데이터 과학을 어떤 현상, 인식, 가정을 확인하는 도구로 사용해보자!
0. 데이터 찾기
기사 : https://www.news1.kr/articles/?1911504
실제로 강남 3구가 범죄로부터 안전하다고 말할 수 있을까?
🍳 서울시 관서별 5대 범죄 현황 데이터
https://data.seoul.go.kr/dataList/316/S/2/datasetView.do
1. 데이터 읽기 - thousands 옵션
천 단위 이상 숫자에 콤마가 사용된 경우 문자열로 인식할 수 있다.
thousands 옵션을 넣어주면 콤마를 제거하고 숫자형으로 읽는다.
pd.read_csv( ... , thousands=",", ... )2. NaN 값이 들어있는 데이터 정리
RangeIndex = 65534, 데이터 수 = 310개
문제점을 파악하기 위해 "죄종" 컬럼을 확인해보니 nan 값이 들어 있다.
crime_raw_data["죄종"].unique()"죄종" 컬럼에 null값이 얼마나 들어있는지 확인
crime_raw_data["죄종"].isnull()
"죄종" 컬럼에 null값이 들어있지 않은 데이터만 사용
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]3. 구별로 데이터 정리 - 피벗 테이블 적용
관서별 데이터를 구별로 정리하려면?
crime_station = crime_raw_data.pivot_table(
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum])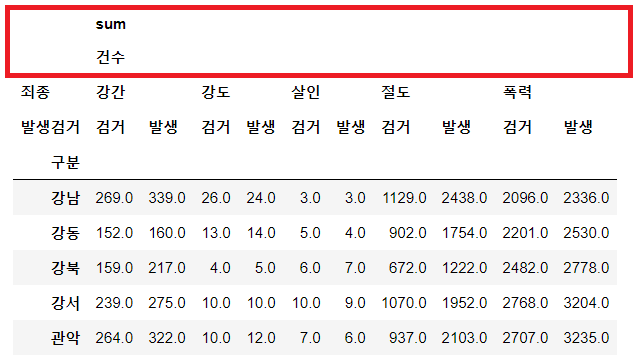
sum과 건수 컬럼은 불필요하다.
# 컬럼 확인하기: MultiIndex
crime_station.columns
# 접근하기
crime_station["sum", "건수", "강도", "검거"][:5]
# 제거하고 싶은 인덱스 번호를 넘겨줌
crime_station.columns = crime_station.columns.droplevel([0, 1])✨pandas pivot_table
https://pandas.pydata.org/docs/reference/api/pandas.pivot_table.html
❗ Error
엑셀 데이터를 읽어올 때 발생했다.
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.
➡ 하라는 대로 했다.
conda install openpyxl
df.pivot_table의 매개변수
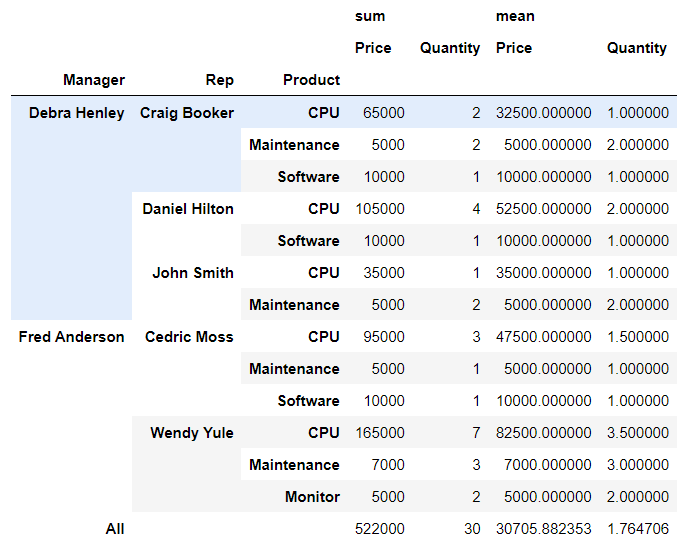
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True)- index, values, columns, aggfunc(기본값=평균), ...
- fill_value 옵션으로 NaN에 원하는 값을 넣을 수 있음
❗ Error
TypeError: Could not convert John Smith to numeric
➡ 집계 가능한 열만 선택해서 지정해주니 잘 실행된다.
df.info()에서 'Dtype=숫자'인 것만 cols에 담아 values 값에 넣어준다.
cols = ["Account", "Quantity", "Price"]
pd.pivot_table(df, index="Name", values=cols)⚙Python 모듈 설치
pip 명령
Python의 공식 모듈 관리자
pip list # 현재 설치된 모듈 리스트 반환
pip install module_name # 모듈 설치
pip uninstall module_name # 설치된 모듈 제거주피터 노트북에서는...
!pip list # !를 사용하면 OS레벨의 명령을 쓸 수 있음
get_ipython().system("pip list")
conda 명령
pip를 사용하면 conda 환경에서 dependency 관리가 정확하지 않을 수 있기 때문에, Anaconda에서는 conda 명령으로 모듈을 관리하는 게 좋다.
그러나 모든 모듈이 conda로 설치되는 건 아니다.(검색)
conda list # 현재 설치된 모듈 리스트 반환
conda install module_name # 모듈 설치
conda uninstall module_name # 설치된 모듈 제거
# 지정된 배포 채널에서 모듈 설치
conda install -c channel_name module_name🔥CCTV 퀴즈 오답노트
numpy 모듈 명령어 중 a부터 b까지 n의 간격으로 데이터를 만드는 명령어는?
1. array
2. linspace (내가 고른 답)
3. arange (정답)
4. average
linspace 공식 문서를 보면 arange와의 차이점도 같이 알려준다.
https://numpy.org/doc/stable/reference/generated/numpy.linspace.html
- Return evenly spaced numbers over a specified interval
- arange - Similar to linspace, but uses a step size (instead of the number of samples).
linspace는 샘플 수를 정해주면 "균등한 간격"으로 숫자를 반환하고, arange는 사용자가 간격을 설정할 수 있다.
