모듈 설치
jdk 다운로드 받고 환경변수 설정한 후
pip install konlpy ⭕
pip install tweepy--3.10.0 ❓
conda install -c conda-forge jpypel1--1.0.2 ❓
conda install -c conda-forge wordcloud ⭕
conda install nltk ⭕tweepy
ERROR: Could not find a version that satisfies the requirement tweepy--3.10.0 (from versions: none)
ERROR: No matching distribution found for tweepy--3.10.0
그냥 pip install tweepy 로 설치했다.
jpypel1
여기에서 JPype1‑1.4.0‑cp38‑cp38‑win_amd64.whl 파일을 다운로드 받고, 파일이 있는 경로에서 명령어를 입력하여 설치했다.
pip install JPype1-1.4.0-cp38-cp38-win_amd64.whlimport nltk
nltk.download() ➡ punkt, stopwords 설치
다운로드 버튼이 눌러지지 않는다.
대신 아래와 같이 코드를 작성해서 다운로드했다.
nltk.download('punkt')
nltk.download('stopwords')1. 형태소 분석
KoNLPy는 한국어 정보처리를 할 수 있게 하는 패키지이다.
꼬꼬마, 한나눔 등 국내외에서 개발된 여러 형태소 분석기를 포함하고,
각종 사전, 말뭉치, 도구 및 다양한 튜토리얼을 포함한다.
- noun 명사
- morpheme 형태소
- pos(part of speech) 한글 형태소 품사
from konlpy.tag import Kkma
kkma = Kkma()
kkma.sentences()
kkma.nouns()
kkma.pos()from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.nouns()
hannanum.morphs()
hannanum.pos()from konlpy.tag import Okt
t = Okt()
t.nouns()
t.morphs()
t.pos()2. 워드클라우드
from wordcloud import WordCloud, STOPWORDS
from PIL import Image
import numpy as np
import platform
import matplotlib.pyplot as plt
from matplotlib import rc
rc("font", family='Malgun Gothic')2-1. 이상한 나라의 엘리스
text = open('경로').read()
alice_mask = np.array(Image.open('경로'))
stopwords = set(STOPWORDS)
stopwords.add('said')본문에서 많이 등장하는 단어 said는 stopword 처리한다.
# 앨리스 그리기
plt.figure(figsize=(8, 8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis('off')
plt.show()wc = WordCloud(background_color='white', max_words=2000, mask=alice_mask,
stopwords=stopwords)
wc = wc.generate(text)
wc.words_
>>>
{'Alice': 1.0,
'little': 0.29508196721311475,
'one': 0.27595628415300544, ...WorldCloud 모듈 : 단어를 추출해서 빈도수를 조사하고 정규화하는 기능
Alice = 1 일 때 상대적 빈도를 나타낸다.
plt.figure(figsize=(12, 12))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
2-2. 스타워즈
text = open('경로').read()
text = text.replace('HAN', 'Han')
text = text.replace("LUKE's", "Luke")
mask = np.array(Image.open('경로'))
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')
wc = WordCloud(max_words=1000, mask=mask,
stopwords=stopwords, margin=10).generate(text)default_colors = wc.to_array()
import random
# 사진 속 글자가 그레이톤이 되도록 색상 함수 정의
def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)plt.figure(figsize=(12, 12))
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=13), interpolation='bilinear')
plt.axis('off')
plt.show()
3. 육아휴직관련법안 분석
KoNLPy는 대한민국 법령을 가지고 있다.
from konlpy.corpus import kobill
# 국회 제 1809890호 의안
doc_ko = kobill.open('1809890.txt').read()
t = Okt()
tokens_ko = t.nouns(doc_ko)
ko = nltk.Text(tokens_ko, name='대한민국 국회 의안 제 1809890호')type(ko) # nltk.text.Text
len(ko.tokens) # 735
len(set(ko.tokens)) # 250
ko.vocab() # FreqDist({'육아휴직': 38, '발생': 19, '만': 18, ...})# 불용어 추가
stop_words = ['.', ',', '(', ')', "'", '%', '-', 'X', ').', 'x', '의',
'자', '에', '안', '번', '호', '을', '다', '만', '로', '가', '를']
ko.tokens = [each_word for each_word in ko if each_word not in stop_words]이때 ko 변수가 아니라 ko.tokens에 불용어를 제거한 리스트를 넣어줘야 한다.
한국어 불용어 참고
plt.figure(figsize=(12, 6))
ko.plot(50)
plt.show()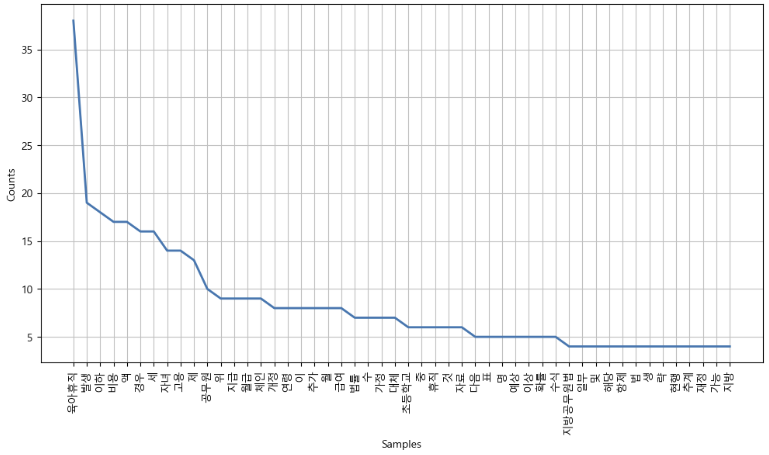
# 여러가지 기능들
plt.figure(figsize=(12, 6))
ko.dispersion_plot(['육아휴직', '초등학교', '공무원'])
ko.count('초등학교')
ko.concordance('초등학교')
# 연어(collocation) : 같이 쓰이는 단어의 조합
ko.collocations()data = ko.vocab().most_common(150)
wordcloud = WordCloud(font_path='c:/Windows/Fonts/malgun.ttf',
relative_scaling=0.2,
background_color='white').generate_from_frequencies(dict(data))
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
