[논문리뷰] GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
Generative Model

Paper : GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
Code : https://github.com/CSAILVision/gandissect
Project : https://gandissect.csail.mit.edu/

0. ABSTRACT
GANs(과 그 변형들)은 생성 퀄리티나 학습 안정성 면에서 꽤나 많은 진전을 보여왔습니다만, 모델의 이해(혹은 시각화) 측면에서는 지지부진했습니다.
- GAN은 내부적으로 우리의 시각 세계를 어떻게 표현할까?
- GAN의 결과에 나타나있는 artifact들은 무엇이 야기할까?
- GAN 구조를 선택하는 것이 학습에 어떻게 영향을 끼칠까?
위와 같은 의문들에 답하는 것은 우리에게 새로운 통찰과 더 좋은 모델을 가져다줄 수 있습니다.
본 연구에서는, GANs을 unit 수준에서, object 수준에서, 그리고 scene 수준에서 시각화하고 이해하는 분석 프레임워크를 제안합니다.
우선, 저자들은 segmentation-based network dissection method를 사용해 object concepts와 밀접하게 관련된 일련의 해석가능한 units(filters)을 식별합니다.
그리고, 이 units의 output의 objects를 제어하는 개입 능력을 측정함으로써 해석가능한 units의 인과 관계를 정량화합니다.
저자들은 발견된 object concepts를 새로운 이미지에 삽입함으로써 해당 units과 그 주변 환경 사이에 있는 contextual relationship을 파악할 수 있었습니다.
저자들의 방법을 토대로 다양한 datasets, models, layers들 간에 내재된 representations을 비교하는 것부터, artifact(현실적이지 못한 생성물)를 유발하는 unit을 지우거나 이동시킴으로써 GANs을 개선할 수 있었습니다(즉, 풍경 내의 object를 인터랙티브하게 조작할 수 있었습니다).
1. Introduction
2014년 Goodfellow에 의해 제안된 GANs은 획기적인 아키텍처로 하여금 수 많은 변형 모델들의 개발을 불러일으켰습니다. 특히, visual recognition부터 image manipulation*, video prediction 등과 같은 응용 모델들도 생겼습니다.
- image manipulation
여기서 말하는 이미지 조작은 Image-to-image translation with conditional adversarial networks(2017) 같은 모델들입니다.
수많은 GAN 기반 모델들의 성공에도 불구하고, 여전히 의문은 남아 있습니다.
교회 이미지를 생성하기 위해 GAN은 어떤 지식을 배워야 하는걸까요?

반대로, GAN이 현실적이지 못한 끔찍한 이미지를 생성할 때, 무엇이 이를 야기하는 걸까요?

그리고, 왜 GAN의 변형 모델들이 다른 모델들보다 성능이 좋은걸까요? 근본적으로 어떤 차이가 weight 내에 인코딩 되는 걸까요.
본 연구에서 저자들은 GANs의 **internal representations(내부 표현)**을 연구합니다. 일반적으로, 우리같은 인간이 보기에 잘 학습된 GAN은 이미지 내 object에 대한 팩트만을 배우는 것처럼 보입니다.
예를 들어, "문은 건물에 위치한다", 혹은 "문은 나무에 위치하지 않는다"와 같은 사실들.
우리는 GAN이 그런 구조를 어떻게 표현하는 지 알고싶어 합니다.
- GAN은 문이나 나무같은 물체의 명시적인(explicit) representation 없이 단순히 순수한 pixel patterns으로서 물체가 발생하는 걸까요?
- 아니면, GAN은 인간이 인지하는 물체에 해당하는 내재 변수(internel variables)를 포함하고 있는걸까요?
- 내재 변수를 포함하고 있다면 이게 바로 물체의 생성을 야기하는 걸까요?
- 아니면 단지 상관관계만 있는걸까요?
- 그 물체들 간의 관계는 어떻게 표현될까요?
이러한 의문들을 해결하기 위해 저자들은 각 neuron, object, contextual relationship(between different object) 레벨에서 GANs을 이해하고 시각화하기 위한 general method를 제안합니다. 해당 방법들은 크게 아래와 같이 나뉩니다.
-
object concepts와 관련된 일련의 해석가능한 units들을 식별(dissect)합니다.

이 unit들의 feature maps은 특정 class(예를 들어, 나무)의 semantic segmentation과 밀접한 관련이 있습니다. -
object가 사라지고 나타나게끔 야기하는 일련의 units을 식별하기 위해 네트워크에 직접 간섭(intervene) 합니다.

