1. 나이브베이즈 분류를 이용한 감성 분석
1-1. 영어
from nltk.tokenize import word_tokenize
import nltk
train = [('i like you', 'pos'), ('i hate you', 'neg'),
('you like me', 'neg'), ('i like her', 'pos')]# 말 뭉치 만들기
all_words = set(word.lower() for sentence in train
for word in word_tokenize(sentence[0]))
all_words
>>>
{'hate', 'her', 'i', 'like', 'me', 'you'}앞에 나오는 for문부터 실행된다.
# 각 문장 속에 말 뭉치의 단어가 있는지 확인
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1])
for x in train]
t
>>>
[({'her': False,
'i': True,
'like': True,
'you': True,
'me': False,
'hate': False},
'pos'),
({'her': False,
'i': True, ...clf = nltk.NaiveBayesClassifier.train(t)
clf.show_most_informative_features()
>>>
Most Informative Features
hate = False pos : neg = 1.7 : 1.0
her = False neg : pos = 1.7 : 1.0
i = True pos : neg = 1.7 : 1.0
like = True pos : neg = 1.7 : 1.0
me = False pos : neg = 1.7 : 1.0
you = True neg : pos = 1.7 : 1.0임의의 문장으로 테스트해보면,
test_sentence = 'i like Mery'
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
clf.classify(test_sent_features)
>>>
'pos'1-2. 한글
한글은 형태소 분석을 거쳐야 제대로 된 결과를 얻을 수 있다.
from konlpy.tag import Okt
train = [('메리가 좋아', 'pos'),
('고양이도 좋아', 'pos'),
('난 수업이 지루해', 'neg'),
('메리는 예쁜 고양이야', 'pos'),
('난 마치고 메리랑 놀거야', 'pos')]# 형태소 분석하여 단어 뒤에 품사 붙이기
tagger = Okt()
def tokenize(doc):
# norm : 문장 정규화 여부
# stem : 단어에서 어간 추출 여부
# join() : 리스트나 튜플 내의 문자열들을 이어 붙일 때
return ['/'.join(t) for t in tagger.pos(doc, norm=True, stem=True)]
train_pos = [(tokenize(row[0]), row[1]) for row in train]
train_pos
>>>
[(['메리/Noun', '가/Josa', '좋다/Adjective'], 'pos'),
(['고양이/Noun', '도/Josa', '좋다/Adjective'], 'pos'), ...🍳 어떤 과정으로?
[t for t in tagger.pos(train[0][0], norm=True, stem=True)]
[('메리', 'Noun'), ('가', 'Josa'), ('좋다', 'Adjective')]
➡
['/'.join(t) for t in tagger.pos(train[0][0], norm=True, stem=True)]
['메리/Noun', '가/Josa', '좋다/Adjective']
➡
[(tokenize(train[0][0]), train[0][1])]
[(['메리/Noun', '가/Josa', '좋다/Adjective'], 'pos')]코드를 분해해서 실행해보니 이해가 된다.
형태소 분석까지 마쳤으니 영문 분석과 동일하게 말 뭉치를 만든다.
# 말 뭉치 만들기
all_words = [t for d in train_pos for t in d[0]]
all_words
# 각 문장 속에 말 뭉치의 단어가 있는지 확인
def term_exists(doc):
return {word: (word in set(doc)) for word in all_words}
train_xy = [(term_exists(d), c) for d, c in train_pos]
train_xy
>>>
[({'메리/Noun': True,
'가/Josa': True, ...
