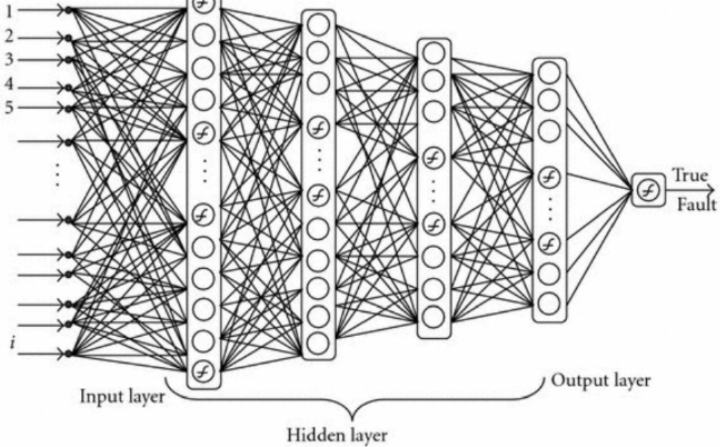
⏹ Deep Learning
Tensorflow: 머신러닝을 위한 오픈소스 플랫폼, 딥러닝 프레임워크
구글이 주도적으로 개발했으며 구글 코랩에서 기본으로 사용가능.
- Keras(고수준 API) 병합
- Tensor : 벡터나 행렬
- Graph : 텐서가 흐르는 경로(공간)
- Tensor Flow : 텐서가 Graph를 통해 흐른다.Neural Net: 신경망에서 아이디어를 얻어서 시작
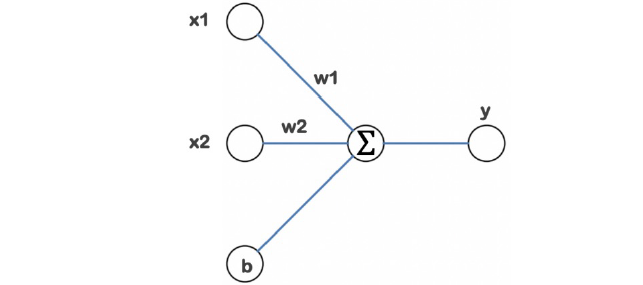
뉴런은입력, 가중치, 활성화함수, 출력으로 구성
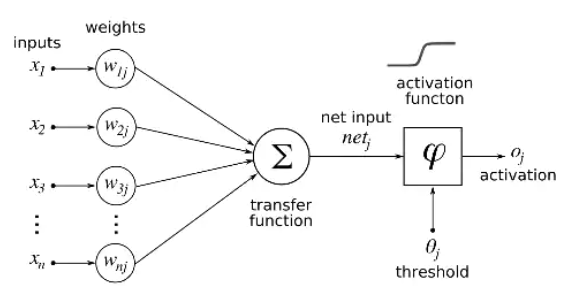
뉴런에서 학습할 때 변하는 것은 가중치, 처음에는 초기화를 통해 랜덤값을 넣고 학습과정에서 일정한 값으로 수렴
뉴런이 모여서 layer를 구성하고 망(net)이 되고,

계속 층이 쌓여 깊어지면 깊은 신경망 Deep Learning이 된다.

