1. Boosting Algorithm
- 앙상블(ensemble) 분류 : Voting, Bagging, Boosting, Stacking 등
- Voting, Bagging ➡ 투표를 통해 최종 예측 결과를 결정
- Boosting ➡ 여러 개의 약한 분류기가 순차적으로 학습을 하면서, 앞에서 학습한 분류기가 틀리게 예측한 데이터에 대해 다음 분류기가 가중치를 인가해서 학습
* 약한 분류기 = 성능은 떨어지나 속도가 빠른 분류기 - Bagging은 한 번에 병렬적으로 결과를 얻으나, Boosting은 순차적으로 학습
- 예) Adaboost
2. 여러가지 모델 적용하기
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
sc = StandardScaler()
X_sc = sc.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_sc, y,
test_size=0.2, random_state=13)import matplotlib.pyplot as plt
wine.hist(bins=10, figsize=(15, 10))
plt.show()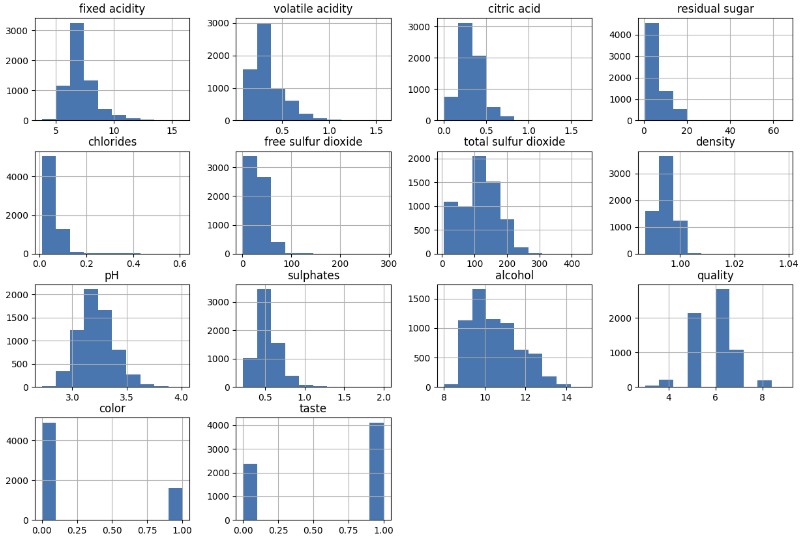
잘 분포되어 있는 컬럼이 좋을 때가 많다.
# quality 특성과 다른 특성들 사이의 상관관계 확인
column_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
corr_matrix = wine.corr()
corr_matrix['quality'].sort_values(ascending=False)
>>>
quality 1.000000
taste 0.814484
alcohol 0.444319
citric acid 0.085532
free sulfur dioxide 0.055463
sulphates 0.038485
pH 0.019506
residual sugar -0.036980
total sulfur dioxide -0.041385
fixed acidity -0.076743
color -0.119323
chlorides -0.200666
volatile acidity -0.265699
density -0.305858앞서 배운 알고리즘을 모두 적용해본다.
