본 글은 DCGAN논문내 Visualizing에 대한 내용만 담고있습니다.
Paper: https://arxiv.org/abs/1511.06434v1
DCGAN
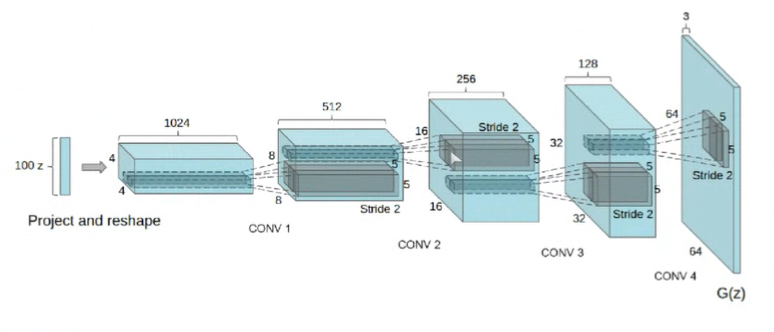
이미지를 활용하는 생성모델일 때에는 Vanilla GAN에서 사용한 FFN보다는 Convolution layer를 사용하는 게 좋겠죠?
Conv layer를 통해서 곡선, 면, 모서리 등의 spatial한 정보를 잘 다룰 뿐더러 넓게 receptive field를 형성할 수 있으며, 이런 층별 역할을 통해 좋은 샘플을 또한 생성할 수 있습니다.
6. INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
DCGAN의 저자들은 생성자와 판별자를 여러 가지 방법으로 분석했습니다.
당시에는 학습 데이터를 기반으로 nearest neighbor 방식으로 분석을 진행하는 것이 주된 방법이었던 것 같은데, 저자들은 이런 방식을 사용하지 않았다고 합니다(pool).
또한, 모델 성능 평가를위해 log-likelihood를 측정해 정량화하는 것 또한 좋지 못한 방법이라고 합니다(pool, too).
6.1. Walking In The Latent Space
Interpolation in vector space
저자들은 우선 모델의 latent space 관점에서의 분석을 행합니다.
즉, 이미지의 저차원 manifold를 분석하는 것입니다.
(매니폴드가 잘 학습 됐다면 이미지 차원에서도 유의미한 변화를 야기하게 됩니다).

(두 개의 latent vector 사이를 보간한 를 이용해 생성한 이미지)
- 창문이 없는 방이 창문이 생기거나, TV가 창문으로 변해가는 과정들을 볼 수 있습니다.
6.2. Visualizing The Discriminator Features
- 본 단락에서는 GradCAM(Guided backpropagation) 기법을 활용해 CNN 내 Filter를 시각화한 모습을 보여줍니다.

(feature map in last layer)
Randomfilter와는 별개로 LSUN bedrooms dataset의 중요한 특징인 침대에 많이 집중하는 것을 볼 수 있습니다.
6.3. Manipulating The Generator Representation
위에서 잠재벡터 의 보간을 통해 유의미한 생성 이미지를 도출할 수 있으며, Discriminator에서 filter의 역할을 볼 수 있었습니다.
이에 따라 Generator의 역할 또한 살펴볼 만 하며, 이 역시 CNN을 사용하는 만큼 우리는 Filter를 활용할 수 있게 됩니다.
6.3.1 Forgetting To Draw Certain Objects
DCGAN 과정에서는 를 실제 데이터 와 유사한 샘플 에 매핑하는 함수 를 학습하게 됩니다.
그렇다는 것은, 생성자 의 Convolutional Layer에 실제 데이터 에 존재하는 특정한 특징들(창문, 침대, 문 등)을 담당하는 filter가 있을 것이라 예측할 수 있습니다.
즉, 창문을 만든다는 필터가 있을 것이고, 그 필터를 제거한다면, 창문을 제거할 수 있는 것입니다.
저자들은 본 논문에서 창문(windows)를 제거하는 실험을 수행했습니다.
이에 대한 예시는 아래 그림과 같습니다.

