0. Introduction
iGPT에 이어서 2021 ICLR에서 게시된 논문을 살펴 보겠습니다. 논문의 원제목은
"AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE"입니다.
Vit의 특징을 나열해보면 다음과 같습니다.
- Image를 16 X 16 WORDS처럼 처리한다. 즉 전체 이미지를 patched sub image로 나눈다는 것을 의미합니다.
-
ViT는 BERT를 이미지에 적용한 것과 매우 유사한데 특히 Patch Embedding을 통해 이미지 data를 projection 합니다. 이와 더불어서 BERT와 같이 다양한 Embedding(Positonal Embedding, Token embedding)을 합니다.
-
ViT의 아키텍쳐는 GPT2와 비슷합니다.
-
Inductive bias가 cnn 계열에 비해 낮아서 성능이 좋게 나오는 것으로 해석됩니다.
-
Pre-training과 fine-tunning을 거치면서 성능을 끌어 올렸습니다. 특히나 더 많은 데이터를 사용하면 할 수록 성능이 높아집니다. 이를 Scaling UP이라고 표현 하였습니다.
위의 5가지를 중점적으로 살펴 보겠습니다.
1. 16 x 16 sub image로 변환

[출처] : https://arxiv.org/pdf/2010.11929.pdf
논문에 언급된 것을 풀어서 설명하면 Patch size가 16이라고 했을때 얼마나 총 패치의 개수(여기서는 단어의 개수 즉 MAX_Sequence_length)는 다음과 같은 공식으로 구할 수 있습니다.
**H : high
W : Width
P : Patch size**
2. Patch Embeddings
이렇게 sub image로 변환 후에 sequential한 데이터 처럼 사용하기 위해서는 Dense vector로 변환을 해야 합니다. 이와 관련된 공식은 논문에서 다음과 같이 언급되어 있습니다.
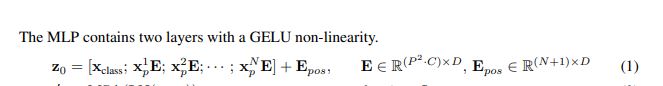
[출처] : https://arxiv.org/pdf/2010.11929.pdf
수학적으로 정리해보면 다음과 같습니다.
: k번째 image patch , size : [C, P, P] = [1,]
: []
= [1,] x [] = [1,D]
여기서 D는 사용자가 정해줘야 한다. 여기서 눈여겨 볼만한 점은 E는 learnable parameter라는 점이다. 이외에도 Token Embedding과 Positional Embedding 역시 학습의 대상입니다.(BERT가 그러하듯이)
3. Model Architecture
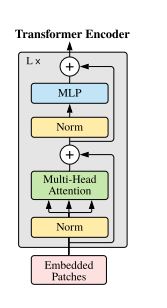
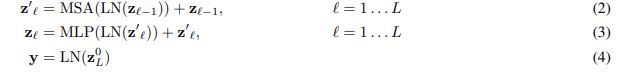
[출처] : https://arxiv.org/pdf/2010.11929.pdf
모델의 구조는 다음과 같이 GPT-2 와 비슷한 구조로 가지고 있습니다.
4. Inductive bias
ViT가 CNN 계열이 모델과 비교시 성능이 좋게 나오는 이유를 저자는 이렇게 해석 하고 있습니다. ViT는 애초에 이미지의 2차원 구조를 가정하지는 않습니다.

그에 반해 CNN 계열은 애초에 이미지 자체를 2차원 구조를 전제하고 다룹니다.
5. Performance

이 모델은 기본적으로 Pre-training과 fine-tunning으로 성능을 끌어올렸습니다.
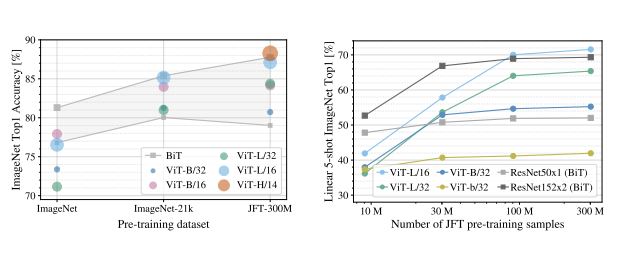
[출처] : https://arxiv.org/pdf/2010.11929.pdf
또한 위의 그래프와 같이 추가적인 데이터를 사용해서 모델의 사이즈를 더 크게 늘리면 즉 Scaling up하면 CNN 계열의 모델들과 비슷한 수준의 성능을 낼 수 있다고 말하고 있습니다.
참고 자료