이를 위해 standard causality metric를 사용해 유닛들의 causal(인과적) effect를 정량화합니다. -
이 causal object units과 bakground 사이의 contextual relationship을 실험합니다(위의 1d).
이외에도 저자들은 GAN 내부 layers에 따라서, GANs 모델에 따라서, Datasets에 따라서 네트워크 내부의 representations을 비교합니다.
그로 인해 "비현실적인 물체(artifact)"를 제거하거나 이동시킴으로써 GANs의 버그를 수정하거나 개선할 수 있으며, objects의 맥락 관계를 이해할 수 있고, interactive하게 object-level control을 통한 이미지 조작이 가능해집니다.
2. Related work
해당 단락에서 다루는 내용은 아래와 같습니다.
Generative Adversarial Networks
Visualizing deep neural networks
Explaining the decisions of deep neural networks
여기서는 Visualization과 Explanation에 대해서만 다루도록 하겠습니다.
2.1. Visualizing deep neural networks
Deep Neural Network의 내부 표현을 이해하기 위한 다양한 방법이 많이 개발되어 왔습니다.
-
Visualizations for RNNs
- Andrej Karpathy, Justin Johnson, and Li Fei-Fei. Visualizing and understanding recurrent networks.
In ICLR, 2016.
- Andrej Karpathy, Justin Johnson, and Li Fei-Fei. Visualizing and understanding recurrent networks.
-
Visualization for CNNs
-
by using salient image features
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. In ICLR Workshop, 2014
- Aravindh Mahendran and Andrea Vedaldi. Understanding deep image representations by inverting them. In CVPR, 2015.
-
by mining patches that maximize hidden layers's activaitons
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In ECCV,2014
-
by synthesizing input images to invert a feature layer
Alexey Dosovitskiy and Thomas Brox. Generating images with perceptual similarity metrics based on deep networks. In NIPS, 2016
-
object segmentations masks와 unit activations 사이의 일치성을 측정함으로써 각 unit의 semantics(의미)를 식별
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Object detectors emerge in deep scene cnns. In ICLR, 2015. 3
-
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In CVPR, 2017
-
Bolei Zhou, David Bau, Aude Oliva, and Antonio Torralba.
Interpreting deep visual representations via network dissection. PAMI, 2018a
GAN-Dissection 저자들의 이전 연구입니다.
-
이러나 저러나 상당 수의 Visualization 연구들은 CNN 기반 모델 중 Image-Classification에 집중되어 왔습니다.
저자들은 Image-Generation을 학습한 GAN 모델에 대한 설명을 제공하는 것을 목표로 합니다.
2.2. Explaning the decisions of deep Neural networks.
Deep Neural Networks에 적용되는 XAI 기법들은 주로 네트워크의 결정(output)에 대한 결정 근거를 제공하는 것을 목표로 합니다.
-
Explanations Using informative heatmaps
- Bolei Zhou, Yiyou Sun, David Bau, and Antonio Torralba. Interpretable basis decomposition for visual explanation. In ECCV, pp. 119–134, 2018b. 3
-
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In ICCV, 2017
-
Explanations Using modified back-propagation
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks:
Visualising image classification models and saliency maps. In ICLR Workshop, 2014.
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks:
-
Sebastian Bach, Alexander Binder, Gregoire Montavon, Frederick Klauschen, Klaus-Robert M ´ uller, ¨ and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise
relevance propagation. PloS one, 10(7), 2015 -
Explanations through Contribution of feature vectors
- Been Kim, Justin Gilmer, Fernanda Viegas, Ulfar Erlingsson, and Martin Wattenberg. Tcav: Relative concept importance testing with linear concept activation vectors. arXiv preprint arXiv:1711.11279,
2017
- Been Kim, Justin Gilmer, Fernanda Viegas, Ulfar Erlingsson, and Martin Wattenberg. Tcav: Relative concept importance testing with linear concept activation vectors. arXiv preprint arXiv:1711.11279,
-
위의 heatmap 기반 연구인 Interpretable basis decomposition for visual explanation 또한 해당 범주에 속합니다.
-
Explanations thorugh individual channels
- Chris Olah, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, and Alexander Mordvintsev. The building blocks of interpretability. Distill, 3(3):e10, 2018.
-
Examining effect of individual units by Abalating units
Ari S Morcos, David GT Barrett, Neil C Rabinowitz, and Matthew Botvinick. On the importance of single directions for generalization. arXiv preprint arXiv:1803.06959, 2018
해당 기법들은 웬만하면 CNN기반 Discriminator에 적용되는 반면(연구 많음), 저자들은 GAN의 generator가 어떤 방식으로 이미지를 생성하는 지에 더욱 집중합니다(연구 적음).
3. Method
해당 방법의 최종적인 목적은 GAN Generator 의 내부 표현에 의해 나무라는 오브젝트가 어떻게 인코딩 되는지를 분석하는 것입니다.
우선, 아래와 같이 notation을 정의합시다.
. GAN이 generator.
: latent vector. 상대적으로 저차원 공간에서 샘플링된다.
: generated image.
: intermidiate output of . (여러 Convolution-layer로 이루어진) generator 내 특정 layer의 output tensors를 이라 가정.
- 즉, =라 할 때, , 라 할 수 있음.
- 여기서 representation feature maps activations 으로 봐도 (일단) 무방할 듯 함.
위의 상황을 그림으로 요약하면 아래와 같이 요약할 수 있습니다.
(의 차원, convolution layer의 channel, stride 등은 임의로 가정)
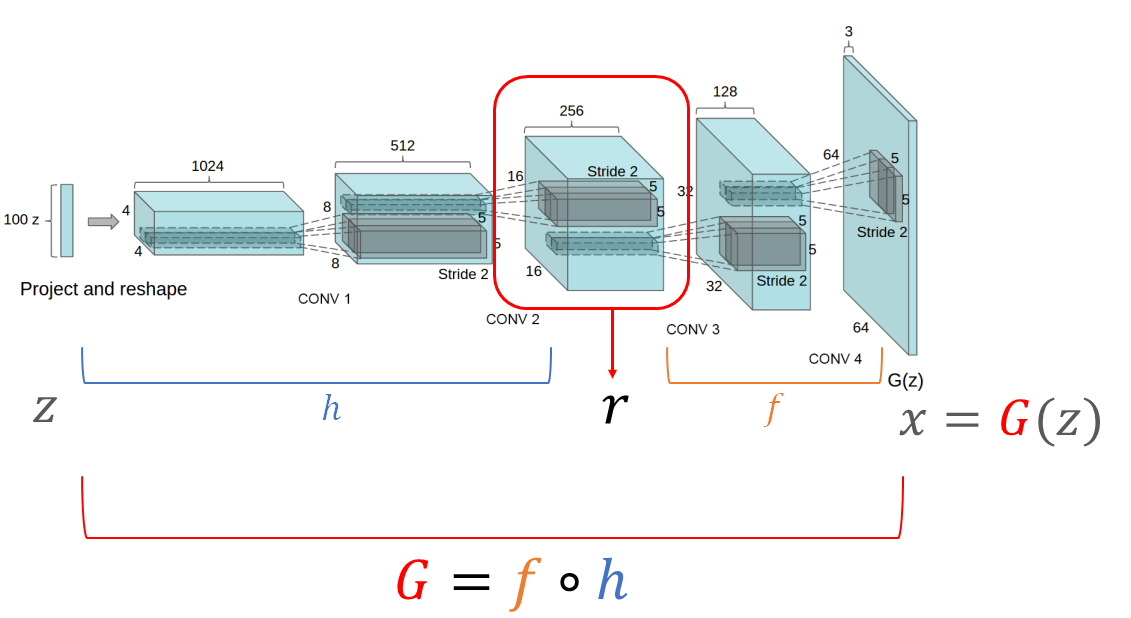
즉, 는 일련의 layer들이고, 은 그 layer의 output(activations), 즉 전체 channel의 feature map입니다.
은 이미지 을 생성하기 위한 모든 정보를 가지고 있어야 하기 때문에, 은 분명히 이미지 내 특정한 클래스 의 존재를 도출해내는 정보를 가지고 있다고 봐도 무방합니다.
따라서, 특정 클래스 의 정보가 에 '있느냐'가 궁금한 게 아니라, '어떻게 인코딩 되어있는가'가 궁금한 것입니다.
특히, 저자들은 이 명시적으로 를 나타내는 지 이해하기 위해 특정 위치 (pixel)에서 feature map의 특정 채널 조합인 를 이용해 을 2개의 요소로 분해하는 방법을 사용합니다.
이 때, 위치 에서 특정 class(object) 의 생성을 주로 유도하는 units이 이며,
큰 영향을 못 끼치는 다른 units이 이라 가정합니다.
- 본 논문에서 쓰이는 unit()이란 feature map의 각 channel을 뜻합니다.
- 즉, units()는 feature map의 channel 집합입니다.
- 와 는 상보적 관계입니다. 즉, =(가능한 모든 units의 집합전체 channel).
- 그러니, 분해 이전의 은 특정 layer의 output(feature maps)이므로 전체 channel인 를 unit으로 갖습니다.
- 는 위치로서, 특정 pixels 를 뜻합니다.
- 가능한 모든 pixel을 라고 합니다.
저자들은 Generator의 hidden output인 의 구조를 두 단계를 거쳐 분석합니다.
- Dissection : object classes의 large dictionary에서 시작해, 에 representation을 가지고 있는 classes를 식별합니다. 이는 모든 class 와 개별 units 사이의 일치성(agreements)를 측정함으로써 수행합니다(아래 그림 (b)).
- Intervention : dissection을 통해 얻은 represented classes의 관점에서, 일련의 causal units들을 식별하고, units과 object classes 사이의 causal effect를 정량화합니다. 이는 일련의 units들을 껐다 킴으로써 수행합니다(아래 그림 (c), (d)).


