
- 다양한 워크플로
Sequential 모델 , Dense층에 익숙해졌고 훈련,평가, 추론을 위해
내장된 compile(),fit(),evaluate(),predict() api를 사용해보았다.

케라스에서 모델을 만드는 여러 방법
- Sequential 모델
-
가장 시작하기 쉬운 api 이다 . 기본적으로 하나의 파이썬 리스트이다.
따라서 단순히 층을 쌓을 수 만, 있다. -
Sequential모델은 사용하기 쉽지만 적용할 수 있는 곳이 극히 제한된다.
하나의 입력과 하나의 출력을 가지며 순서대로 층을 쌓은 모델만 표현할 수 있다.
- 함수형 api
- 그래프 같은 모델 구조를 주로 다룬다. 이 api는 사용성과 유연성 사이의 적절한 중간 지점에 해당된다. 따라서 가장 널리 사용되는 모델 구축 api
- Model 서브 클래싱
- 모든 것을 밑바닥 부터 직접 만들 수 있는 저수준 방법이다.
모든 상세한 내용을 완전히 다 제어하고 싶을 경우 적절
<Sequential 모델>
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64,activation= "relu"),
layers.Dense(10, activation = "softmax")
])
- 동일한 모델을 add() 메소드 사용하기 -> 파이썬에서 append와 비슷
model = keras.Sequential()
model.add(layers.Dense(64,activation = "relu")
model.add(layers.Dense(10,activation= "softmax")
가중치
층의 가중치 크기가 입력 크기에 따라 달라진다.
즉 , 입력 크기를 알기 전까지 가중치를 만들 수 없다.
- 가중치를 생성하려면 어떤 데이터로 호출하거나 입력 크기를 지정하여 build()메서드를 호출 해야한다.
예)

예2)

