
0. Introduction
본 논문의 원제목은 "Generative Pretraining from Pixels"이다. 논문의 abstract를 보면 자연어 처리 분야에서 비지도 학습에 영감을 받아서, 이와 같은 유사한 모델들이 이미지에도 유용한 representation을 배울 수있는 지 살펴본 결과 기존 CNN기반의 모델과 비교했을때 상당히 좋은 결과를 얻었다는 것이다. 이 모델의 특징은 다음과 같다.
-
2D 입력 구조에 대해서 전혀 가정을 하지 않고 Autoregressively하게 pixels을 예측 했다.
-
Full color information을 Discretized information으로 바꾸고 컴퓨터 비전분야에서 자주 쓰이는 기법인 raster order을 사용해서 이미지를 token와 같이 sequential data로 처리 했다.
-
이미지 데이터로부터 representation을 학습하기 위해 permutation 을 사용했다.
-
모델이 만약 good representation을 가지고 있다면 classification task에서도 성공적일 것이라고 생각하고 아래의 2가지 방식으로 classification을 진행했다
- Linear probe at a specific layer
- Fine-tunning on all layer
-
낮은 generation loss를 가지면 good representation power를 지니고 model size가 커지면 good representation power를 역시 가진다.
이상 5가지를 하나 하나 살펴 보도록 하겠습니다.
1. Autoregressive
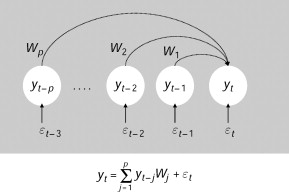
[출처] : https://www.sciencedirect.com/topics/mathematics/autoregressive-coefficient
autoregressive는 이전 시간의 관측값들을 통해서 현재 시점의 값을 예측하는 방식을 말합니다.
예를들어서 의 데이터를 가지고 을 예측 하는 것이라고 쉽게 이해 할 수 있습니다. 특히나 이러한 방식을 사용했기 떄문에 본 논문에서는 이미지의 2D 구조에 대한 어떠한 가정도 하지 않았습니다.
2. Image to sequential data
논문에서는 메모리의 요구조건을 들어서 224 x 224 x 3를 가지는 이미지가 너무나도 크다고 가정했습니다. 따라서 GPU에 fit하기 위해서는 resize가 필요하다고 했고 예를들어 이미지의 크기를 줄여 32 x 32 x 3 혹은 64 x 64 x 3 으로 했지만 이 역시도 역시 집약적으로 표현으로 했기에 크기가 큰 건 마찬가지 였습니다. 따라서 이에 대한 해법으로 color quantization을 하게 됩니다. 즉 image를 sequential data로 바꾸기 위해 기본적으로 quantization 기법을 사용했는데 그 방식은 다음과 같습니다.
-
이미지의 color data 좌표를 3차원 좌표공간에 찍는다.
-
k-means clustering을 사용한다. 본 논문에서는 k값으로 512를 사용했습니다.
-
각각의 고유한 ID를 각 color data에 할당합니다
-
각각의 고유한 ID를 Token과 같이 color-groups으로 사용 할수 있습니다.
아래 그림은 K-means clustering을 한 예시입니다.
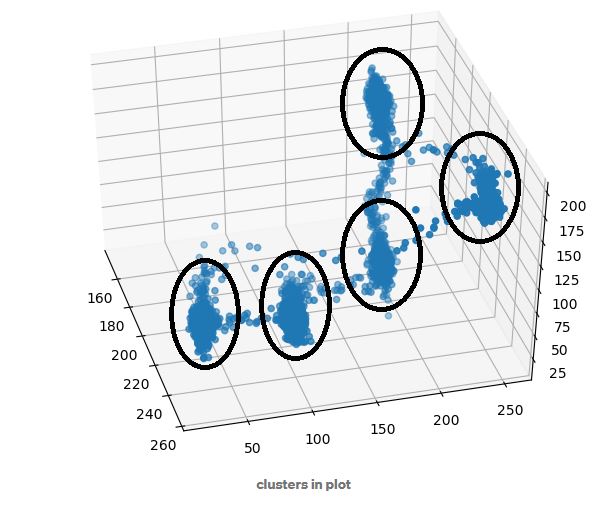
[출처] : https://buzzrobot.com/dominant-colors-in-an-image-using-k-means-clustering-3c7af4622036

[출처] : http://amroamroamro.github.io/mexopencv/opencv/kmeans_color_quantize_demo.html
이렇게 k =512개로 함으로서 마치 vocab size가 512개인 것처럼 가정 할 수 있습니다.

[출처] :https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
위에 그림에서도 보듯이 낮은 해상도로 크기를 조정하고 1D 시퀀스로 재구성하여 원시 이미지를 사전 처리합니다.