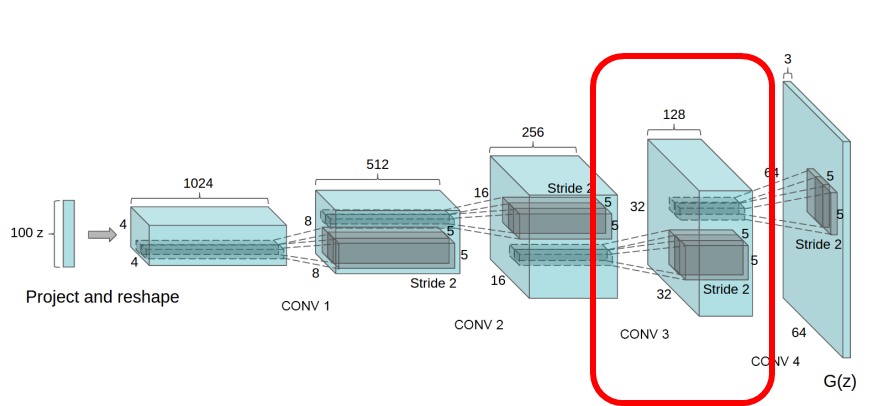
구체적인 방법은, 150개의 샘플에 52개의 창문에 해당하는 바운딩박스를 그립니다.
두번째로 높은 layer의 feature map(activations)를 활용해 창문에 해당하는 features를 찾게 되는데, 방법은 아래와 같습니다.
- bounding boxes안에 있는 activation을 positive로 가정한다.
- 그 밖의 random sample들을 negative로 가정한다.
- 위와 같이 라벨링을 준 다음 로지스틱 회귀를 적용해 특정 activation이 창문에 해당하는지, 창문에 해당하지 않는 지를 fitting합니다.
굉장히 simple한 모델입니다.
이런 간단한 모델을 이용해서 0보다 큰 가중치를 갖는 모든 feature map(총 200개)을 all spatial locations에서 drop합니다(0으로 만든다는 뜻).
all feature maps with weights greater than zero (200 in total) were dropped from all spatial locations.
(여기서 weights가 어떤 weight인 지 정확히는..
(50개의 sample에 해당하는 feature map이 왜 200개 밖에 안 되는지도..)
(logistic regression을 진행한 것은 test data에 적용하기 위함인 것 같습니다만..)
이에 대한 결과는 아래와 같습니다
.

6.3.2 Vector Arithmetic
또한, latent space에서의 연산 또한 가능합니다.
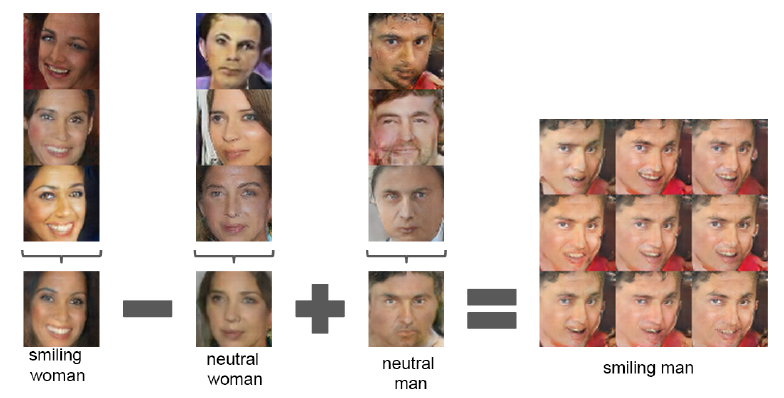
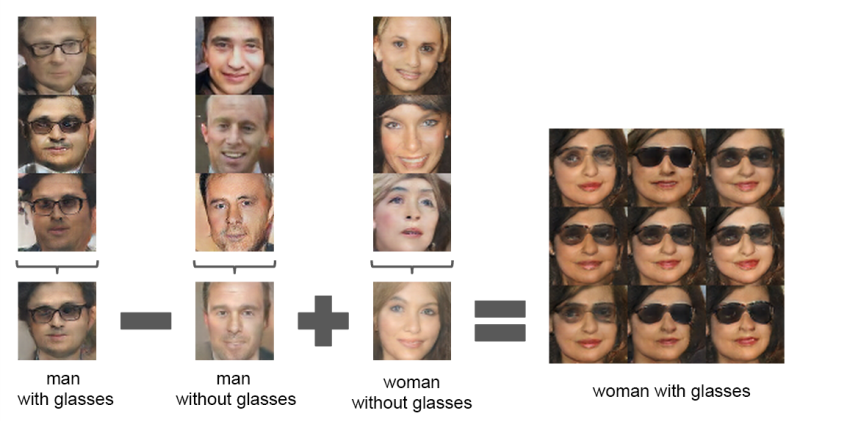
여기서 z vector를 조정함으로써 '웃음, 남성, 여성'이라는 특징을 조절할 수 있게 됩니다.
