📙iris 데이터를 활용한 분류 실습
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inlinefrom sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
X.shape, y.shape((150, 4), (150,))yarray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])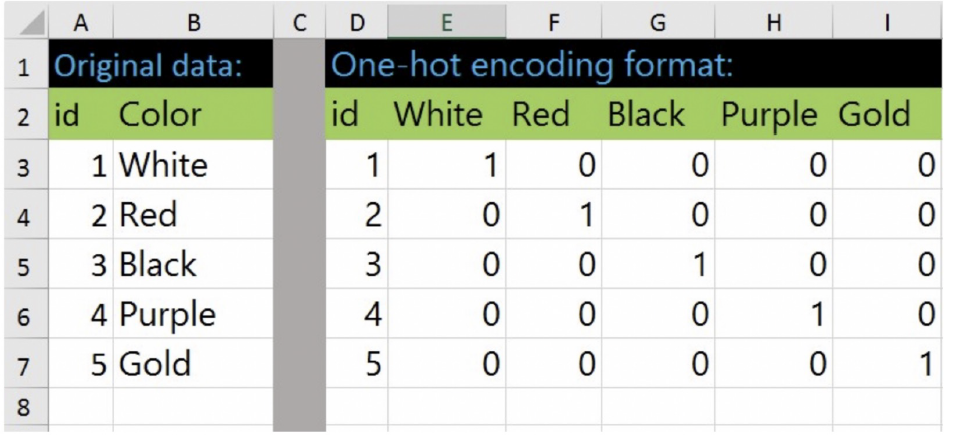
수치로 된 범주형을 예측하는 경우, 편향된 결과를 얻을 수 있기 때문에 One Hot Encoding을 사용.
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
enc.categories_[array([0, 1, 2])]y_onehot = enc.transform(y.reshape(len(y), 1))
y_onehot[:3]array([[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.]])# 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2,random_state=13)iris를 구상하는 망 (net)
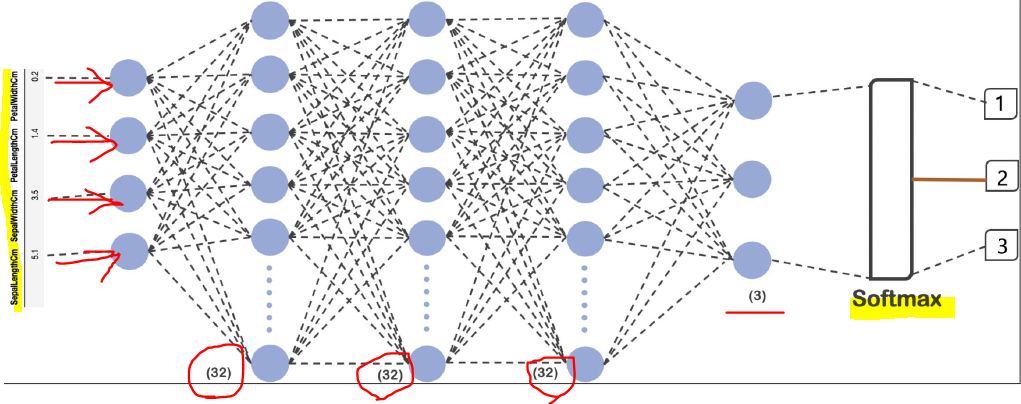
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4, ), activation='relu'), #activation func 필수로 있어야함.
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
-
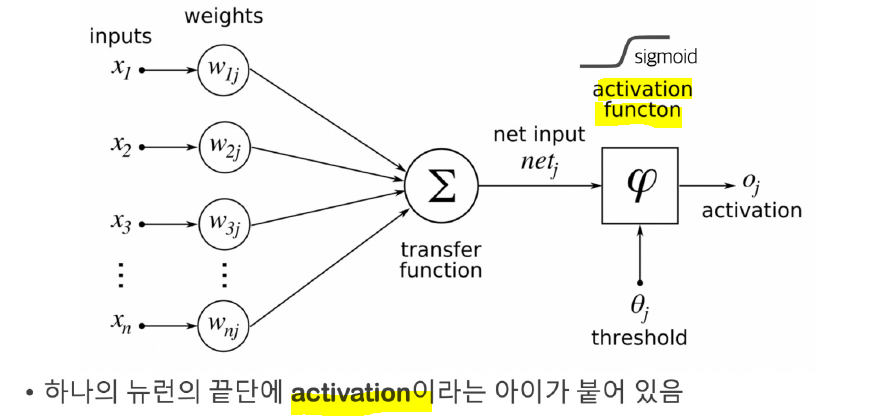
activation: 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달하는데 이 때 사용하는 함수를 말한다.
