JSON 데이터로 데이터프레임 만들기
import json
with open('경로', 'r', encoding='utf-8') as f:
json_data = json.load(f)
# 내용 확인 후 필요한 내용만 가지고 데이터프레임 만들기
df_target = pd.DataFrame(json_data['records'])NULL값 확인하기
데이터의 null값이 ""로 구성되어 info()나 isna() 등을 이용하여 null값을 확인할 경우 null값이 없다고 나온다. ➡ ""을 Null값으로 대체하여 데이터를 제대로 확인할 수 있다.
df_target = df_target.replace('', None)관람료 이상치 판단하기
관람료가 10원 단위로 나누어 떨어지지 않거나, 100,000원 이상인 경우 이상치로 판단하여 행을 삭제한다.
for col in type_int_col:
df_target.drop(df_target[(df_target[col] % 10 != 0) |
(df_target[col] >= 100000)].index, inplace=True)휴관 중이거나 중복된 데이터 삭제하기
# 시설명 컬럼에 '휴관'이 있는 경우
df_target.drop(df_target[df_target['시설명'].str.contains('휴관')].index, inplace=True)
# 시설명 컬럼의 데이터가 중복되는 경우 - 데이터 기준일자가 최신인 데이터만 남기기
df_target.sort_values(by='데이터기준일자', ascending=False, inplace=True)
df_target = df_target[~df_target.duplicated(['시설명'])]
# 시설명 컬럼의 띄어쓰기를 삭제한 값이 일치할 경우 중복으로 판단 - 최신 데이터만 남기기
df_target = df_target[~df_target['시설명'].str.replace(' ', '').duplicated()]
# 앞서 순서를 변경하였다면, 다시 Index 순서로 정렬
df_target = df_target.sort_index()🔥 관람가능시간 컬럼 만들기
시간이 : 을 기준으로 나눠진 것을 이용했다.
time_cols = ['평일관람시작시각', '평일관람종료시각', '공휴일관람시작시각', '공휴일관람종료시각']
for idx, row in df_target[time_cols].iterrows():
open_hour, open_min = map(int, row.평일관람시작시각.split(':'))
close_hour, close_min = map(int, row.평일관람종료시각.split(':'))
total = (close_hour - open_hour) + round((close_min - open_min) / 60, 2)
df_target.loc[idx, '평일관람가능시간'] = 24 if total > 23 else total
open_hour, open_min = map(int, row.공휴일관람시작시각.split(':'))
close_hour, close_min = map(int, row.공휴일관람종료시각.split(':'))
total = (close_hour - open_hour) + round((close_min - open_min) / 60, 2)
df_target.loc[idx, '공휴일관람가능시간'] = 24 if total > 23 else total소재지도로명주소 컬럼의 데이터를 가공하여 광역-기초-상세로 구분하기
for idx, value in df_target['소재지도로명주소'].items():
if '세종특별' in value:
wide = '세종특별자치시'
basic = None
detail = tuple(value.split(' ', 1))[1]
else:
wide, basic, detail = tuple(value.split(' ', 2))
df_target.loc[idx, '광역'] = wide
df_target.loc[idx, '기초'] = basic
df_target.loc[idx, '상세'] = detail4-1. 광역자치단체별 박물관/미술관 총 수 확인하기
province_dict = {'서울특별시': 0, ... }
df_result = df_target.groupby('광역').size().to_frame(name='박물관미술관수')
df_result = df_result.sort_index(key=lambda x: x.map(province_dict))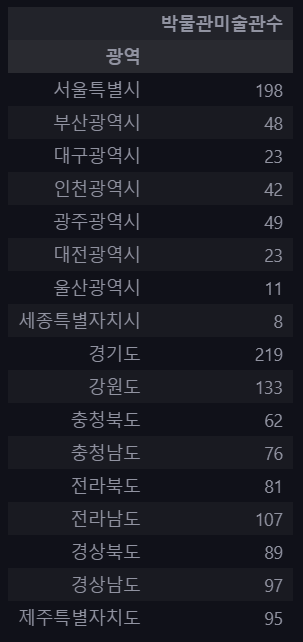
🔥 4-2. 광역자치단체-기초자치단체의 박물관/미술관의 총 수가 8개인 광역-기초자치단체 확인하기
dropna=False 옵션을 넣지 않으면 기초 컬럼 값이 NULL인 세종이 빠진다.😇
실행 순서가 중요하다는 것도 알게 된 문제...
df_result = df_target.groupby(['광역', '기초'], dropna=False).size().to_frame(name='박물관미술관수')
df_result = df_result[df_result['박물관미술관수'] == 8]
df_result = df_result.sort_index(level=1, ascending=False).sort_index(level=0, key=lambda x: x.map(province_dict), sort_remaining=False)
df_result = df_result.reset_index()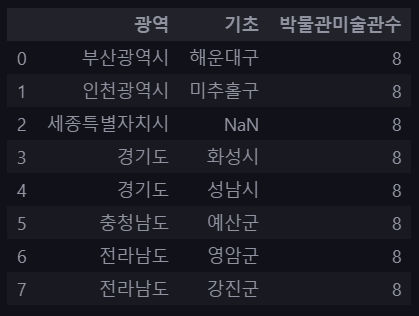
4-3. 광역자치단체-박물관미술관구분(사립, 국립, 공립, 대학)의 평균 관람료 차이 알아보기
df_result = df_target[~((df_target['어른관람료'] == 0) | (df_target['어린이관람료'] == 0))]
df_result = df_result.pivot_table(index=['광역', '박물관미술관구분'],
values=['어른관람료', '어린이관람료'],
aggfunc='mean')
df_result = df_result.apply(lambda x: round(x, -1))df_result['어른관람료'] = df_result['어른관람료'].astype(int)
df_result['어린이관람료'] = df_result['어린이관람료'].astype(int)
df_result['관람료차이'] = df_result['어른관람료'] - df_result['어린이관람료']
df_result = df_result[(df_result['관람료차이'] == df_result['관람료차이'].min()) |
(df_result['관람료차이'] == df_result['관람료차이'].max())]
4-4. 가족(어른2, 청소년1, 어린이1)이 공휴일에 제주특별자치도 제주시에 있는 미술관을 관람하려 한다. 총 관람료가 2만원 이하, 공휴일 4시간 이상 관람 가능한 미술관은?
money = (df_target['어른관람료'] * 2 + df_target['청소년관람료'] + df_target['어린이관람료']) <= 20000
location = df_target['기초'] == '제주시'
gallery = df_target['시설명'].str.contains('미술관|갤러리|아트')
holiday = df_target['공휴일관람가능시간'] >= 4
df_result = df_target[money & location & gallery & holiday]