pycountry 모듈 설치
pip install pycountry- ISO 3166-2(전 세계 나라 및 부속 영토의 주요 구성 단위의 명칭에 고유 부호/코드를 부여하는 국제 표준) 기준 국가별 코드를 얻을 수 있는 라이브러리
- 국가명 표기 방식에 따라 잘못된 값 또는 값 검색이 안되는 경우가 많음
- 예를 들어 대한민국은 'south korea', 'republic of korea', 'korea', 'korea, republic of' 등으로 표기되지만, pycountry를 사용할 때 'korea, republic of' 로만 정확한 국가 코드를 얻을 수 있음
사용한 모듈
import pandas as pd
import numpy as np
import pycountry1. 데이터 전처리
# 데이터 가져오기
df_target = pd.read_csv('경로')
# 불필요한 컬럼 제거
df_target = df_target.dropna(subset=['incomeperperson', 'internetuserate', 'urbanrate'])# pycountry 사용하기 위해 국가명 변경
df_target_change_list = [(33, 'Cabo Verde'), ...]
for value in df_target_change_list:
for idx, row in df_target.iterrows():
if idx == value[0]:
df_target.loc[idx, 'country'] = value[1]
# pycountry 모듈로 국가코드 가져오기
df_target = df_target.copy()
for idx, row in df_target.iterrows():
country_name = df_target.loc[idx, 'country']
# 터키 국가명이 튀크키예로 변경됨
if country_name == 'Turkey':
country_name = 'Türkiye'
# 일반 검색 실패하면 fuzzy 검색
try:
df_target.loc[idx, 'code'] = pycountry.countries.get(name=country_name).alpha_2
except Exception as e:
df_target.loc[idx, 'code'] = pycountry.countries.search_fuzzy(country_name)[0].alpha_2SettingWithCopyWarning 경고를 해결하기 위해 df_target을 copy해서 사용했다.
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.
2. 첫 번째 reference data 전처리 및 합치기
2-1. 전처리
# 링크에 있는 테이블을 데이터프레임으로 가져오기
url = 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population'
df_pupulation = pd.read_html(url, header = 0)[0]
# 불필요한 컬럼 삭제
df_pupulation.drop(['Unnamed: 0', '% of world', 'Date', 'Source (official or from the United Nations)', 'Unnamed: 6'], axis=1, inplace=True)
# 컬럼명 변경
df_pupulation.rename(columns={'Country / Dependency': 'country', 'Population': 'population'}, inplace=True)
# 국가명 변경
df_population_change_dict = {'Bermuda (United Kingdom)': 'Bermuda', ...}
df_pupulation['country'] = df_pupulation['country'].replace(df_population_change_dict)2-2. 합치기
이 상태에서 바로 df_target, df_pupulation을 merge 했더니 계속 오답이 나와서 country가 겹치지 않는 국가를 확인해봤다.
# country가 겹치지 않는 국가 확인
tar_uni = df_target['country'].unique()
pop_uni = df_pupulation['country'].unique()
for value in tar_uni:
if value not in pop_uni:
print(value)
>>>
Bermuda
Puerto Rico위키 문서에는 두 국가명 뒤에 (UK), (US)가 붙어 있어서 같은 것으로 인식하지 못하고 병합 대상에서 제외된다. 국가명을 수정하여 누락되지 않도록 했다.
# ()때문에 국가명이 일치하지 않은 것으로 간주되어 수정
df_pupulation.loc[df_pupulation['country'] == 'Bermuda (UK)', 'country'] = 'Bermuda'
df_pupulation.loc[df_pupulation['country'] == 'Puerto Rico (US)', 'country'] = 'Puerto Rico'# 데이터프레임 합치기
df = pd.merge(df_target, df_pupulation, on='country', how='inner').sort_values(by='code').reset_index(drop=True)3. 두 번째 reference data 전처리 및 합치기
3-1. 전처리
# 데이터 가져오기
df_region = pd.read_csv('경로')
# Namibia의 국가코드 변경
df_region.loc[df_region['name'] == 'Namibia', 'alpha-2'] = 'NA'
# 불필요한 컬럼 삭제
df_region_drop_col = ['country-code', ...]
df_region.drop(columns=df_region_drop_col, axis=1, inplace=True)
# 컬럼명 변경
df_region_rename_dict = {'alpha-2': 'code', ...}
df_region.rename(columns=df_region_rename_dict, inplace=True)3-2. 합치기
# 데이터프레임 합치기
df_merge = pd.merge(df, df_region, on='code', how='inner').sort_values(by='code')
# 컬럼명 변경
df_rename_dict = {'incomeperperson': 'income_per_person', ...}
df_merge.rename(columns=df_rename_dict, inplace=True)
# 불필요한 컬럼 삭제
df_drop_col = ['name']
df_merge.drop(columns=df_drop_col, axis=1, inplace=True)
# 컬럼 순서 변경
new_col_order = ['code', ...]
df_merge = df_merge[new_col_order]
# 인덱스 재설정
df_merge.reset_index(drop=True, inplace=True)4. 데이터 분석하기(가중 평균) 🔥
별 두개가 4번 문제에 집중되어 있는 것 같다.