즉, Generaotr 내에 정보가 있는 classes를 찾아내고, 그 classes를 야기하는 units, 즉 feature maps의 channel들을 찾아냅니다.
3.1. Characterizing units by Dissection
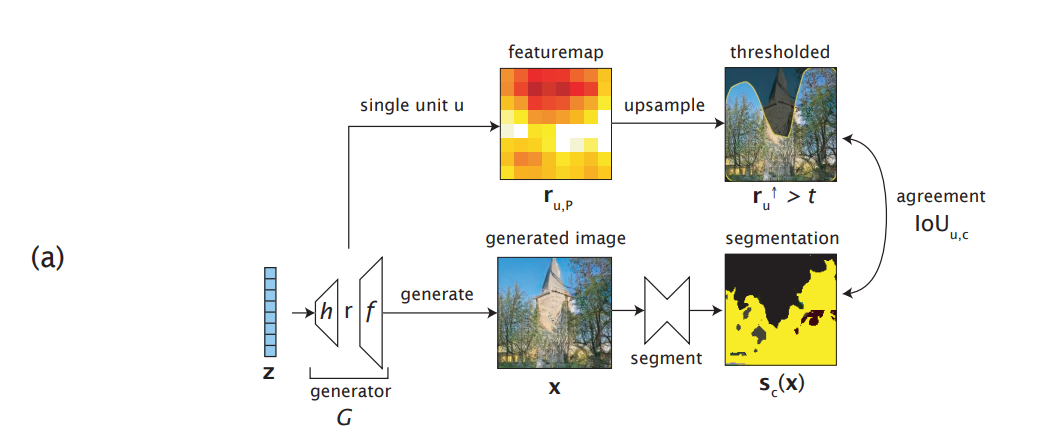
(Dissection)
우선, 이라는 notation을 봅시다.
는 개별 unit(channel)을 뜻하며, 는 가능한 모든 pixel을 뜻합니다.
즉, 는 GAN의 generator 중간에서 뽑아낸 하나의 채널을 갖는 feature map입니다.
또한, 일반적으로 Generator에서 피쳐맵의 크기는 output에 가까워질수록 커지기 때문에 중간 layer에서 뽑아낸 피쳐맵의 크기인 는 최종적인 생성 이미지 의 크기인 보다는 작을 것입니다().
여기서, 우리는 이 특정 unit 가 나무라는 의미 있는 class에 대한 정보를 담고(encode)있을 지 알고 싶습니다.
이를 위해, 저자들은 각 class 에 대한 semantic segmentations 를 사용합니다.
구체적으로는, unit representation 에[upsamplingthreholding*]을 과정을 적용해 크기를 키운 다음 이를 특정 class에 대한 segmentations map인 와 비교해 spatial agreements를 정량화합니다.
여기서는 가장 대표적인 방법인 intersection-over-union(IoU)를 이용해서 진행합니다.
- 이미지 분류 네트워크에서는 units들을 upsample한 다음 thresholding을 먹인다면 units들을 발생한 object classess에 근사하게 위치시킬 수 있다는 사실을 파악했습니다.
최종적인 image와 중간의 feature map들은 어느 정도 localization을 공유한다는 사실이 널리 알려져 있는 것과 유사하게요.
- David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In CVPR, 2017.
위에서 는 당연히 semantic segmentation을 뽑아낼 수 있는 클래스 집합을 말합니다. "벌꿀 오소리"같은 class는 들어있지 않습니다.
위에서 말한 와 upsampled-thresholded 를 비교하는 식은 아래와 같이 표현됩니다.
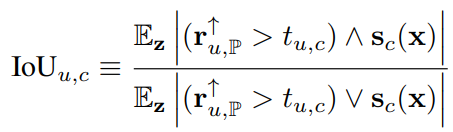
는 specific unit 를 upsampling한 것이고, 는 해당 채널에 대한 threshold입니다.
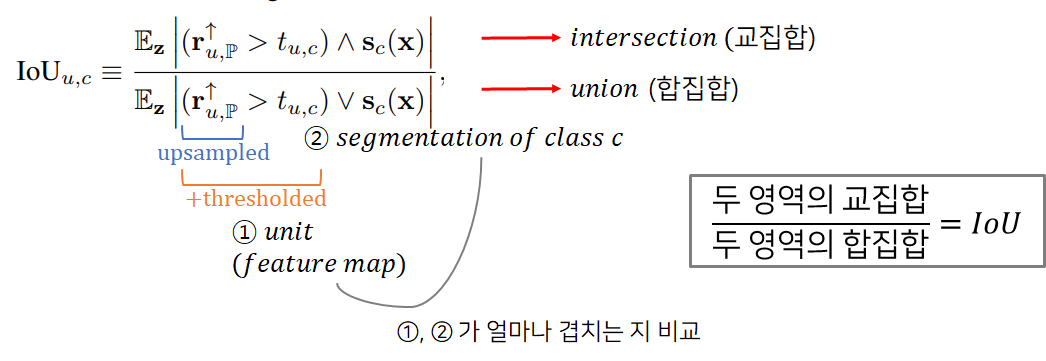
위에서 segmentation map 는 생성 이미지 에서의 클래스 에 대한 segmentation map이고, 두 영역을 비교해야 하므로 one-channel feature map 는 당연히 생성 이미지 의 size만큼 upsample해야 합니다.
thresholding**을 적용하게 되면 역치 upsampled-unit 은 보다 큰 값은 1로, 보다 작은 값이 0인 binary mask가 됩니다.
이 때, 채널 , class 에 대한 역치인 는 아래와 같이 정해집니다.
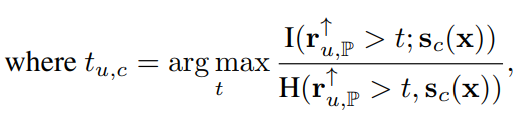
위의 식에서
: mutual information. 값이 커질수록 두 signal 간 정보 손실이 작아짐.
: joint entropy. 두 signal의 불확실성의 총합이 작아짐.
입니다.
즉, 이를 이용해 information quality ratio 를 최대화 하는 역치 값을 찾습니다(validation set 이용).
우리는 upsampled-unit 에 역치를 취할 때, segmentation map 와 정보 손실이 최대한 적어지도록 역치 값을 정해야 합니다.
이를 위해 mutual information 를 최대화해야 하는 것이고, 두 분포 간 정보 손실을 다루기 위해서는 다른 상황과 동등한 비교를 위해 정규화를 수행해주어야 하므로 두 분포의 불확실성의 합인 joint entropy 로 나누어 주는 것입니다.
이에 대한 자세한 이론은 Wijaya et al, "Information Quality Ratio as a novel metric for mother wavelet selection"
결론적으로, 위의 값을 이용해서 특정 unit 에 대해 concepts(class) 들에 대한 순위를 매길 수 있으며, unit 와 *가장 일치하는 class $c^{}$를 정할 수 있게 됩니디.
unit1(channel 1) : tree() > car > dog > ....
unit2(channel 2) : car > sky > human > ....
...
unit 512(channel 512) : tree() > human > dog > ...