📙Blood Fat
import numpy as np
raw_data = np.genfromtxt('https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/x09.txt', skip_header=36)
raw_data ✔컬럼 정보
1열 : 인덱스
2열 : 구분자
3열 : 몸무게
4열 : 나이
5열 : blood fat
array([[ 1., 1., 84., 46., 354.],
[ 2., 1., 73., 20., 190.],
[ 3., 1., 65., 52., 405.],
[ 4., 1., 70., 30., 263.],
[ 5., 1., 76., 57., 451.],
[ 6., 1., 69., 25., 302.],
[ 7., 1., 63., 28., 288.],
[ 8., 1., 72., 36., 385.],
[ 9., 1., 79., 57., 402.],
[ 10., 1., 75., 44., 365.],
[ 11., 1., 27., 24., 209.],
[ 12., 1., 89., 31., 290.],
[ 13., 1., 65., 52., 346.],
[ 14., 1., 57., 23., 254.],
[ 15., 1., 59., 60., 395.],
[ 16., 1., 69., 48., 434.],
[ 17., 1., 60., 34., 220.],
[ 18., 1., 79., 51., 374.],
[ 19., 1., 75., 50., 308.],
[ 20., 1., 82., 34., 220.],
[ 21., 1., 59., 46., 311.],
[ 22., 1., 67., 23., 181.],
[ 23., 1., 85., 37., 274.],
[ 24., 1., 55., 40., 303.],
[ 25., 1., 63., 30., 244.]])from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
xs = np.array(raw_data[:,2], dtype = np.float32)
ys = np.array(raw_data[:,3], dtype = np.float32)
zs = np.array(raw_data[:,4], dtype = np.float32)fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs,ys,zs)
ax.set_xlabel('Weight')
ax.set_ylabel('Age')
ax.set_zlabel('Blood fat')
ax.view_init(15,15)
plt.show()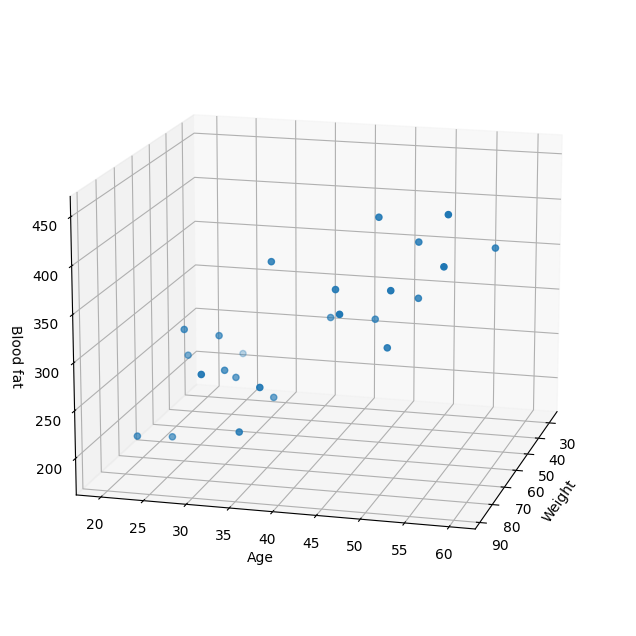
💡간단한 딥러닝 목표
입력인 나이와 몸무게를 알려주면, 주어진 데이터 기준의 blood fat을 얻는 것.
즉, 40살 100kg인 사람 데이터 기준 blood fat을 물으면 값이 나오게 하는 목표.
--> Linear Regression
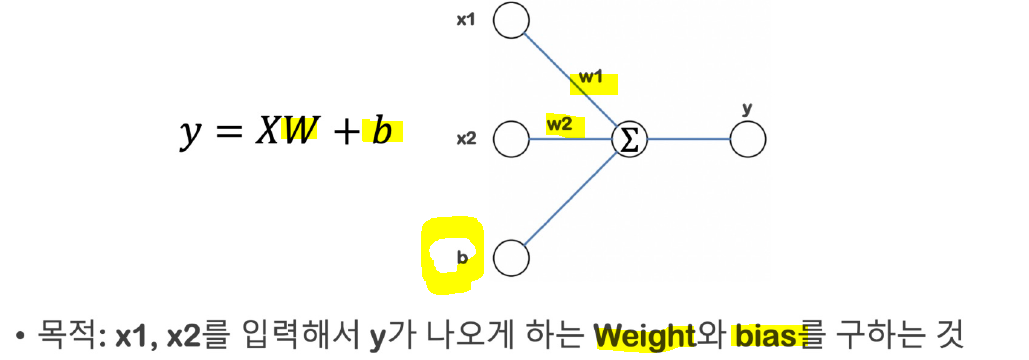
# 학습 대상 데이터
x_data = np.array(raw_data[:,2:4],dtype=np.float32)
y_data = np.array(raw_data[:,4],dtype=np.float32)
y_data = y_data.reshape((25,1)) #(25,)면 맞지않기 때문에 reshape으로 크기 맞춰주기 y_data.shape(25, 1)x_data.shape(25, 2)# 모델 만들기
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape=(2,)),
]) # 입력 shape(2,)을 정해주면 weight가 2개인 것을 알 수 있음. tf.keras 식만 보고도 어떤 구조인지 알 수 있음.
model.compile(optimizer='rmsprop',loss='mse') -
loss
학습을 위해서는 loss(cost)함수를 정해줘야 한다.(정답까지 얼마나 멀리 있는지를 측정해주는 함수).