model.build(input_shape=(None,3))
여기서 ,
-
None은 sample갯수
-
3은 특성의 갯수이다
summary()
build() 메서드가 호출된 후 디버깅에 유용한 summary()메서드를 사용하여 모델 구조를 출력할 수 있다.
model.summary()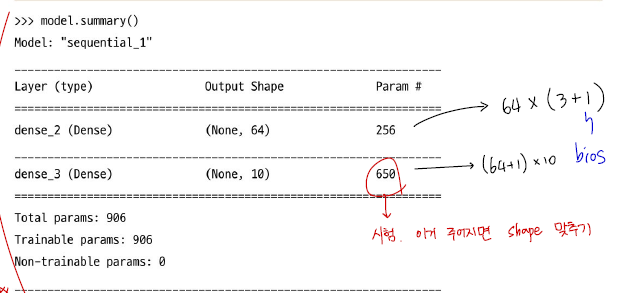
- 여기서도 , build 메서드를 호출하기 전까지는 summary() 메서드를 호출할 수 없다.
sequential모델의 가중치를 바로 생성하는 방법
model = keras.Sequential()
model.add(keras.Input(shape=(3,)))
model.add(layers.Dense(64,activation="relu")- model.add(keras.Input(shape=(3,))) -> 이 코드가 중요
<함수형 api>
-
Sequential모델은 사용하기 쉽지만 적용할 수 있는 곳이 극히 제한된다.
하나의 입력과 하나의 출력을 가지며 순서대로 층을 쌓은 모델만 표현할 수 있다. -
실제론, 다중입력과 다중 출력 또는 비선형적인 구조를 가진 모델을 자주 만날 수 있다.
예제 코드 층 2개)
inputs = Keras.Input(shape=(3,), name="my_input")
features = layers.Dense(64,activation="relu")(inputs)
outputs = layers.Dense(10,activation='softmax")(features)
model= keras.Model(inputs=inputs, outputs=outputs)
- inputs = keras.Input(shape=(3,) , name ="input")
inputs.shape
-> (None,3)
inputs.dtype
-> float32
위 같은 객체를 심볼릭 텐서라고 부른다. 실제 데이터를 가지고 있지는 않지만 , 사용할 떄 모델이 보게 될 데이터 텐서의 사양이 인코딩되어 있다. 즉 , 미래의 데이터 텐서를 나타낸다.
다중입력, 다중 출력 함수형 모델
vocabulary_size = 10000 # layer를 3개를 만듬
num_tags = 100
num_departments = 4
title = keras.Input(shape=(vocabulary_size,), name="title")
text_body = keras.Input(shape=(vocabulary_size,), name="text_body")
tags = keras.Input(shape=(num_tags,), name="tags")
features = layers.Concatenate()([title, text_body, tags])
features = layers.Dense(64, activation="relu")(features)
priority = layers.Dense(1, activation="sigmoid", name="priority")(features)
department = layers.Dense(
num_departments, activation="softmax", name="department")(features)
model = keras.Model(inputs=[title, text_body, tags], outputs=[priority, department])
- feature = layers.Concatenate()([title,text_body,tags])
-> call함수를 부르는 것 .
- feature = layers.Concatenate([title,text_body,tags])
Concatenate는 그냥 이름이다 (클래스의)
-> init 함수를 부르는 것
- model = keras.Model(inputs = [title,text_body,tags] ,outputs = [priority,department])
-> 묶어서 주면 된다.
입력과 타깃 배열 리스트를 전달하여 모델 훈련하기
import numpy as np
num_samples = 1280
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
priority_data = np.random.random(size=(num_samples, 1))
department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data],
epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict([title_data, text_body_data, tags_data]) 1.priority_data = np.random/random(size=(num_samples,1))
2.department_data = np.random.random(0,2,size = (num_samples,num_departments))
loss = ["mean_squared_error" ,"categorical_crossentropy"].
metrics = [["mean_absolute_error"],["accuracy"]]) -> 꺽새를 써줘야한다
위 코드 인덱스 순서대로 각각 1,2에 적용된다.
loss={"priority": "mean_squared_error", "department": "categorical_crossentropy"},
metrics={"priority": ["mean_absolute_error"], "department": ["accuracy"]})
이렇게 받을 수 도 있습니다.
함수형 api의 장점: 층 연결 구조 활용하기
- keras.utils.plot_model(model,"ttt.png")
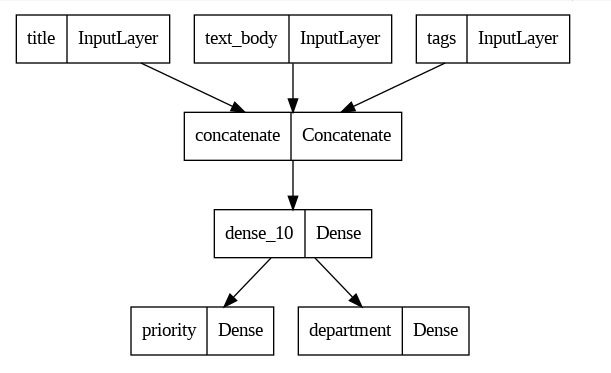
이 그림 설명을 하자면,
input shape = 3개
input_layer = 1개
hidden_layer = 1개
output_layer = 1개
output shape = 2개
입출력 크기를 추가
- keras.utils.plot_model(
model,"ttt.png" , show_shapes =True)
show_shapes 가 그런 기능을 한다.
< Model 서브 클래싱>
- __ init __ () 메서드에서 모델이 사용할 층을 정의한다.
- Call()메서드에서 앞서 만든 층을 사용하여 모델의 정방향 패스를 정의한다.
- 서브 클래스의 객체를 만들고 , 데이터와 함꼐 호출하여 가중치를 만든다.
간단한 서브클래싱 모델
class CustomerTicketModel(keras.Model): #call이란 메소드 , predict할떄 불린다. ,init이랑 call을 override한것
def __init__(self, num_departments):
super().__init__() #super() 중요하다.
self.concat_layer = layers.Concatenate()
self.mixing_layer = layers.Dense(64, activation="relu")
self.priority_scorer = layers.Dense(1, activation="sigmoid")
self.department_classifier = layers.Dense(
num_departments, activation="softmax")
def call(self, inputs):
title = inputs["title"] #input안에 들어있는 것 , 딕셔너리로 와야된다.
text_body = inputs["text_body"]
tags = inputs["tags"]
features = self.concat_layer([title, text_body, tags])
features = self.mixing_layer(features)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, department<클래스의 객체를 만들고 , 호출할떄 가중치를 만든다)
model = CustomerTicketModel(num_departments=4)
priority, department = model({"title" :title_data , "text_body" :text_body_data, "tags" : tags_data})