(두 개의 GAN 모델에 대해 각각 테이블과 소파를 가장 활성화 하는 unit을 나타내는 그림)
아무튼, 이 과정(Dissection)을 통해서 모든 units(예를 들어 512channel)에 대해 각각 가장 매칭되는 object class들을 찾을 수 있습니다.
위 그림의 예시는 Top-unit만을 가져온 것이지만 table과 sofa에 해당하는 unit은 수십 개씩 있을 수 있습니다.
다만, 우리는 이것 뿐만 아니라 그 모든 unit들 중에 어떤 unit 집합이 object의 발생(렌더링)을 유발하는 지 찾을 필요가 있습니다.
Dissection은 그저 feature map의 activaitons과 class의 segmentations의 상관관계(혹은 유사도)만 파악할 뿐, 인과 관계를 파악하는 것은 아닙니다.
또한 object는 여러 개의 representations(unit, activation)에 공통으로 의존할 수도 있구요.
즉, 어떤 unit 집합들이 object를 야기하는 지 해당 집합을 찾을 필요가 있고, 저자들은 이를 Intervention이라 부릅니다.
3.2. Measuring Causal Relationships Using Intervention
Unit과 Object 간의 인과관계를 파악하기 위해 저자들은 intervention을 이용합니다.
즉, feature maps 내의 units 를 끄거나, 키는 등의 조작을 가하고, 그에 따라 class 의 생성을 야기하는 지를 살펴봅니다.
1,13,35,300,550 번째 unit(feature map)을 껐더니 최종적이 생성 이미지 에 나무가 사라졌다면 이 units이 나무를 유발하는 units이겠죠.
다만, 이 중에 1,13번 unit 만으로도 나무를 온전히 control할 수 있는 것인지, 아니면 200,211, 233번 등의 추가적인 unit이 있어야 나무를 완전히 control할 수 있는 지는 판단하기 쉽지 않습니다.
경우의 수도 너무 많구요(full : ).
구체적으로는,
를 units(channels) , 위치 에서의 feature map 이라 할 때,
의 값을 으로 할당함으로써 유닛을 약화(ablate) 시키고,
의 값을 (사실 로 보는 게 더 맞을 듯)로 할당함으로써 유닛을 개입(insert)시킵니다.
이 때 는 per-class constant입니다. 즉, 클래스 가 fix됐을 때, featuremap의 특정 위치 에서 (output image 기준으로) class 가 존재한다면, 그 위치 에 해당하는 feature map activations들을 모두 평균낸 값입니다(activations mean conditioned presence of ).
아무튼, 그냥 class 가 진짜로 존재하는 activations들만 평균내서, 가 존재하진 않지만 에는 포함된 pixel에도 그 값을 부여한다고 보면 될 것 같습니다.
- 논문 내 참고.
이런 요소들을 적용하기 위해 units 가 아닌 units을 , pixels 가 아닌 pixels을 라 가정하고, 중간 feature maps인 을 로 분해함으로써 전반적인 Generation 과정을 기호화 해봅시다.
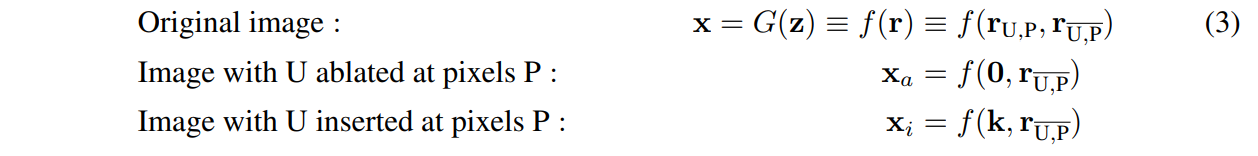
위처럼 와 에 생성 이미지가 의존하게끔 정의했을 때 만약 생성 이미지 에 object 가 나타나고, 또 다른 생성 이미지 에서 object가 사라진다면, 가 object 의 원인(cause)이라고 봐도 무방합니다.
이 인과성(causality)는 와 간 나무의 존재 차이를 비교해, 모든 이미지와 모든 위치에 대해 평균을 냄으로써 정량화할 수 있습니다.
저자들은 이전의 연구를 이용해 class 에 대한 average causal effect (ACE) of units 를 아래와 같이 정의합니다.
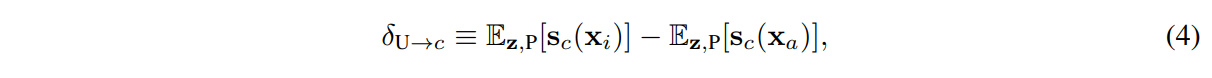
: class 의 존재를 나타내는 segmentation. 단, 위치는
저자들은 흔하지 않은 class 를 다루기 위해 평균을 낸 값을 사용한다고 합니다.
위의 값 자체는 엄밀히 따지면 single unit에 대해서만 계산할 수 있지만, object는 보통 여러 개의 units에 의존하는 경향이 있습니다.
그래서, 위의 식 (4) **평균 causal effect 를 최대화하는 를 찾아야 합니다.
3.2.1. Finding sets of units with high ACE
representation 이 unit(channel)을 개만큼 가지고 있다 가정합시다. 즉, feature maps 은 -channel의 feature maps입니다.
이 때, 를 특정 size로 fix시킨 다음 가능한 의 조합들을 모두 살펴보려면 경우의 수로 를 가집니다.
는 보통 512쯤 되니, 을 10으로 가정했을 때가지의 경우의 수가 나옵니다.
실제로는 또한 10개가 넘을텐데요..
이렇게 exhuastively하게 discrete한 집합을 구하는 것 대신에, 저자들은 continuous한 차원 vector 를 이용해 최적화를 수행합니다.
: 각 dimension 에서 는 unit 의 intervention 정도를 나타냅니다.
즉,