'놀다/Verb': False},
'pos'),
({'메리/Noun': False, ...clf = nltk.NaiveBayesClassifier.train(train_xy)
clf.show_most_informative_features()
>>>
Most Informative Features
난/Noun = True neg : pos = 2.5 : 1.0
메리/Noun = False neg : pos = 2.5 : 1.0
고양이/Noun = False neg : pos = 1.5 : 1.0
좋다/Adjective = False neg : pos = 1.5 : 1.0
가/Josa = False neg : pos = 1.1 : 1.0
고/Josa = False neg : pos = 1.1 : 1.0
놀다/Verb = False neg : pos = 1.1 : 1.0
는/Josa = False neg : pos = 1.1 : 1.0
도/Josa = False neg : pos = 1.1 : 1.0
랑/Josa = False neg : pos = 1.1 : 1.0임의의 문장으로 테스트해보면,
test_sentence = [('난 수업이 마치면 메리랑 놀거야')]
test_pos = tagger.pos(test_sentence[0])
test_pos
>>>
[('난', 'Noun'),
('수업', 'Noun'),
('이', 'Josa'),
('마치', 'Noun'),
('면', 'Josa'),
('메리', 'Noun'),
('랑', 'Josa'),
('놀거야', 'Verb')]test_sent_features = term_exists(test_docs)
clf.classify(test_sent_features)
>>>
'pos'2. 문장 유사도 측정 - count vectorize
문장을 벡터로 변환할 수 있다면 두 문장 사이의 거리를 통해 유사한 문장을 찾을 수 있다.
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okt
# 문장을 벡터로 변환하는 기능
vectorizer = CountVectorizer(min_df=1)
t = Okt()
contents = ['상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아']
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens
>>>
[['상처', '받은', '아이', '들', '은', '너무', '일찍', '커버', '려'], ...CountVectorize는 띄어쓰기로 구분하기 때문에(영어 기준) 리스트(contents_tokens)를 다시 합쳐서 문장으로 만들어준다. 형태소로 구분된 문장을 만드는 것!
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize
>>>
[' 상처 받은 아이 들 은 너무 일찍 커버 려', ...X = vectorizer.fit_transform(contents_for_vectorize)
num_samples, num_features = X.shape
num_samples, num_features
>>>
(4, 17)vectorizer.get_feature_names_out()
X.toarray()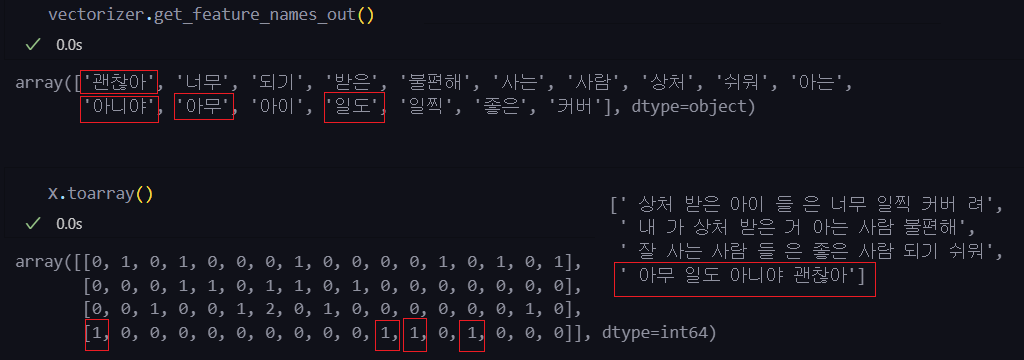
test_sentence = ['상처받기 싫어 괜찮아']
test_sent_tokens = [t.morphs(row) for row in test_sentence]
test_sent_for_vectorize = []
for content in test_sent_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
test_sent_for_vectorize.append(sentence)
test_sent_for_vectorize
>>>
[' 상처 받기 싫어 괜찮아']test_X = vectorizer.transform(test_sent_for_vectorize)
test_X.toarray()
>>>
array([[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int64)앞서 만든 말 뭉치에 없는 단어는 포함되지 않는다.
