2023 CVPR에 올라온 논문입니다.
Painter라고 불리는데 vision model에서의 GPT-3가 되기를 희망한다고 합니다.
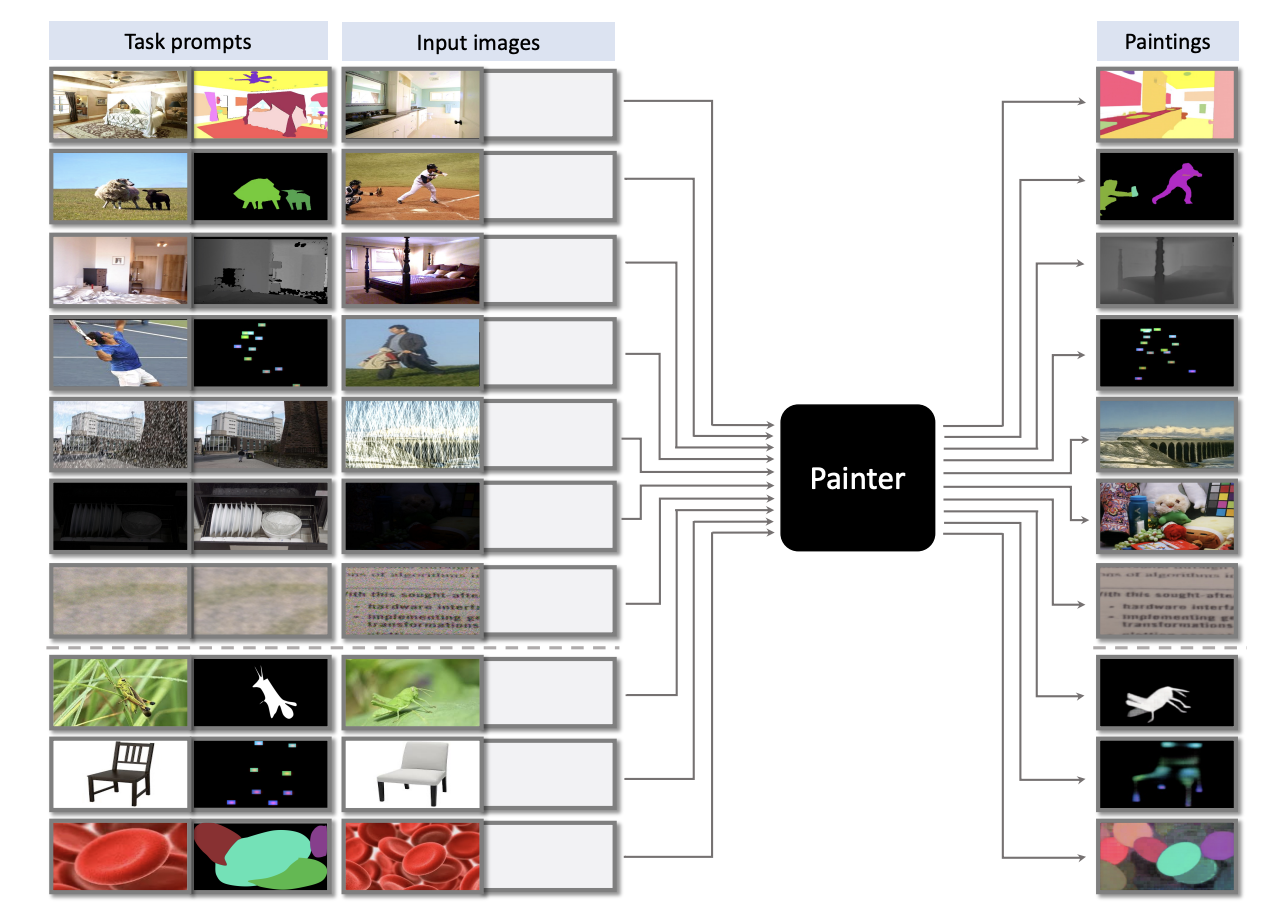
Abstract
주요 요점입니다.