위의 경우 mse(mean square error) 오차제곱 평균으로 사용.그런 다음 optimizer(loss를 어떻게 줄일 것인지 결정하는 방법)를 선정.
model.summary() # output 하나이고, 찾아야할 parameter 총 3개Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1) 3
=================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
_________________________________________________________________
위 모델 구성
# 모델로 학습 시키기
hist = model.fit(x_data, y_data, epochs=10) #epoch 10일때 loss 변화가 크지 않아 좋지않음을 알 수 있다.Epoch 1/10
1/1 [==============================] - 1s 548ms/step - loss: 29632.4492
Epoch 2/10
1/1 [==============================] - 0s 6ms/step - loss: 29518.6230
Epoch 3/10
1/1 [==============================] - 0s 5ms/step - loss: 29436.2773
Epoch 4/10
1/1 [==============================] - 0s 6ms/step - loss: 29367.4707
Epoch 5/10
1/1 [==============================] - 0s 6ms/step - loss: 29306.4883
Epoch 6/10
1/1 [==============================] - 0s 8ms/step - loss: 29250.6875
Epoch 7/10
1/1 [==============================] - 0s 6ms/step - loss: 29198.5996
Epoch 8/10
1/1 [==============================] - 0s 6ms/step - loss: 29149.2891
Epoch 9/10
1/1 [==============================] - 0s 7ms/step - loss: 29102.1582
Epoch 10/10