이렇게 정의한 후, 저자들은 average causal effect formulation 를 최대화하게끔 최적화를 진행합니다. 즉, 우선 아래와 같이 정의한 뒤
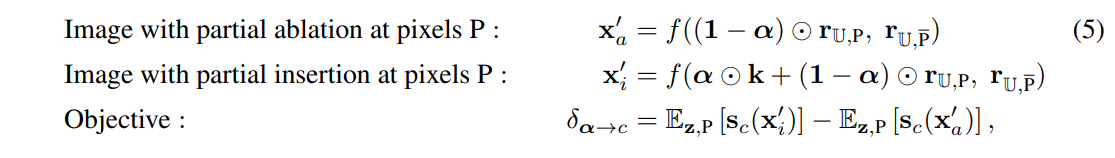
아래와 같이 를 최소화하는 손실 함수를 이용해 학습을 진행합니다( Regularization 적용)
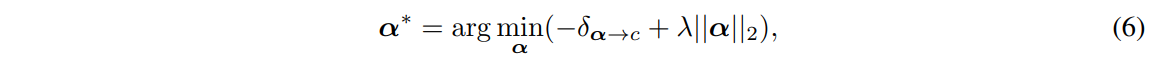
즉, 원래 유닛 조합인 에 대해서 최적화를 수행하는 것 대신, 이제는 전체 유닛 를 이용한, 위치 에서의 전체 채널의 feature map 를 이용해 최적화를 수행합니다.
위의 식 (5)에 나타난 ⊙는 channel별 연산이겠죠.
L2 loss는 Casual units의 minimal set을 찾기 위해 적용했습니다.
(사실, L2 loss를 쓴다는 것은 특정 unit이 object에 과도하게 영향을 끼치는 것을 방지하고, 여러 unit이 골고루 object에 영향끼치게끔 한다는 것인데, 이게 어떻게 minimal set으로 연결되는 지는 잘 모르겠습니다. 해석의 문제인지..)
위의 식 (6)은 하나의 클래스 에 대한 intervention coefficient 를 구하는 것이기 때문에, 이후 원하는 것에 따라 또 다른 클래스 에 대한 **intervention coefficient 를 구할 수 있겠죠.
더욱 구체적으로는 SGD Algorithm을 사용해 위의 를 최적화했고, 는 단순히 0과 1의 값을 가질 수 있도록 clamp해줍니다.
최적화가 완료되면 위에서 구한 를 토대로 units의 클래스 에 대한 casual rank를 구할 수 있고, 이 rank를 적절히 참고해 class 를 조작하는 units를 결정할 수 있게 됩니다.
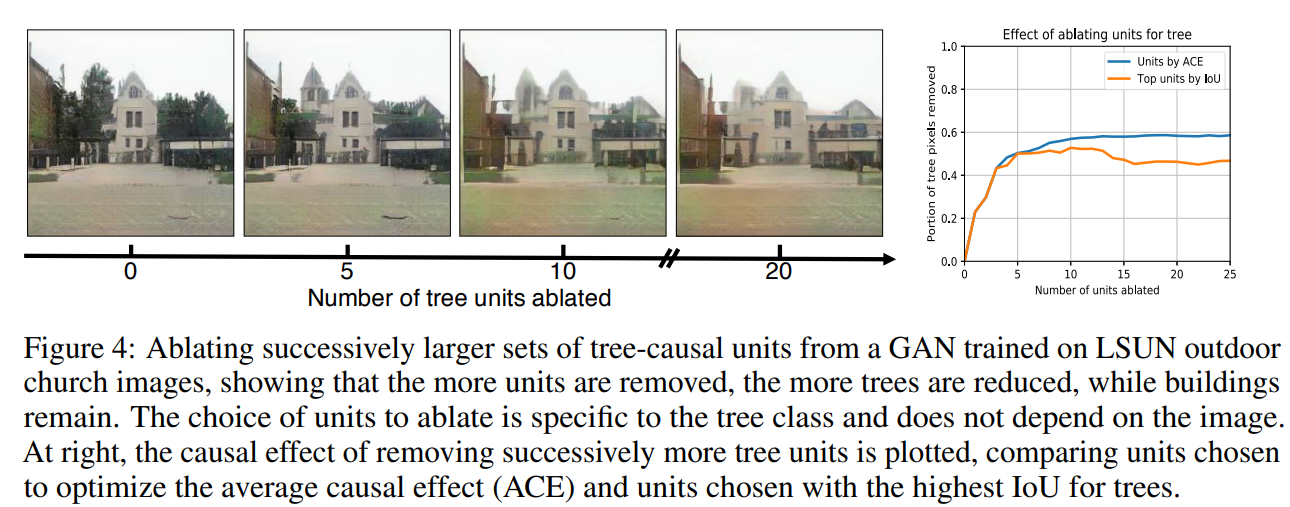
학습이 잘 완료 되면 위 그림처럼 나무 class에 해당하는 를 토대로 가장 높은 값을 갖는 unit들을 제거(abalation)할 수 있습니다.
제거하는 unit의 개수에 따라서 나무들은 더욱 많이 사라지며(좌측), 단순히 unit(feature map)을 Tree segmentation과 IoU를 비교해 유사도를 파악해 unit을 지우는 것보다 ACE를 통해 unit을 지우는 것이 훨씬 안정적인 성능을 보이는 것을 확인할 수 있습니다.
상식적으로 생각했을 때, ACE 값을 높게 기록한 unit일 경우 나무에 대한 casuality가 강한 unit이기 때문에 top 5 unit 정도만 지워도 큼지막한 나무들은 얼추 지울 수 있을 것으로 예상 됩니다(global하게). 그 이후에 지워지는 unit들은 보다 작은 나무 디테일들을 지우게 될 것입니다(local하게).
이쯤까지 읽어보니 언젠가 비슷한 모델을 다룬 기사를 본 것 같아서 가져왔습니다만,
[AI 리뷰] 설명가능한 AI로 딥러닝 생성모델 오류 수정한다!... KAIST 인공지능대학원 최재식 교수팀 개발