- In-context learning 사용한 모델 만듦
- 비전의 output 표현은 굉장히 다양해서 general purpose task를 정의하기 어려운데 output을 image로 재정의하여 해결
- 여러 task에 대해 좋은 성능을 보임
Introduction
NLP에서 사용되는 In-context learning를 vision에서 사용하고자 하는 시도가 잘 없었습니다. 그리고 여전히 해결해야할 숙제로 남아있습니다.
In-context learning : 프롬프트의 내용만으로 하고자 하는 task를 ai가 이해하여 수행하는 방법을 의미, 빠르게 새로운 task에 적용할 수 있고 따로 모델 파라미터의 업데이트가 필요하지 않다. (zero, one, few-shot 과 동일한 의미)
NLP에서의 In-context learning과 vision에서의 In-context learning은 두가지 차이점이 존재합니다.
- NLP는 주로 언어 이해, 생성으로만 구성되어있어서 output space가 이산적인 언어 토큰의 sequence로 통합될 수 있습니다. 그러나 vision task는 다양한 입자(아마도 픽셀을 의미)와 각도의 시각적 입력을 추상화한 것입니다. 그래서 출력이 매우 다양하고 task에 맞는 구조와 loss 함수를 사용합니다.
- NLP의 input과 ouput의 space가 동일하기 때문에 ouput을 그대로 input으로 활용할 수 있습니다. 그러나 vision task에서는 general purpose task prompts나 instructions를 어떻게 정의할지 명확하지 않습니다.
이전의 방법들은 vision문제를 연속된 공간을 이산화하여 NLP문제로 유사하게 변환해서 문제를 해결을 시도하였습니다. 그러나 본 논문에서는 이미지가 이미지를 말해준다고 믿고 있고, 비전 중심의 솔루션을 제시합니다.
대부분의 dense-prediction vision문제는 image inpainting으로 공식화 될수 있다는 것을 발견하였습니다. (예측은 주어진 이미지에 대해 지워진 이미지를 다시 그리는 것과 동일)
이게 무슨말인가 이해가 안될 수 있습니다. 논문의 다음 글을 읽어보면 vision task의 output을 모두 3 channel의 tensor로 표현한다고 합니다. 이미 3채널로 표현되는 것 말고 semantic segmentation, instance segmentation, keypoint dection 등을 3채널 tensor로 변환하겠다는 의미입니다.
Approach
이 논문의 주요 아이디어는 output space가 image가 되도록 vision task를 재구성 하는 것입니다.
Redefining outputs space as images
input이미지의 크기는 보통 입니다. task의 정답은 task t에 따라 다양한 크기를 가지고 있는데 이를 라고 정의합니다. 그리고 이를 image space() 가 유지되도록 재정의 합니다(). 이 방법의 철학은 RGB space에서 본래의 공간정보간의 관계를 유지하도록 하는 것입니다.
이제 3채널로 나오지 않는 각 task에 대해 살펴보겠습니다.
Monocular depth estimation
NYUv2 데이터 셋을 사용합니다. groud truth deptch는 0에서 10사이의 값을 가지는데 을 곱해 0에서 255사이의 값을 가지도록 만들어 줍니다. 그리고 3채널이 모두 같은 값을 가지도록 합니다.(기존 depth 하나의 채널을 복사)
추론을 할 때는 3채널의 평균을 내고 inverse linear transformation(여기서는 )을 거쳐 0에서 10의 값을 도출합니다.
Semantic segmentation
Categories 개수를 L이라고 하고 이 L을 b-base system을 이용해 3채널 텐서로 나타내야 합니다.
150개의 카테고리를 가진 ADE-20K를 예시로 보겠습니다.
은 카테고리를 의미하며 0과 L 사이의 범위를 가집니다.
왜 이런방식을 사용하는지에 대한 자세한 이유는 없는 것 같은데 잘 모르겠네요...
