
6장 - 일반적인 머신 러닝 워크플로
- 데이터 준비
데이터 전처리 목적
: 주어진 원본 데이터를 신경망에 적용하기 쉽도록 만드는 것
- 벡터화 , 2. 정규화 , 3. 누락된 값 다루기 등
벡터화
-> 신경망에서 모든 입력과 타깃은 일반적으로 부동 소수점 데이터로 이루어진 텐서여야 한다.
먼저 , 텐서로 변환해야 한다.
-> 이 단계를 데이터 벡터화 라고 한다.
값 정규화
- 데이터를 그레이스케일 인코딩인 0-255 사이의 정수로 인코딩 했다.
이 데이터를 네트워크에 주입하기 전에 float32 타입으로 변경하고 255로 나누어서 최종적으로 0-1사이의 부동 소수점 값으로 만들었다.
정규화하여 , 평균 0 , 표준편차 1이 되도록 만듬 (정규분포)
-> 균일하지 않은 데이터 : 업데이트 할 그레디언트가 커져 네트워크에 수렴하는 것을 방해
- 적은 값을 취해야한다 .
- 균일해야한다.
x -= x.mean(axis=0)
x /= x.std(axis=0)
위 코드를 하는 이유는
정규화를 하기 위해서이다.
여기서 ,
x.mean(axis=0) 이란 ,축 0을 기준으로 잡고 , 나머지 축의 평균이 나온다.
누락값 채우기
- 수치형 특성일떄 , 0으로 하는 것보단,
평균이나 중간값으로 대체하는 것이 나을 것이다.
평가 방법 선택
- 모델의 목적은 일반화를 달성하는 것이다.
평가방법 3가지
- 홀드아웃 검증 : 데이터가 풍부할 때 사용
- k - 겹 교차 검증 : 홀드아웃 검증을 사용하기에 샘플 개수가 적을때
- 반복 k-겹 교차 검증 : 데이터가 적으나 정확한 모델 평가가 필요할떄 -> 신뢰성 good
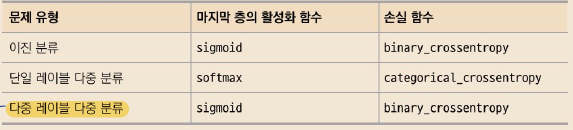
올바른 손실 함수 선택하기
- 손실 함수
- 주어진 미니 배치 데이터에서 계산 가능해야한다.
- 미분 가능해야 한다.
과대 적합 모델 만들기
- 층을 추가
- 층의 크기를 키운다
- 더 많은 에포크 동안 훈련한다
일반화 성능 최대화 하기
- 층을 추가하거나 제거
- 드롭아웃 추가
- 모델이 작다면, l1이나 l2 규제 추가
- 하이퍼파라미터를 바꾸며 시도(층의 유닛 개수, 옵티마이저 학습률등)
- 데이터 큐레이션이나 특성 공학을 시도해보기 -> 더 많은 데이터 수집 or 더 나은 특성 개발
또는 유용하지 않을 것 같은 특성 제거
추론 모델 배치하기
- 파이썬이 아니라 다른 방식으로 모델 저장
- 제품 모델은 훈련이 아니라 예측을 만들기 위해서만 사용된다.(이 단계를 '추론'이라고 한다)
배포방법
- 1.rest api로 모델 배포하기
- 2.장치로 모델 배포하기
- 3.브라우저에 모델 배포하기
추론 모델 최적화
추론을 위한 모델 최적화는 가용 전력과 메모리에 엄격한 제한이 있는 환경이나 응답속도에 대한 요구 사항이 높은 에플리케이션에 모델을 배포할 때 특히 중요하다. -> 경량화
모델을 tensorflow.js로 임포트하거나 , 텐서플로 라이트로 내보내기 전에 항상 최적화 해야한다.
- 가중치 가지치기
- 가중치 양자화 ->예) 정수로 압축

밑거름이라고생각합니다