1/1 [==============================] - 0s 6ms/step - loss: 29056.7578hist = model.fit(x_data, y_data, epochs=5000) #loss 1863까지 떨어짐
Epoch 1/5000
1/1 [==============================] - 1s 548ms/step - loss: 29632.4492
Epoch 5000/5000
1/1 [==============================] - 0s 6ms/step - loss: 1863.1541plt.plot(hist.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()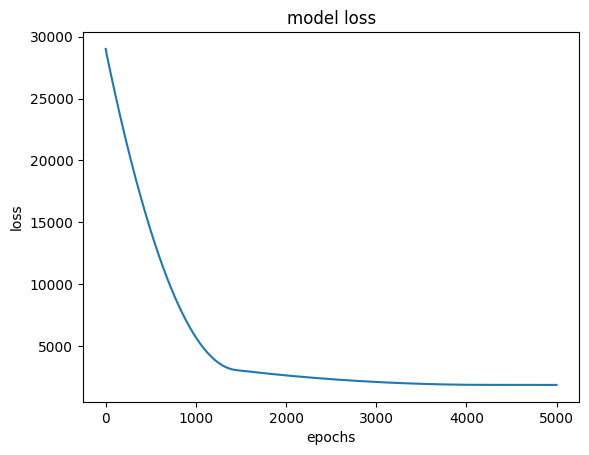
# predict 단계
model.predict(np.array([100,44]).reshape(1,2)) #100kg 44살인 사람은 bloot fat얼마인가 ? array([[375.0153]], dtype=float32)model.predict(np.array([60,25]).reshape(1,2)) #60kg 25살인 사람은 bloot fat얼마인가 ? array([[219.20099]], dtype=float32)# 가중치와 bias를 알고싶은 경우
w_,b_ = model.get_weights()
w_,b_ #weight 값 2개와 bias 값(array([[1.2490604],
[5.5711527]], dtype=float32),
array([4.978542], dtype=float32))# 몸무게 20kg부터 100kg 까지 50개 데이터
x = np.linspace(20,100,50).reshape(50,1)
y = np.linspace(10,70,50).reshape(50,1) # 나이 10살~70살 50개 데이터
X = np.concatenate((x,y),axis=1)
Z = np.matmul(X,w_) + b_fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111,projection='3d')
ax.scatter(xs,ys,zs)
ax.scatter(x,y,Z)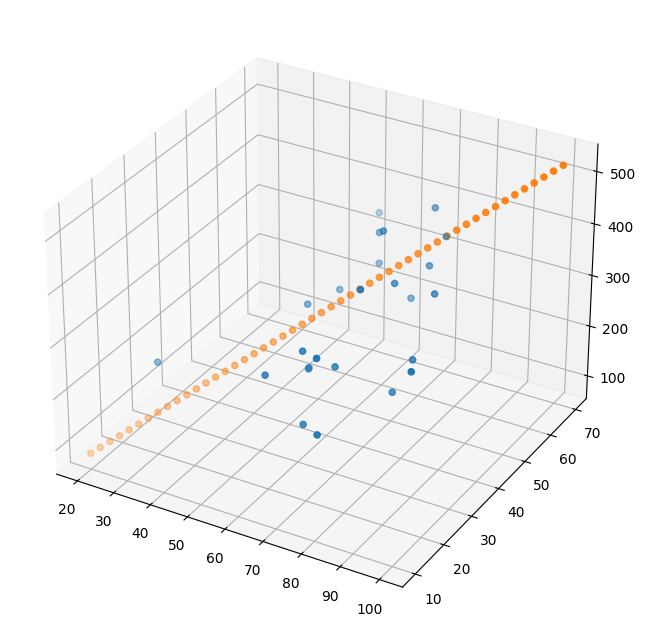
📙XOR 문제
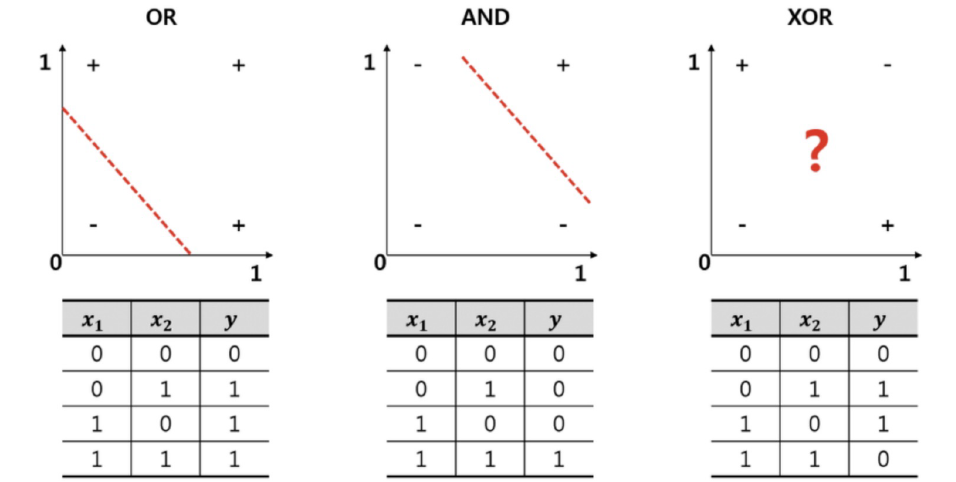
XOR 연산자는 두 입력 신호 x 또는 y의 논리 신호값의 1의 개수가 홀수일 경우 1이 출력되고, 모두 0으로 입력되거나 1로 입력되는 개수가 짝수일 경우 0이 출력된다.