Keypoint detection
참고 논문의 heatmap-based Top-down pipeline을 따른다고 합니다.
keypoint detection을 2개의 채널을 이용해() 17개의 카테고리로 분류하는 것과 나머지 하나의 채널()을 이용해 클래스와 무관하게 keypoint localization을 하는 것으로 분리합니다.
Panoptic segmentations
semantic segmentation과 instance segmention의 결합 task입니다. 본 논문에서는 각 instance마다 랜덤으로 색상을 부여한다고 합니다. 그러나 이러한 방법은 model이 최적화 되기 어렵기 때문에 SOLO(Segmenting objects by locations) 방법을 사용하여 색을 할당합니다.
Image restoration
image denoising, image deraining, low-light image enhancement가 이 task에 포함되는데 이미 output이 RGB space이기 때문에 별도의 변환이 필요없습니다.
MIM(Masked Image Modeling Framework)
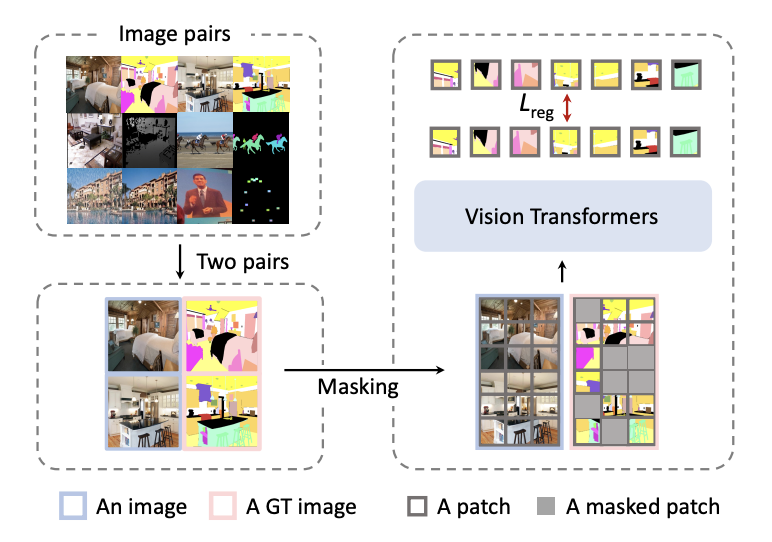
위의 그림은 MIM의 pipline을 나타낸 것입니다. 이는 input format, architecture, loss function 세 개의 주요 요소로 이루어져 있습니다. 하나씩 살펴보겠습니다.
Input format
훈련 시에 같은 task인 두 개의 이미지를 concat합니다.(이미 augmentation이 적용된 상태) 그리고 랜덤하게 masking을 하여 지워진 부분을 재구성하도록 훈련합니다. masking방법은 그림에서 보는 것 처럼 block-wise maksing 전략이며 75%까지 잘 동작함을 확인했다고 합니다.
Architecture
인코더로 stacked Transformer block으로 구성된 ViT를 사용했고 이 block에서 나온 4개의 feature map들을 공평하게 이어붙입니다. 그리고 3개의 head를 사용해 원래 해상도에 각 패치를 매핑합니다.(로 구성되어 있음)
입력에 input, output을 모두 포함하므로 입력 이미지의 해상도가 기존 훈련 프로세스 보다 클 수 있고, 계산 비용도 커질 수 있습니다. 이 문제를 해결하기 위해 input, output이미지의 feature를 초기에 합치는 방법을 사용합니다. 구체적으로 input, output 이미지가 병렬적으로 들어오고 3개정도의 블록을 거친 후에 그 patch별로 feature를 더합니다. 이 방법을 쓰면 계산 비용도 줄고 성능 저하도 없다고 합니다.
Loss function
Smooth L1 loss를 사용합니다.
In-context Infernece
가장 위의 그림이 In-context infrence를 설명하는 그림입니다. task prompt의 정의는 NLP에 대한 깊은 이해를 필요로 하지 않습니다. 그러나 vision model을 잘 이해하고 시각 도메인과 잘 맞는 context를 사용합니다.
task prompt가 다르면 결과도 달라질 수 있는데 본 논문에서 이에 대한 방법도 탐구합니다. 첫번째로 heuristic한 방식으로 찾는 것이고 두번째는 task prompt를 학습가능한 텐서로 정의하고 model을 freez한 뒤 training loss가 적은 것을 task prompt로 쓰는 방법입니다.