✨numpy.average
가중평균을 구하기 위해서 numpy.average() 함수를 사용했다.
- a : array_like
평균을 계산할 데이터가 포함된 배열 - axis : None or int or tuple of ints, optional
평균을 계산할 축 - weights : array_like, optional
a의 값과 연관된 가중치 배열로, 1차원이거나 a와 동일한 모양
4-1. 지역대륙별 가중 평균 구하기
문제 : 국가별 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 대륙(region) 또는 지역대륙(sub_region)별로 평균을 합산하여 보기 위해서 국가별 인구수(population)을 가중한 평균을 계산하세요.
(가중치는 population 컬럼 이용)
# internet_use_rate 컬럼의 가중평균 계산하는 함수
def get_weighted_avg(df):
return np.average(df['internet_use_rate'], weights=df['population'])
# 각 그룹에 get_weighted_avg 함수를 적용하고 데이터프레임으로 변환
df_result = df_merge.groupby(['region', 'sub_region']).apply(get_weighted_avg).to_frame()# income_per_person 컬럼의 가중평균 계산하는 함수
def get_weighted_avg(df):
return np.average(df['income_per_person'], weights=df['population'])
# 각 그룹에 get_weighted_avg 함수를 적용하고 df_result에 추가
df_income = df_merge.groupby(['region', 'sub_region']).apply(get_weighted_avg)
df_result['weighted_ave_income'] = df_income
# 컬럼명 변경
df_result.rename(columns={0: 'weighted_ave_internet'}, inplace=True)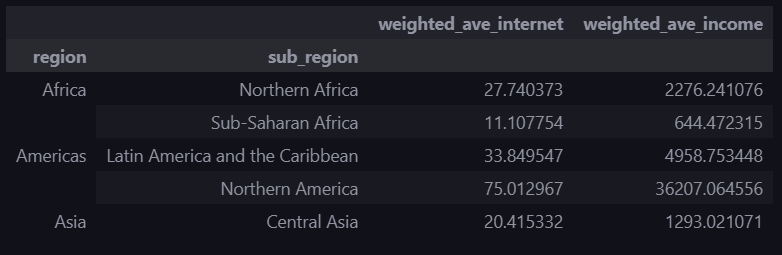
4-2. 특정 조건의 가중 평균 구하기
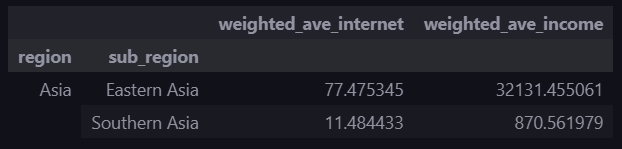
문제 : 중국('CN')과 인도('IN')를 제외한 Eastern Asia, Southern Asia의 인터넷 사용률(internet_use_rate) 및 인당 소득(income_per_person)을 구하세요.
(가중치는 population 컬럼 이용)
# 필요한 행만 가져오기
target = df_merge.copy()[df_merge['sub_region'].isin(['Eastern Asia', 'Southern Asia'])]
# 중국과 인도 제외
drop_index = target[target['code'].isin(['CN', 'IN'])].index
target.drop(drop_index, inplace=True)# internet_use_rate 컬럼의 가중평균 계산하는 함수
def get_weighted_avg(df):
return np.average(df['internet_use_rate'], weights=df['population'])
# 각 그룹에 get_weighted_avg 함수를 적용하고 데이터프레임으로 변환
df_result = target.groupby(['region', 'sub_region']).apply(get_weighted_avg).to_frame()# income_per_person 컬럼의 가중평균 계산하는 함수
def get_weighted_avg(df):
return np.average(df['income_per_person'], weights=df['population'])
# 각 그룹에 get_weighted_avg 함수를 적용하고 df_result에 추가
df_income = target.groupby(['region', 'sub_region']).apply(get_weighted_avg)
df_result['weighted_ave_income'] = df_income
# 컬럼명 변경
df_result.rename(columns={0: 'weighted_ave_internet'}, inplace=True)