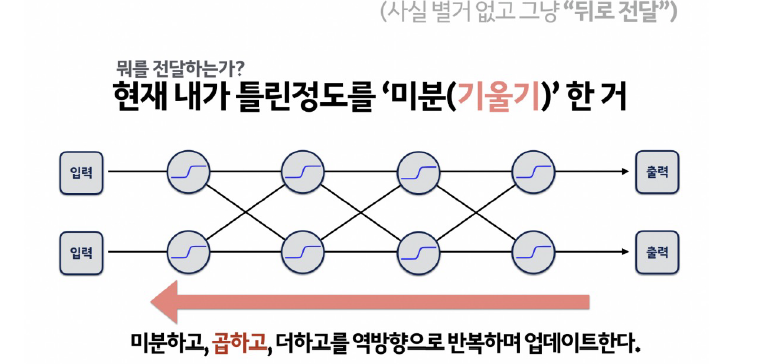
layer가 여러개일 수록 에러에 대한 계산이 어려워 지는데, 이를 극복한 방법이 오차 역전파 -
역전파(Back-Propagation): 뉴럴 네트워크의 파라미터들에 대한 그래디언트(gradient)를 계산하는 방법
- target과 모델이 계산한 output이 얼마나 차이가 나는지 구한 후 그 오차값을 뒤로 전파해가며 변수들을 갱신한다.
-
sigmoid의 경우 역전파에서 발생하는 문제가 있다.
특정 부분의 경우 기울기가 0이므로 뒤로 전달할 값이 없게된다.
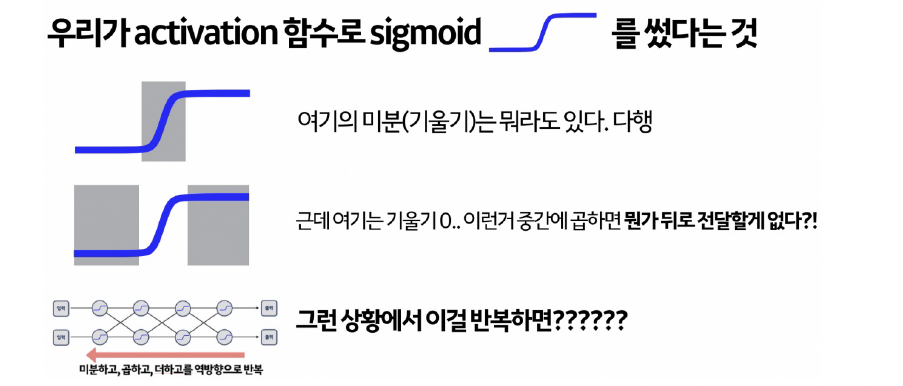
결국 gradient vanishing 기울기 소실 문제가 발생한다.
Gradient Vanishing현상 : 레이어가 깊을 수록 업데이트가 사라지는 현상으로 따라서 fitting이 잘되지 않는다.(underfitting). 입력에 가까울 수록 학습이 잘 안된다.
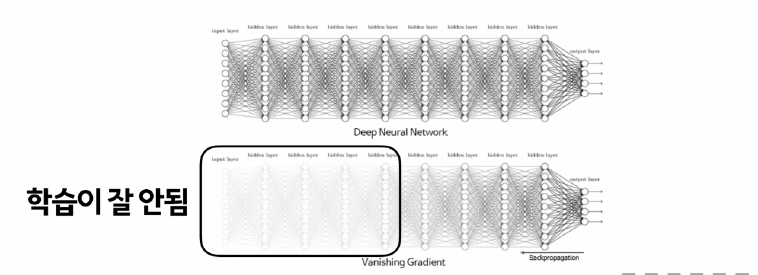
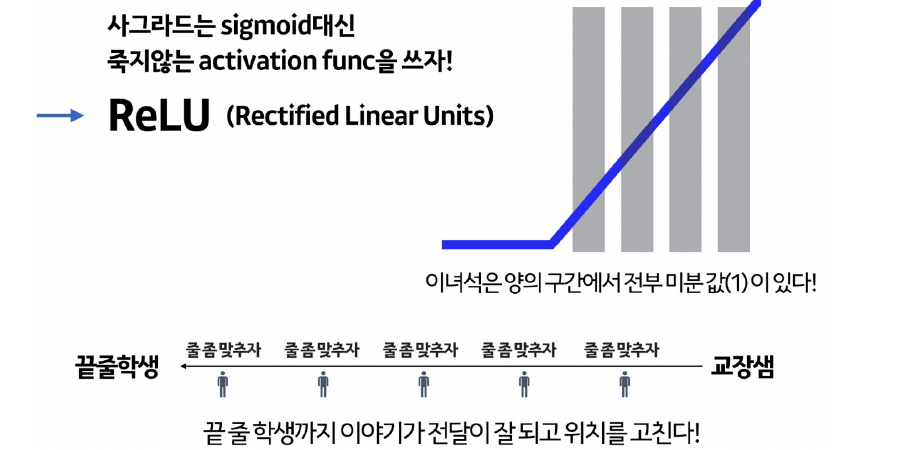
ReLU(Rectified Linear Units): 입력값이 0보다 작으면 0으로 출력, 0보다 크면 입력값 그대로 출력하는 유닛이다.