해당 논문은 읽어보지 않았지만, 계층적이라는 이름으로 미루어봤을 때 GAN-Dissection처럼 특정 layer의 representation 을 이용하는 것보다 여러 layer의 representation 을 이용하는 것이 더욱 효과적일 수 있다는 insight를 얻을 수 있습니다.
비교대상이 된 이분들 혹시..?

논문 : Automatic_Correction_of_Internal_Units_in_Generative_Neural_Networks_CVPR_2021
4. Result
Interactive하게 결과를 살펴볼 수 있는 웹 데모는 아래 사이트에서 실행 가능합니다.
https://gandissect.csail.mit.edu/

그 외의 예시들을 한번 살펴봅시다.
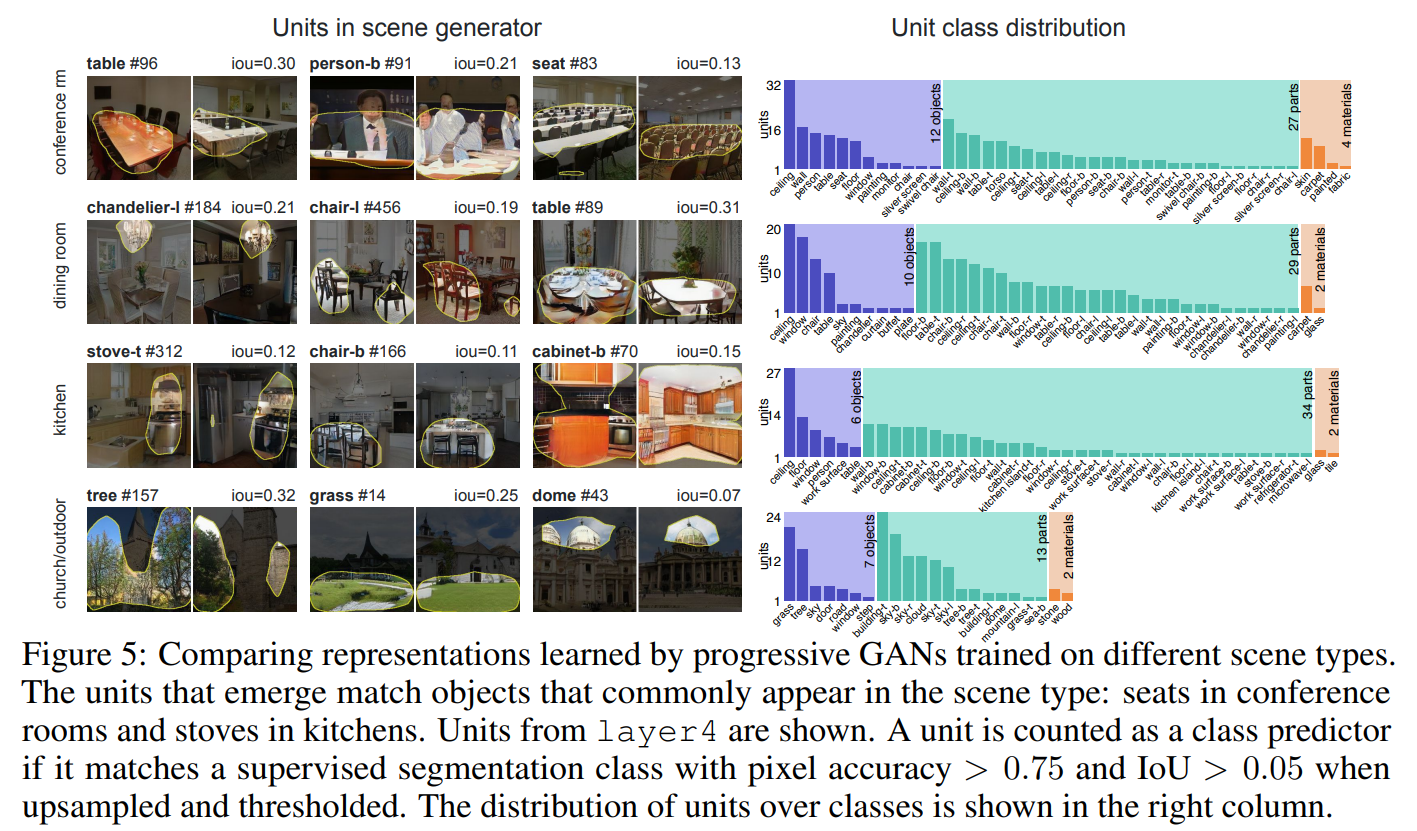
- 잘 학습된 GAN을 다양한 상황에 학습시킨 예시입니다.
- 각각 하나의 상황이기 때문에 테이블, 의자, 나무 등이 주로 나타날 것이고, 이 object들은 상당수의 이미지에 존재할 것이기 때문에 그에 상응하는 unit또한 많을 것으로 예상됩니다.
- 우측에는 특정한 조건(accuracy, IoU 등)을 만족시킨 unit만을 카운트합니다.
그러니 우측에 나와있는 unit들을 다 합치더라도 layer 4의 채널 개수인 512에는 모자라겠죠.
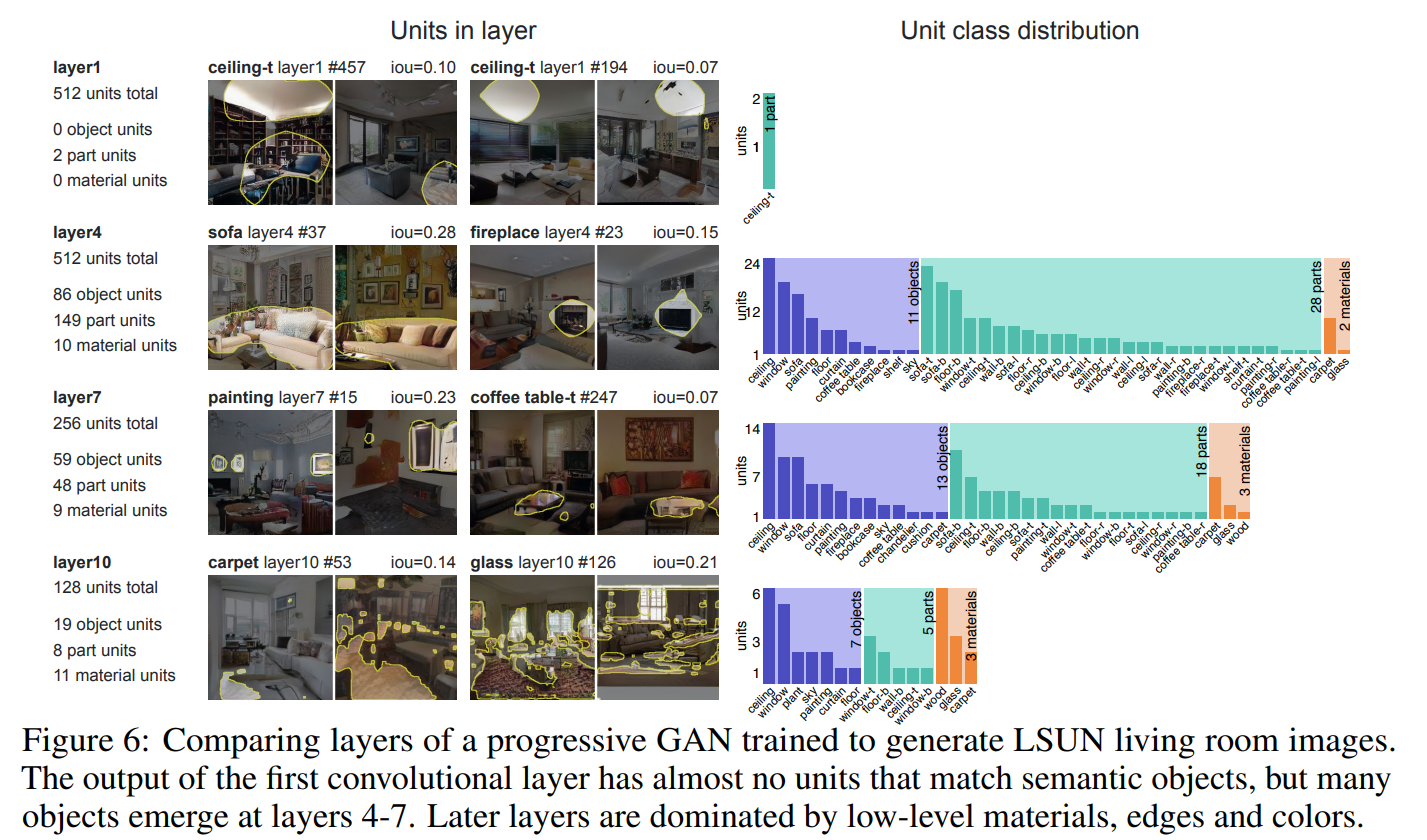
위의 Figure 5. 에선 다양한 상황에 대한 units들을 살펴봤다면, Figure 6.은 한 상황에 대한 다양한 layer의 representation을 비교합니다.
layer 4 정도의 feature map이 IoU
