IQA 대회를 하다가 발견한 논문입니다. 전체적인 내용을 이해하기 위해 논문을 살펴보기로 했습니다.
Abstract
NR-IQA(원본없이 이미지 품질 측정) task는 사람의 주관적인 인식에 따라 평가하는 것을 목표로 합니다. 현존하는 NR-IQA 방법들은 GAN-based 왜곡에 대한 점수예측하는 요구사항을 충족하지 못합니다. 이를 위해 저자는 GAN기반 왜곡 이미지에 대한 성능을 향상시키기 위해 Multi-dimension Attention Network for no-reference Image Quality Assessment(MANIQA)를 제안했습니다. ViT를 통해 feature를 추출하고, global, lobal 상호작용을 강화시키기 위해 Transposed Attention Block(TAB)과 Scale Swin Tranfomer Block(SSTB)를 제안하였습니다. 이 두 모듈은 attention 매커니즘을 채널차원과 공간차원에 각각 적용합니다. 이러한 다차원 방식의 모듈은 전역적, 지역적 이미지 영역의 상호작용을 증가시킵니다. 마지막으로 patch 가중치 품질 예측을 위한 듀얼 브랜치 구조는 각 patch 점수의 가중치에 의존하여 최종 점수를 예측합니다.
실험 결과는...당연히 SOTA라고 얘기를 하고 코드는 링크에 모두 나와있습니다.
Introduction
깨끗한 원본 품질의 이미지는 획득, 압축, 저장, 전달, GAN알고리즘 기반 복원까지 전체 순환과정에서 품질 저하가 일어날 수 있으며, 수신한 시각 정보가 손실될 수 있습니다. 이러한 저 품질 이미지는 사회에 좋지 못한 영향을 끼칩니다. 한편으로 facebook, instagram과 같은 SNS에 대량의 사진들이 업로드되고 공유됩니다. 이 말은 저품질 이미지가 사용자의 시각적 감정에 나쁜 영향을 줄 수 있음을 말합니다. 또 다른 경우로, 저품질 이미지는 종종 자율주행 차량을 방해합니다. 이러한 이유로 이미지 품질을 정확하게 예측하는 것을 일상과 산업에서 중요한 역할을 합니다.
일반적으로 객관적인 품질 지표는 참조 이미지에 따라 FR-IQA, NR-IQA로 나뉩니다. 이전의 범용 NR-IQA 방법은 Blur, JPEG, Noise같은 왜곡된 합성 이미지나 실제이미지를 위한 품질 평가에 초점을 둡니다. 그러나 이는 GAN기반의 이미지 생성 알고리즘이 나오면서 평가가 한계를 가지게 됩니다. 이와 관련한 논문도 있는데 이전 기법들은 dataset에 따라 성능이 안정적이지 못하고, 딥러닝이 생각하는 품질과 사람이 생각하는 품질에 대해 차이도 있습니다.
GAN기반 왜곡 이미지에 대한 부족한 점수를 생각해 논문에서 MANIQA를 제안합니다. 이 방법은 4가지 컴포넌트로 이루어져 있습니다.
1. ViT
2. transposed attention block(TAB)
3. scale swin transformer block(SSTB)
4. dual branch structure
구조는 Proposed Method의 첫번째 그림을 보면 쉽게 이해할 수 있습니다.
이 모듈을 이용하면 두가지 장점이 있는데 첫번째는 ViT에서 각각 다른 정보를 포함하는 4개의 채널을 가져오는데, TAB에서 품질 점수 관점에서 중요한 채널의 가중치를 재정렬 하는 것입니다. 두번 째로는 이 블록에서 생성된 attention map이 암시적으로 global context를 가지며 다운 스트림 로컬 상호작용을 보완해줍니다. 이미지의 패치간 로컬 상호작용을 강화하기 위해 SSTB를 적용했습니다. 훈련 프로세스 안정과 residual 조정을 위해 scale factor 가 적용되었습니다. 이 두 방식은 협력적으로 다른 전역, 지역 이미지 영역에 대한 상호작용을 증가시킵니다.
