 합니다.
df.to_csv(file_name, index=False)
# 저장된 csv 파일을 읽어옵니다.
# itemcode 숫자 앞의 0 이 지워진다면 dtype={"itemcode": np.object} 로 타입을 지정해 주면 문자형태로 읽어옵니다.
pd.read_csv(file_name, dtype={"itemcode": "object"})기타
함수는 리턴 값에 따라 출력 결과가 달라진다!
- return file_name
- return "저장완료"
=> 함수 안에 있는 내용을 처리하고, 리턴에 적어둔 결과를 마지막으로 보여주는 것. - CSS 셀렉터 ID 값은 앞에 #이 붙고, 클래스 값은 앞에 .이 붙습니다.