--> XOR은 선형으론 해결할 수 없다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inlineX= np.array([
[0,0],
[1,0],
[0,1],
[1,1]
])
y = np.array([[0],[1],[1],[0]])model = tf.keras.Sequential([
tf.keras.layers.Dense(2,activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(1,activation='sigmoid')
]) #출력2 ->출력1 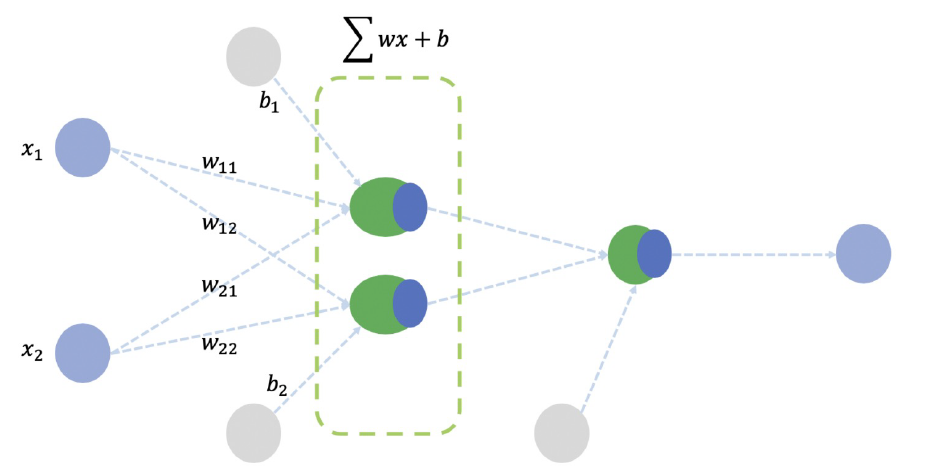
layers를 두번 사용 --> 활성화 함수 시그모이드를 통해 비선형 형태로 만들기
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1), loss='mse') #SGD -> 전체 데이터 쓰지말고 확률적으로 데이터를 샘플링해서 업데이트model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 2) 6
dense_2 (Dense) (None, 1) 3
=================================================================
Total params: 9
Trainable params: 9
Non-trainable params: 0
_________________________________________________________________hist = model.fit(X,y,epochs=5000, batch_size=1)Epoch 1/5000
4/4 [==============================] - 0s 1ms/step - loss: 0.2545
Epoch 4999/5000
4/4 [==============================] - 0s 663us/step - loss: 0.0034
Epoch 5000/5000
4/4 [==============================] - 0s 666us/step - loss: 0.0034epochs는 지정된 횟수 만큼 학습하는 것,batch size는 한번의 학습에 사용될 데이터 수 지정
model.predict(X) #0.5보다 크면 1 / 아니면 0 -->0/1/1/0array([[0.04774854],
[0.944107 ],
[0.9450643 ],
[0.07259166]], dtype=float32)✔ loss 상황
plt.plot(hist.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()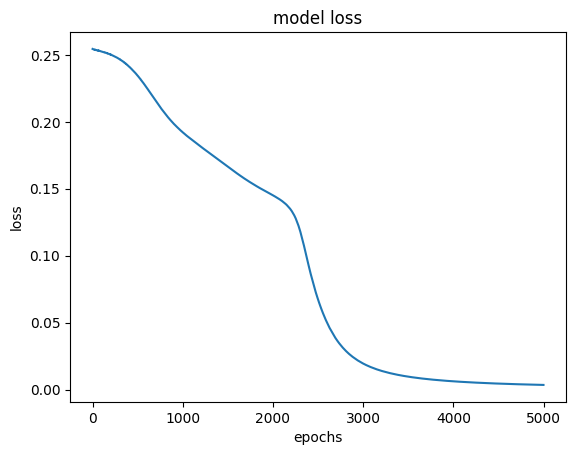
✔ 각 layer별 weight
for w in model.weights:
print('---')
print(w)---
<tf.Variable 'dense_6/kernel:0' shape=(2, 2) dtype=float32, numpy=
array([[-3.7640967, -5.8282585],
[-3.8142653, -6.224226 ]], dtype=float32)>
---
<tf.Variable 'dense_6/bias:0' shape=(2,) dtype=float32, numpy=array([5.5440226, 2.20771 ], dtype=float32)>
---
<tf.Variable 'dense_7/kernel:0' shape=(2, 1) dtype=float32, numpy=
array([[ 7.538599 ],
[-7.8620024]], dtype=float32)>
---
<tf.Variable 'dense_7/bias:0' shape=(1,) dtype=float32, numpy=array([-3.4189231], dtype=float32)>
데이터분석 스터디노트🧐✍️