마지막으로 dual branch 구조는 weighting, scoring으로 나눠져 있는데 최종 점수를 얻기 위해 제안되었습니다. 저자는 이미지 중앙에 있는 두드러진 물체가 인간의 시각시스템에 눈에 띄지만 항상 고품질은 아니라고 합니다. 주목해야할 영역과 고품질 영역의 불일치 때문에 Hadamard Product를 통해 가중치 맵을 균형있게 조정합니다.
Related Work
이전 방법론들에 대한 설명 및 IQA에 대한 설명이니 뛰어넘겠습니다.
Proposed Method
본 논문의 목표는 다차원 정보를 다룰 수 있는 모델 개발이 목표로 모델의 구조는 아래와 같습니다.
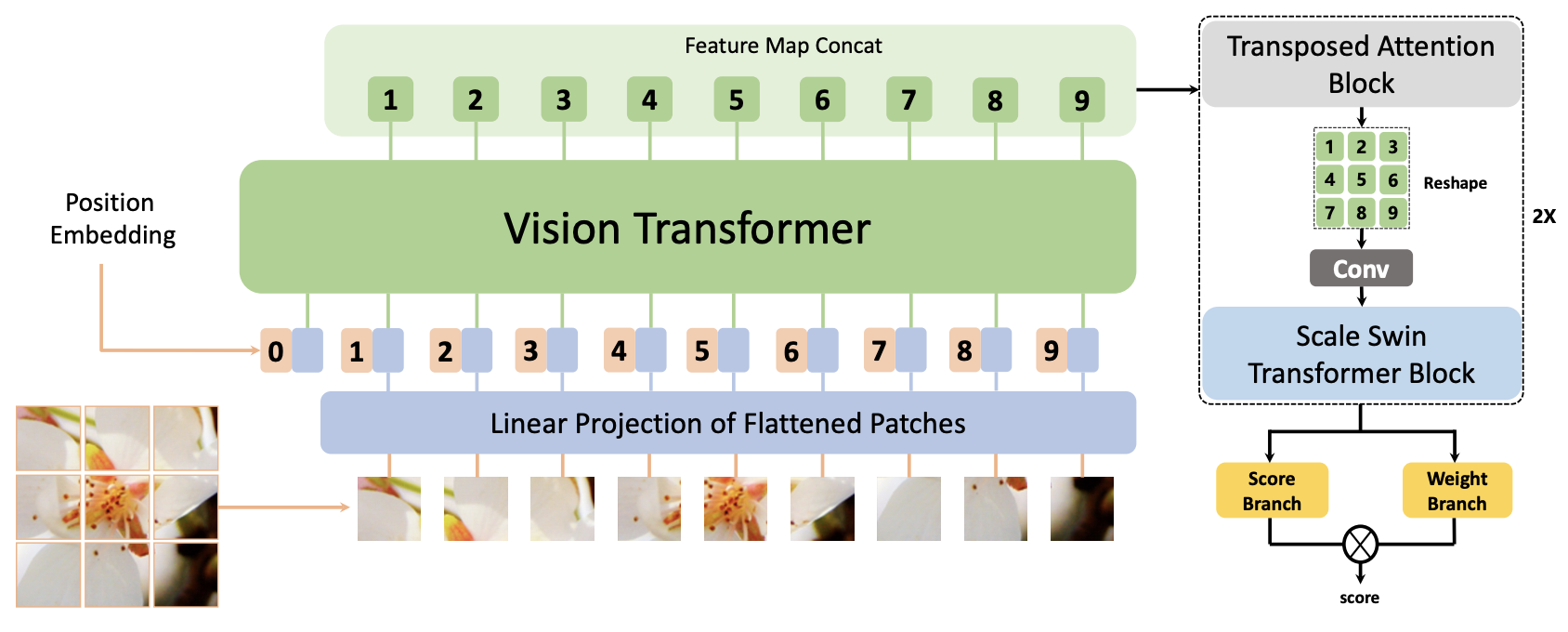
Overall Pipeline
Input 이미지:
ViT에서 추출된 이미지:
는 ViT의 layer를 나타내며 1부터 12까지 12계층이 있습니다. b는 배치, c는 채널입니다. 이전에 ViT에서 4개의 layer를 가져온다고 했는데 7, 8, 9, 10계층의 feature를 가져옵니다. 그리고 이 feature들은 concatenate하여 다음 모듈로 넘겨줍니다. 이를 다음 식으로 표현합니다.