점점 소멸되는 시그모이드 대신 은닉층의 경우 대부분 ReLU를 사용한다.
softmax: 각각의 확률을 계산하고 이를 합한 값이 1

✏ 기존 뉴럴넷이 가중치들을 최적화하는 방법
Gradient Decent: loss function의 현 가중치에서의 기울기(gradient)를 구해서 loss를 줄이는 방향으로 업데이트해 나간다.
뉴럴넷은 loss(or cost) function을 가지고 있다. 거기서 미분하여 에러를 줄이는 방향을 알 수 있다.(현재 기울기 * 반대방향)
정해진 스텝량(learning rate)을 곱해서 weight를 이동시킨다.
❗단점 : 모든 데이터를 읽어 최적의 1스텝을 이동한다. (데이터 다 사용해서 한칸 이동)Stochastic Gradient Decent(SGD): 데이터의 일부분(batch)으로 작은 토막마다 1스텝을 진행한다.
- 시간이 오래 걸리는 GD보다 SGD를 주로 사용한다.
- SGD의 개선된 다른 optimizer도 많이 존재한다.
- GD : 모든 자료 검토
- SGD : 일부분을 보며 검토 (<- GD)
- Momentum : 스텝 방향 조절, 스텝 계산해서 움직인 후, 이전 관성 방향으로 이동 (<- SGD)
- Adagrad : 스텝 사이즈 조절, 이용하지 않은 것은 빠르게, 이용한 것은 점점 세밀하게 탐색 (<- SGD)
- NAG : 관성 방향으로 움직인 후, 움직인 자리에 스텝을 계산 (<- Momentum)
- AdaDelta : 너무 세밀하게 움직여 정지하는 것 금지 (<- Momentum)
- RMSProp : 스텝 사이즈를 조절하지만 이전 상황도 비교하며 판단 (<- Adagrad)
- Adam : RMSProp + Momentum, 방향, 스텝사이즈 적절히 조절 (<- RMSProp, Momentum)
- Nadam : Adam에 Momentum 대신 NAG 추가 (<- Adam, NAG)💡 현 시점에서는 Adam이 가장 많이 사용된다.
loss: categorical_crossentropy : 다중 분류 손실함수. 출력값이 one-hot encoding 된 결과로 나오고 실측 결과와의 비교시에도 실측 결과는 one-hot encoding 형태로 구성
model.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 32) 160
dense_5 (Dense) (None, 32) 1056
dense_6 (Dense) (None, 32) 1056
dense_7 (Dense) (None, 3) 99
=================================================================
Total params: 2,371
Trainable params: 2,371
Non-trainable params: 0
_________________________________________________________________◼ 모델 학습
hist = model.fit(X_train, y_train, epochs=100)Epoch 1/100
4/4 [==============================] - 0s 2ms/step - loss: 1.1008 - accuracy: 0.3083
Epoch 100/100
4/4 [==============================] - 0s 1000us/step - loss: 0.0755 - accuracy: 0.9750◼ 모델 평가
model.evaluate(X_test, y_test, verbose=1)1/1 [==============================] - ETA: 0s - loss: 0.1101 - accuracy: 1.00 - 0s 93ms/step - loss: 0.1101 - accuracy: 1.0000
[0.11006371676921844, 1.0]◼ loss 그래프
plt.figure(figsize=(7, 5))
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['accuracy'], label = 'accuracy')
plt.legend()
plt.grid()
plt.show()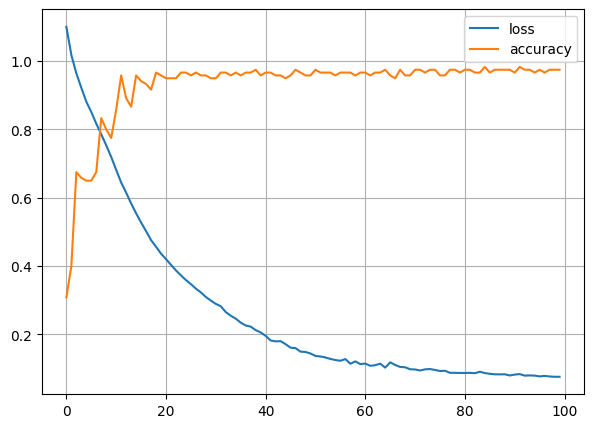

데이터분석 스터디노트🧐✍️