from sklearn.ensemble import (AdaBoostClassifier, GradientBoostingClassifier,
RandomForestClassifier)
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))%%time
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train,
cv=kfold, scoring='accuracy')
names.append(name)
results.append(cv_results)
print(name, cv_results.mean(), cv_results.std())
>>>
RandomForestClassifier 0.8187358406752054 0.017552845462398128
DecisionTreeClassifier 0.7550497889982971 0.009313993560513668
AdaBoostClassifier 0.7533103205745169 0.02644765901536818
GradientBoostingClassifier 0.7667807433182794 0.021938613967147785
LogisticRegression 0.74273191678389 0.015548839626296565results
>>>
[array([0.82307692, 0.84423077, 0.79499519, 0.82771896, 0.80365736]),
array([0.75576923, 0.76057692, 0.75264678, 0.76708373, 0.73917228]),
array([0.74903846, 0.80384615, 0.72666025, 0.74687199, 0.74013474]),
array([0.77019231, 0.80384615, 0.73820982, 0.76900866, 0.75264678]),
array([0.73461538, 0.77307692, 0.73435996, 0.74109721, 0.73051011])]# cross-validation 결과 시각화
fig = plt.figure(figsize=(14, 8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()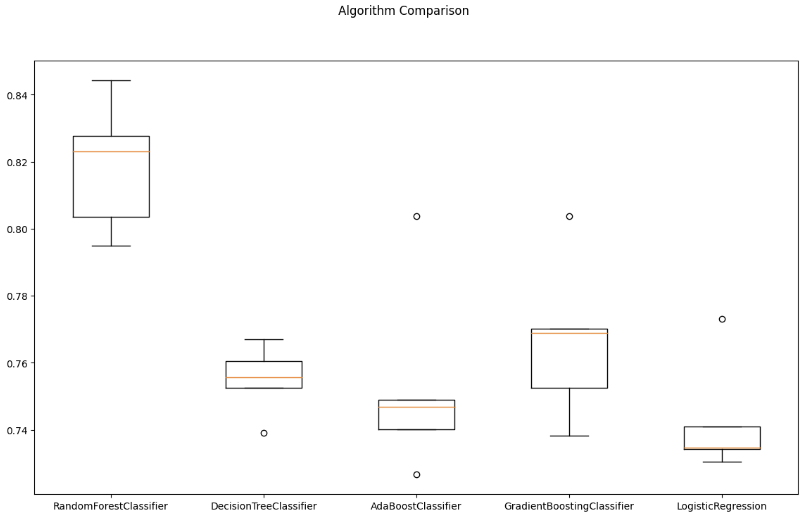
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))
>>>
RandomForestClassifier 0.8307692307692308
DecisionTreeClassifier 0.7661538461538462
AdaBoostClassifier 0.7553846153846154
GradientBoostingClassifier 0.7884615384615384
LogisticRegression 0.7469230769230769테스트 세트에 적용해봐도 RandomForestClassifier 결과가 가장 좋다.
3. kNN(k Nearest Neighbor)
- 새로운 데이터가 기존 데이터의 그룹 중 어디에 속하는지 분류하는 문제
- k는 몇 번째 가까운 데이터까지 볼 것인지 정하는 수치
- 거리 계산 ➡ 유클리드 기하
- 단위가 영향을 주기 때문에 표준화해야 함
- 실시간 예측을 위한 학습이 필요하지 않아서 속도가 빠르지만, 고차원 데이터에는 적합하지 않음(컬럼 숫자가 많을 때)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
stratify=iris.target,
test_size=0.2, random_state=13)from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train) # 사이킷런 절차상 fit, 실제로는 학습할 게 없음
pred = knn.predict(X_test)
accuracy_score(y_test, pred)
>>>
0.9666666666666667from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
>>>
[[10 0 0]
[ 0 9 1]
[ 0 0 10]]
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 0.90 0.95 10
2 0.91 1.00 0.95 10
accuracy 0.97 30
macro avg 0.97 0.97 0.97 30
weighted avg 0.97 0.97 0.97 304. GBM, XGBoost, LGBM
4-1. GBM(Gradient Boosting Machine)
Adaboost 기법과 유사하나 가중치를 업데이트할 때 경사하강법(Gradient Descent) 사용
# HAR 데이터
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
print(f'ACC : {accuracy_score(y_test, gb_pred)}')
print(f'FIT TIME : {time.time() - start_time}')
>>>
ACC : 0.9389209365456397
FIT TIME : 1074.379422903061# 오래 걸려서 실행은 하지 않음
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [100, 500],
'learning_rate': [0.05, 0.1]
}
start_time = time.time()
grid = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1, n_jobs=-1)