다음으로 TAB, SSTB를 거치고 마지막에는 최종 점수를 계산하기 위해 아래 식을 계산합니다.
s는 점수, w는 가중치라고 생각하면 됩니다. N은 하나의 이미지에 대한 patch의 개수입니다.
Transposed Attention Block
Transformer에서 중요한 역할을 하는 SA(self-attention)은 key-query 행렬 곱의 상호작용을 통해 공간 차원내의 전역 연결을 구축합니다. 그러나 이는 다른 차원들의 많은 정보들을 무시한다고 합니다. 이 문제를 완화하기 위해 저자는 TAB를 제시했고 구조는 아래와 같습니다.
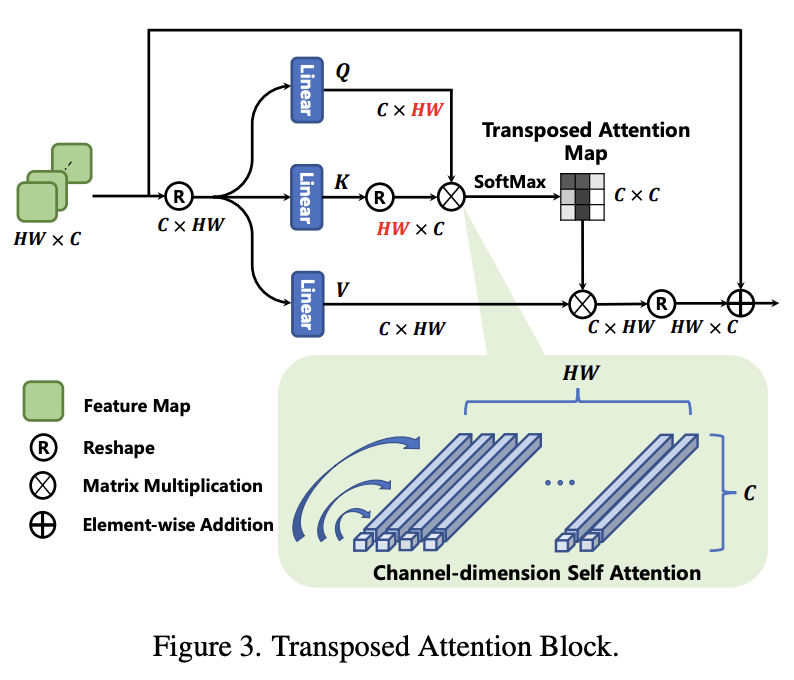
TAB는 공간차원이 아닌 채널 차원으로 SA를 적용하여 교차 공분산을 계산하고 암시적으로 전역 context를 인코딩하는 attention map을 생성합니다. 수식으로 나타내면 아래와 같습니다.
는 Q,K,V의 공간 차원을 나타냅니다. 이 모듈은 기존 SA에서 layer normalization과 MLP계층을 제거했습니다. 전자는 layer norm이 pixel-wise channel-context normalization이기 때문이고 후자는 복잡성이 증가하여 모델 일반화에 영향을 미치기 때문이라고 합니다.
Sacle Swin Transformer Block
아래 그림은 SSTB의 구조입니다. STL, Conv 레이어로 구성되어 있습니다.