Experiments
사용한 dataset과 training detail은 넘어가도록 하겠습니다.
Results
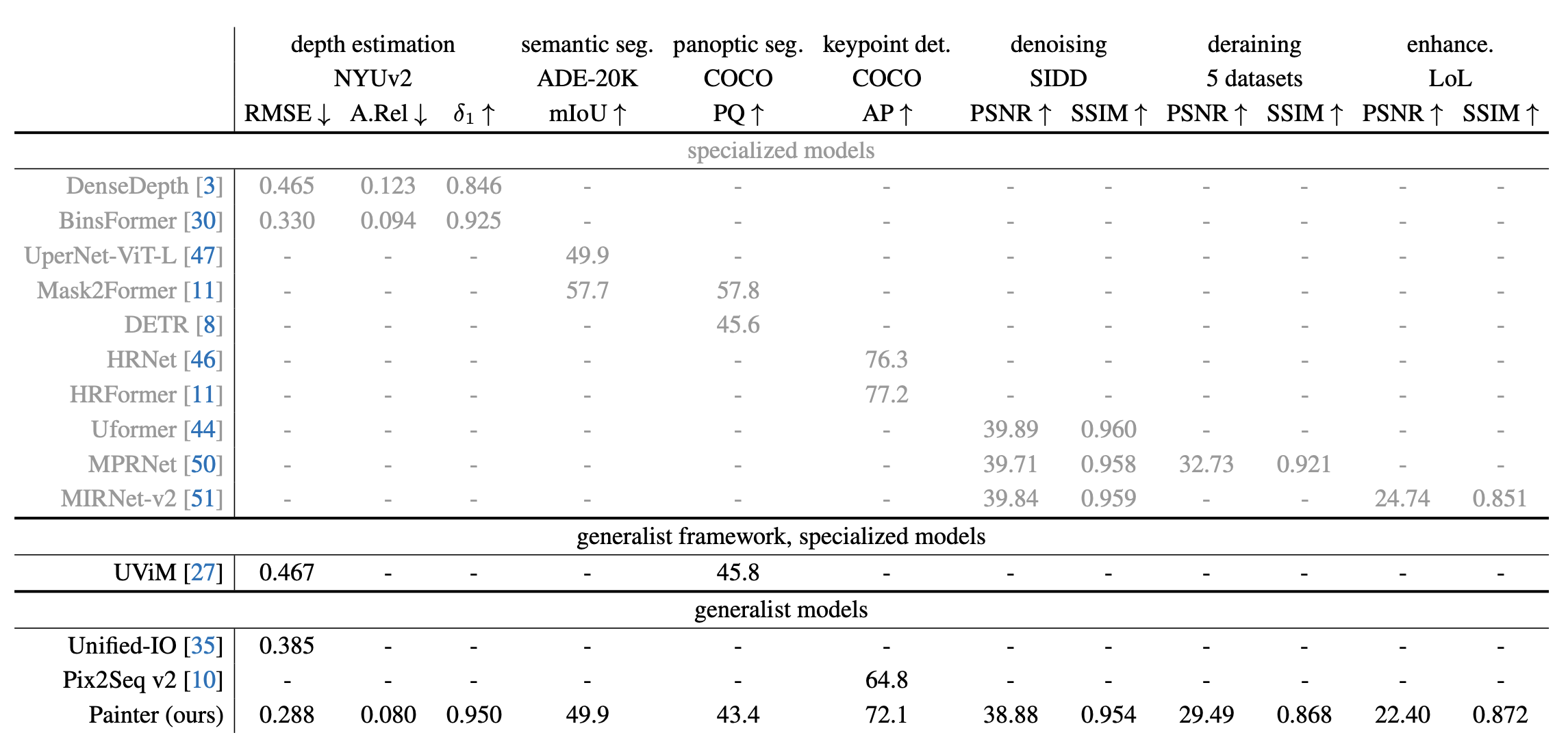
System-level comparison
depth estimation 부분에서는 더 좋은 성능을 보이고 다른 task에서도 비등비등한 성능이 나옵니다.(성능이 아직 기존의 모델을 능가하는 것은 아니지만 input image resolution을 늘리면 더 좋은 성능이 나올 수 있다고 합니다)
Joint training vs separate training
joint는 기본적으로 섞어서 수행하는 훈련이라고 보시면 되고 separate training은 하나의 task만 동일한 훈련 프로세스로 훈련한 것으로 보시면 됩니다. keypoint를 제외하고는 joint training이 더 좋은 성능을 보여줍니다.