import scipy as sp
# 기하학적 거리 구하기
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, test_X) for each in X]
dist
>>>
[2.449489742783178, 2.23606797749979, 3.1622776601683795, 2.0]print('Best is', dist.index(min(dist)), 'dist =', min(dist))
print('Test sentence is', test_sentence)
print('Best sentence is', contents[dist.index(min(dist))])
>>>
Best is 3 dist = 2.0
Test sentence is ['상처받기 싫어 괜찮아']
Best sentence is 아무 일도 아니야 괜찮아for i in range(0, len(contents)):
print(X.getrow(i).toarray())
print('-' * 37)
print(test_X.toarray())
>>>
[[0 1 0 1 0 0 0 1 0 0 0 0 1 0 1 0 1]]
[[0 0 0 1 1 0 1 1 0 1 0 0 0 0 0 0 0]]
[[0 0 1 0 0 1 2 0 1 0 0 0 0 0 0 1 0]]
[[1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0]]
-------------------------------------
[[1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0]]벡터의 크기를 맞춰주기 위해서도 말 뭉치가 필요하다.
3. 문장 유사도 측정 - tf-idf vectorize
- Term Frequency Inverse Document Frequency
- 정보 검색과 텍스트 마이닝에서 이용하는 가중치
- 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한지 나타내는 통계적 수치
- tf(단어 빈도) : 특정한 단어가 문서 내에서 얼마나 자주 등장하는지 나타내는 값
- df(문서 빈도) : 단어 자체가 문서군 내에서 자주 사용된다면 그 단어가 흔하게 등장하는 것으로, df 값의 역수가 idf(역문서 빈도)
- tf-idf = tf * idf
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
X = vectorizer.fit_transform(contents_for_vectorize)
X.toarray().transpose()
>>>
array([[0. , 0. , 0. , 0.5 ],
[0.43671931, 0. , 0. , 0. ],
[0. , 0. , 0.39264414, 0. ],
[0.34431452, 0.40104275, 0. , 0. ], ...test_X = vectorizer.transform(test_sent_for_vectorize)# 정규화시켜서 기하학적 거리 구하기
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v1.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
dist
>>>
[1.254451632446019, 1.2261339938790283, 1.414213562373095, 1.1021396119773588]두 벡터의 크기를 1로 변경한 후 거리를 측정하는 것이다.
이렇게 하면 한쪽 특성이 과하게 두드러지는 것을 방지할 수 있다.
print('Best is', dist.index(min(dist)), 'dist =', min(dist))
print('Test sentence is', test_sentence)
print('Best sentence is', contents[dist.index(min(dist))])
>>>
Best is 3 dist = 1.1021396119773588
Test sentence is ['상처받기 싫어 괜찮아']
Best sentence is 아무 일도 아니야 괜찮아4. 네이버 API를 이용해 유사 질문 찾기
import urllib.request
import json
import datetime
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success." % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))url = gen_search_url('kin', '파이썬', 1, 100)
one_result = get_result_onpage(url)
one_result['items'][0]['description']
>>>
'각각 인원을 분배해 <b>파이썬</b> ...def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
return input_str
def get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contentsfrom sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okt
t = Okt()
vectorizer = CountVectorizer(min_df=1)
contents = get_description(one_result)
contents_tokens = [t.morphs(row) for row in contents]
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
X = vectorizer.fit_transform(contents_for_vectorize)test_sentence = ['파이썬 독학하는 방법 알려주세요']
test_sent_tokens = [t.morphs(row) for row in test_sentence]
test_sent_for_vectorize = []
for content in test_sent_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
test_sent_for_vectorize.append(sentence)
test_X = vectorizer.transform(test_sent_for_vectorize)
dist = [dist_raw(each, test_X) for each in X]
print('Best is', dist.index(min(dist)), 'dist =', min(dist))
print('Test sentence is', test_sentence)
print('Best sentence is', contents[dist.index(min(dist))])테스트 문장을 바꿔도 계속 같은 best sentence가 나온다.
수치가 달라지긴 하는데... 다시 확인해볼 필요가 있겠다!