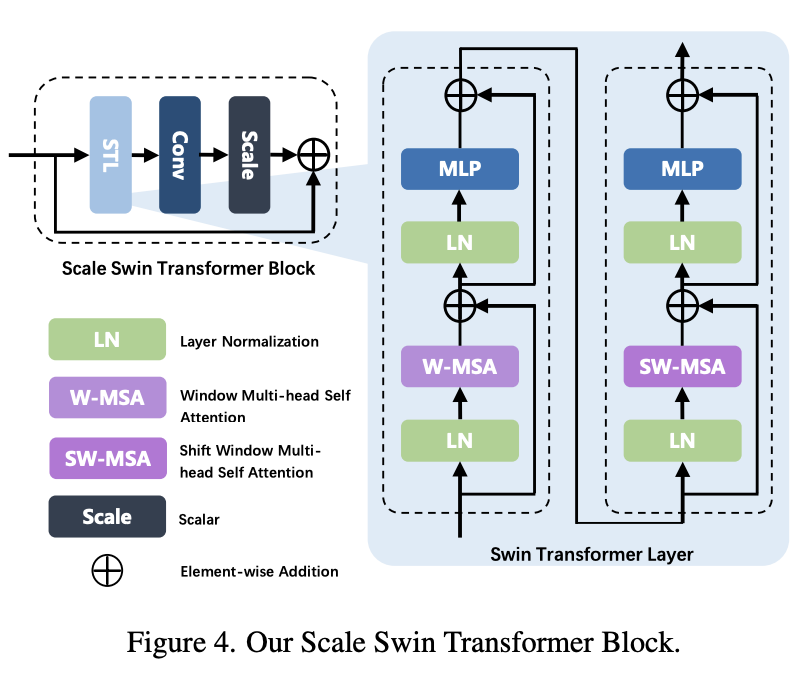
i는 블록의 stage이고 j는 STL의 레이어 순서 입니다. 처음 볼 때는 헷갈렸는데 구조 자체가 TAB와 SSTB가 묶여있어서 그렇습니다. 아래 코드를 보면 더 쉽게 이해할 수 있습니다.
def forward(self, x):
_x = self.vit(x)
x = self.extract_feature(self.save_output)
self.save_output.outputs.clear()
# stage 1
x = rearrange(x, 'b (h w) c -> b c (h w)', h=self.input_size, w=self.input_size)
for tab in self.tablock1:
x = tab(x)
x = rearrange(x, 'b c (h w) -> b c h w', h=self.input_size, w=self.input_size)
x = self.conv1(x)
x = self.swintransformer1(x)
# stage2
x = rearrange(x, 'b c h w -> b c (h w)', h=self.input_size, w=self.input_size)
for tab in self.tablock2:
x = tab(x)
x = rearrange(x, 'b c (h w) -> b c h w', h=self.input_size, w=self.input_size)
x = self.conv2(x)
x = self.swintransformer2(x)
x = rearrange(x, 'b c h w -> b (h w) c', h=self.input_size, w=self.input_size)
score = torch.tensor([]).cuda()
for i in range(x.shape[0]):
f = self.fc_score(x[i])
w = self.fc_weight(x[i])
_s = torch.sum(f * w) / torch.sum(w)
score = torch.cat((score, _s.unsqueeze(0)), 0)
return score추출된 feature는 Conv로 들어갑니다. 식은 아래와 같이 표현합니다.
여기서 는 scale factor를 나타냅니다(위의 와는 다름)
이 구조에는 두가지 이점이 있습니다.
1. conv layer는 invariant filter이므로 translational equivariance를 향상시킵니다.
2. scale fator 는 residual connection을 통해 훈련 안정성시킵니다.