CNN모델의 경우 (이미지 분류)에서는 shallower layer의 feature map이 디테일한 부분(edge, color 등), 즉 local한 부분을 주로 파악하고, deeper layer의 feature map이 전반적인 object, background, context, 즉 global한 부분을 주로 파악한다고 알려져 있습니다.
GAN은 위와 같은 사실을 반대로 뒤집어 생각할 수 있으므로, layer 1에 가까울수록 global하게 파악하느라 기껏해야 ceiling같이 큼지막한 part만 IoU 조건을 만족시키는 것을 볼 수 있고, layer 10쯤 가면 object를 파악하는 게 아닌, edge를 주로 파악하고, 그냥 운 좋게 짜잘한 부분들이 모여서 IoU조건을 만족시키는 것을 볼 수 있습니다.
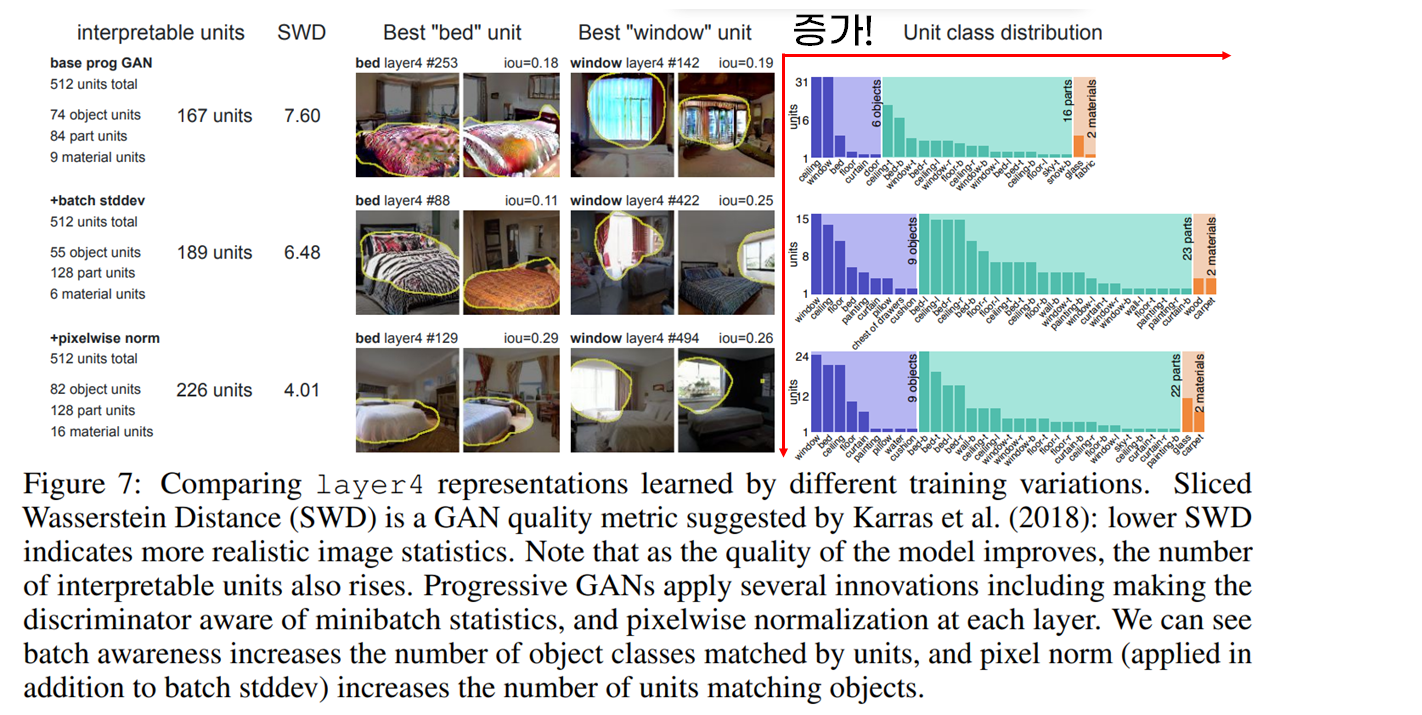
위 그림은 SWD(Sliced Wasserstein Distance)를 GAN의 quality metric으로 적용해 비교한 결과입니다(낮을수록 GAN의 성능이 좋다고 알려져 있음).
위에서 보다시피 성능이 좋아질 수록(SWD가 낮아질 수록) classes 들에 매칭되는 units의 개수가 늘어나는 것을 볼 수 있습니다.
즉, 판별자에게 minibatch의 통계량을 부여하는 batch stddev 방법과 그에 추가로 각 layer에서 pixelwise normalization을 적용했을 경우 SWD성능은 좋아지며, 그에 따라 object와 매칭되는 unit의 개수 또한 늘어났습니다.
즉, (여러 방법들을 사용해서) GAN의 성능이 좋다고 여겨질수록 각 filter가 하나의 class에 집중하고, 특히 인간이 라벨링한 segmentation 마스크와 더더욱 잘 일치한다는 사실을 알 수 있습니다.
(특히 class와 매칭되는 Unit이 많아집니다 !! --> 디테일한 표현 가능)