Prompt Tuning
learned prompts 방식이 가장 성능이 좋지만 random prompts와 크게 다르지 않습니다.

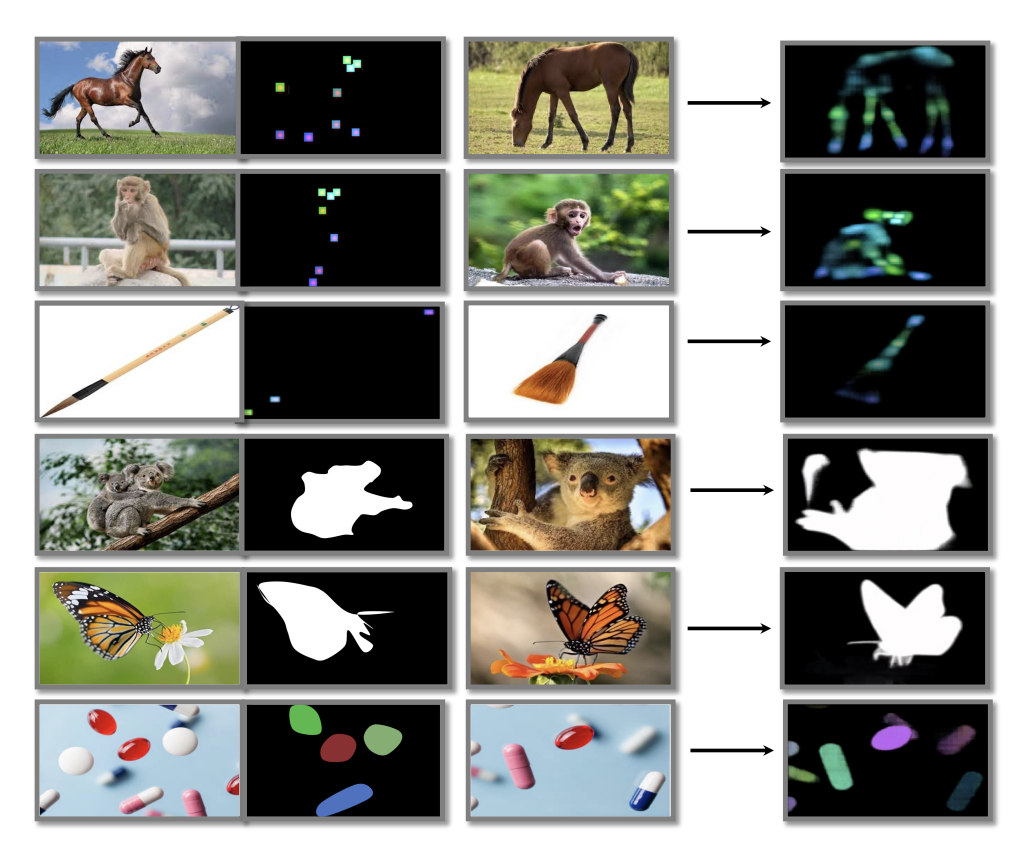
Generalization
Discussion & Conclusion
본 논문에서는 비전 중심의 in-context learning을 처음으로 제시하였고 높은 성능을 보여주었습니다. 이후 내용은 논문의 요약이므로 패스하겠습니다.