3. Representation
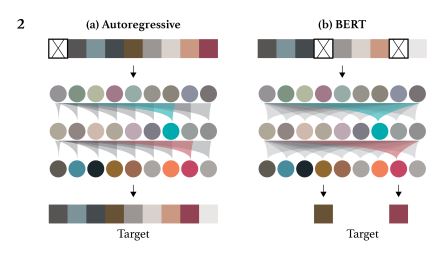
[출처] :https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
위의 과정을 거친 후 두 가지 pre-training 목표 중 하나인 autoregressive을 사용한 다음 픽셀 예측 또는 마스킹 픽셀 예측을 선택합니다. 이때 입력 데이터 X는 unlabeled datset이라는 점이라는 것을 명심해야 합니다. 지금 하고 있는 것은 unsupervised learning입니다.
간단히 여기서 모델의 아키텍쳐를 그림으로 나타내면 다음과 같습니다. GPT-2의 아키텍쳐와 비슷하니다.
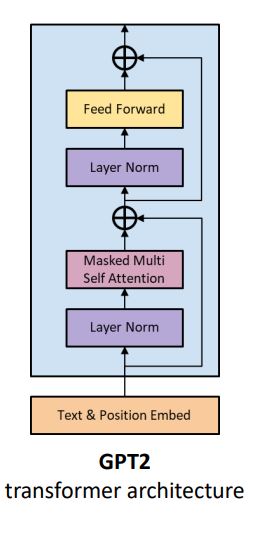
[출처]: https://www.researchgate.net/publication/335737829_Tracking_Naturalistic_Linguistic_Predictions_with_Deep_Neural_Language_Models
4. Representation Power
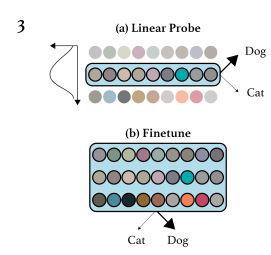
[출처] : https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
여기까지 왔다면 이제 위의 방식에 의해 linear probes or fine-tuning으로 모델을 평가하게 됩니다. 특히 여기서는 Classification taks로 확장을 합니다. 즉 만약 모델이 good representation을 학습 헀다면 classification 에서도 성공적일 것입니다. 이를 위해 linear probes or fine-tuning를 사용하는데 linear probes 전체 레이어 중 일부 레이어 하나만 선택해 classification에 사용하는 것이고 fine-tunning은 말 그대로 transformer의 전체 weight를 가져다가 사용하는 것입니다.
이렇게 했더니 놀라운 결과를 얻게 되는데 아래 그래프를 보시면 알 수 있습니다.
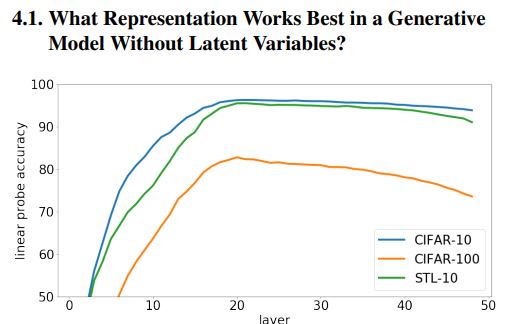
[출처] : https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
가로축은 몇번 째 layer 인지를 나타내고 세로축은 accuracy를 나타냅니다. 놀랍게도 중간 layer가 가장 성능이 좋게 나오는데 이를 해석해보면 이 모델은 encoder - decoder의 통합된 모델인데 encoder에서 decoder로 넘어가는 그 중간지점이 대략 20 layer정도 일것으로 해석할 수 있습니다.
5. Good representation을 얻기 위해선?
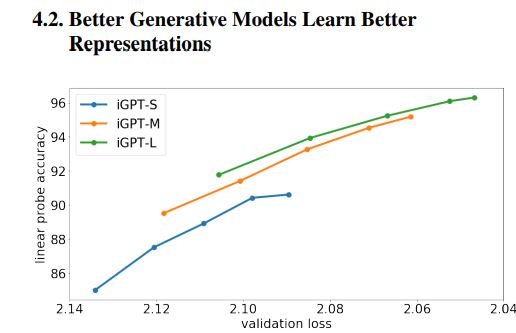
[출처] : https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
위의 그래프도 상당히 흥미롭습니다. 해석해보면 validation loss가 낮다는 것은 이는 곧 모델이 good representation을 학습 했다는 것이고 모델의 사이즈가 크면 클수록 이 역시 good representation을 학습 했다는 것으로 이해할 수 있습니다.
참고 자료
https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
https://buzzrobot.com/dominant-colors-in-an-image-using-k-means-clustering-3c7af4622036
https://deepgenerativemodels.github.io/notes/autoregressive/