grid.fit(X_train, y_train)
print(f'FIT TIME : {time.time() - start_time}')4-2. XGBoost(eXtra Gradient Boost)
- GBM 기반 알고리즘으로, GBM의 느린 속도를 다양한 규제를 통해 해결함
- 병렬 학습 가능
- 반복 수행할 때마다 내부적으로 학습 데이터와 검증 데이터를 교차검증함
- 교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능이 있음
- XGBoost 모듈은 판다스와 잘 연동되지 않아서 넘파이 array 형태를 사용해야 함
pip install xgboostfrom sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
le = LabelEncoder()
y_train = le.fit_transform(y_train)
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train)
y_pred = xgb.predict(X_test)
y_pred = le.inverse_transform(y_pred)
print(f'ACC : {accuracy_score(y_test, y_pred)}')
print(f'FIT TIME : {time.time() - start_time}')
>>>
ACC : 0.9497794367153037
FIT TIME : 95.94628739356995# 조기 종료 조건, 검증 데이터 지정
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)
evals = [(X_test.values, y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
# early_stopping_round : 같은 성능으로 n번 이상 반복해서 비슷한 성능이 나오면 종료
xgb.fit(X_train.values, y_train, early_stopping_rounds=10, eval_set=evals)
y_pred = xgb.predict(X_test)
print(f'ACC : {accuracy_score(y_test, y_pred)}')
print(f'FIT TIME : {time.time() - start_time}')
>>>
ACC : 0.9453681710213777
FIT TIME : 65.52740597724915❗Error
ValueError: Invalid classes inferred from unique values of
y. Expected: [0 1 2 3 4 5], got [1 2 3 4 5 6]
XGBoostError: [02:28:05] /workspace/src/metric/multiclass_metric.cu:35: Check failed: label_error >= 0 && label_error < static_cast<int32_t>(n_class): MultiClassEvaluation: label must be in [0, num_class), num_class=6 but found 6 in label]
➡ 두 에러 모두 이 방법으로 해결할 수 있다.
# LabelEncoder 적용 전
np.unique(y_train) ➡ array([1, 2, 3, 4, 5, 6])
# LabelEncoder 적용 후
np.unique(y_train) ➡ array([0, 1, 2, 3, 4, 5])모델 훈련하고 나서 예측할 때 inverse_transform()을 적용하지 않으면 결과를 제대로 확인할 수 없다.
y_pred = xgb.predict(X_test)
np.unique(y_pred) ➡ array([0, 1, 2, 3, 4, 5])
accuracy_score(y_test, y_pred) ➡ 0.024092297251442144 ❓❓
# y_test의 배열을 확인해보면 원인을 알 수 있다.
np.unique(y_test) ➡ array([1, 2, 3, 4, 5, 6])
# inverse_transform() 적용
y_pred = le.inverse_transform(y_pred)
np.unique(y_pred) ➡ array([1, 2, 3, 4, 5, 6])
# 결과 확인
accuracy_score(y_test, y_pred) ➡ 0.94977943671530374-3. LightGBM
- 속도가 빠름
- 적은 수의 데이터에는 적합하지 않음(대략 10,000건 이상의 데이터일 때)
conda install lightgbm
# 에러 발생하면
pip install lightgbmfrom lightgbm import LGBMClassifier, early_stopping
evals = [(X_test.values, y_test)]
start_time = time.time()
lgbm = LGBMClassifier(n_estimators=400)
lgbm.fit(X_train.values, y_train, eval_set=evals,
callbacks=[early_stopping(stopping_rounds=20)])
y_pred = lgbm.predict(X_test.values)
print(f'ACC : {accuracy_score(y_test, y_pred)}')
print(f'FIT TIME : {time.time() - start_time}')
>>>
ACC : 0.9260264675941635
FIT TIME : 40.64116811752319early_stopping_rounds 매개변수 대신에 lightgbm.early_stopping을 사용해야 한다.