특히, artifact에 해당하는 units들(여기선 20개)을 약화시켰을 경우 생성 이미지 또한 이미지의 퀄리티가 높아진 것을 알 수 있습니다.
아래는 저자들의 방법으로 artifact units을 제거했을 경우, 원본 이미지와의 거리를 토대로 랜덤하게 artifact를 제거했을 경우보다 확연한 성능 향상을 보이는 사실을 확인할 수 있는 테이블입니다.

artifact에 해당하는 units은 FID을 이용해 자동으로 판별합니다.
(궁금하면 Supplements 확인 !)

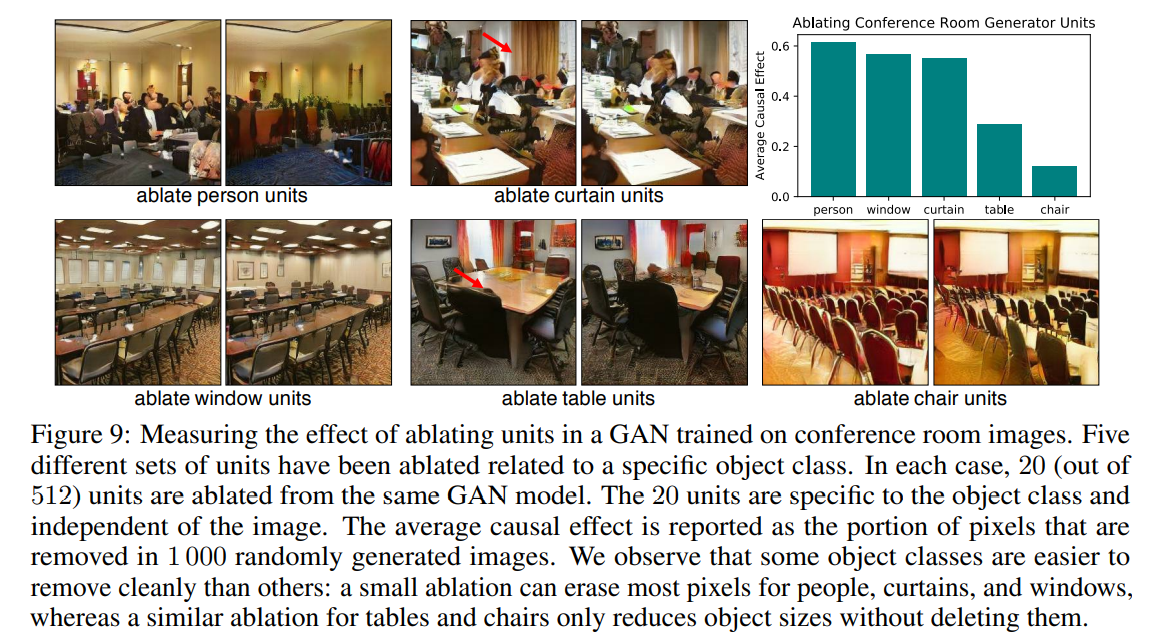
단, 위처럼 회의실 장면에서 사람, 의자, 커튼, 창문, 테이블에 해당하는 unit들을 개만 약화시켰을 경우 웬만하면 pixel이 상당 부분 변화했지만(우측 상단, 1,000개 이미지 기준), 의자 만큼은 pixel이 거의 변화하지 못했다.
즉, 회의실에서의 의자의 존재는 너~무나도 지배적이기 때문에 20개의 unit을 지우는 것 만으로는 충분한 변화가 일어나지 못한 것을 알 수 있다.
(50개 이상을 싹다 지워버리면 어떻게 될까)
침실, 거실에서의 창문 또한 비슷한 문제(abalation level이 너무 높은 문제)가 존재한다.


- 하나의 pixel에 해당하는 위치에 20개의 unit을 강화할 경우 위처럼 그럴싸한 곳에만 문이 생기는 것을 볼 수 있다.
- 또한, 기존에 존재하는 문 위에 강화한다면 문의 크기가 커지는 것을 볼 수도 있다(d).
그 외에도 논문 내에는 Supplements포함해, GAN에 대해 실시한 다양한 분석이 존재합니다.
또한, Optimization 과정에서 를 어떻게 선택하는지에 대한 내용도 Supplements에 존재합니다 !!
5. 결론
저자들은 GAN 기반 모델에서 object 발생의 인과관계를 파악해 output을 조절할 수 있는 모습을 보여줬다 !
그리고, 비 현실적인 artifact들도 수리할 수 있었다 !
정도가 될 것 같습니다 ^_^