Patch-weighted Quality Prediction
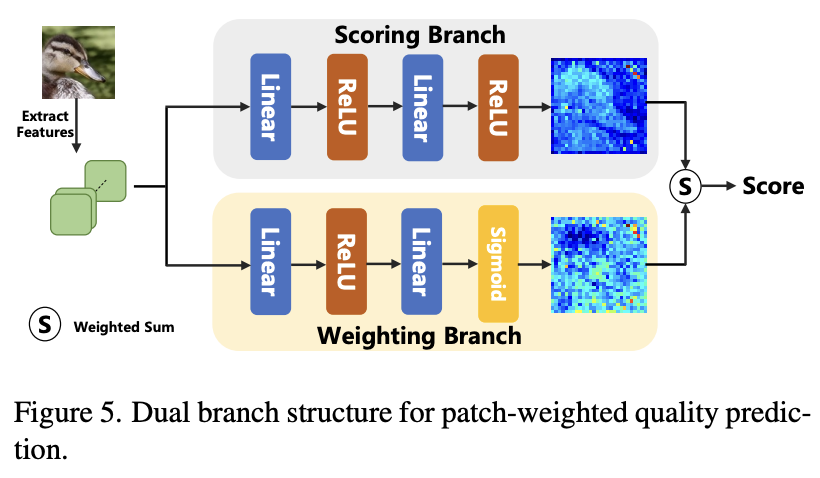
본 논문에서 위 그림처럼 patch-weighted 품질 예측을 위해 dual branch 구조를 디자인 했습니다. 저자는 품질 점수가 이미지의 영역에 따라 의존적이라고 생각하기에 이 구조를 통해 영역마다 가중치를 부여하는 방법을 선택하였습니다.
논문 문장을 보면 overfitting을 피하는 것을 고려해 저자는 scoring branch와 weighting branch가 제약 매커니즘을 만들고, 마지막 점수는 scoring과 weighting 브랜치의 균형을 고려해야한다고 합니다.
이 말이 잘 이해가 안되는데, 저는 코드를 보면 행렬 곱을 하고 torch.sum(w)을 나누면서 그런 균형을 잡는다는 의미로 받아들였습니다.
score = torch.tensor([]).cuda()
for i in range(x.shape[0]):
f = self.fc_score(x[i])
w = self.fc_weight(x[i])
_s = torch.sum(f * w) / torch.sum(w)
score = torch.cat((score, _s.unsqueeze(0)), 0)
return scoreExperiments
실험은 중요해 보이는 부분만 간단하게 가져왔습니다.
Implementation Details
훈련시 이미지는 랜덤하게 224 X 224로 crop하여 사용하였고 crop된 이미지에 horizontalflip을 랜덤하게 적용했습니다. test시에는 랜덤하게 20개의 이미지를 crop하여 그 이미지에 대해 품질점수를 예측하고 그 점수들의 평균을 사용했습니다.
Evaluation Criteria
여기서 기존 평가 metric과는 다른 PLCC, SROCC를 사용하는데 IQA task에서는 오래동안 사용한 것 같습니다.
는 각각 에 대한 정답과 예측 점수를 나타내며 는 각각에 대한 평균 값을 나타냅니다.
는 실제 정답과 예측 값에 대한 순위차이를 나타냅니다.
각 값의 범위는 [-1, 1]입니다.
Result & Ablation Study
다른 논문과 유사하게 SOTA를 달성했고 + 논문에서 제시하는 구조가 제일 좋다로 요약할 수 있겠습니다.
Conclusion
결론은 논문 전체적인 요약이니 개선 여지부분만 보겠습니다.
논문의 저자는 이 방법에 개선의 여지가 있다고 하는데 GAN 기반 왜곡이 문제를 일으키기는 하지만 특정 왜곡 타입을 정의하는 것이 더 진행하기 위해 중요하다고 합니다. 직역을 하니 정확히 이해가 어려운데 다른 GAN관련 모델에서 나온 이미지에 대한 추가학습이 필요하다는 것을 말하는 것 같습니다.
논문 링크
