
문제 정의
구매 데이터를 통해 영업 이익 및 서비스 이용 고객 파악
데이터 확인
데이터 및 소스 코드 : GitHub
데이터 상세
-
InvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country 송장번호 재고코드 상세설명 수량 송장날짜 개당가격 고객ID 나라
데이터 EDA & 전처리
기본 데이터 확인
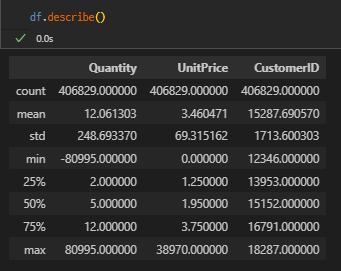
특징은 적고 데이터 샘플은 많다.
df.shape
>
(541909, 8)데이터의 형태는 아래와 같고 CustomerID별로 중복 구매가 일어난다.

데이터 특징별로 좀 더 상세하게 살펴본다.
unique값의 수는 많으나 연속형 데이터로 볼 수 있는 데이터라기엔 애매한 구석이 있다.
for col in df.columns:
print(f'{col} unique len : {len(df[col].unique())}')
print(f'unique of {col} : {df[col].unique()}')
print('-'*50)결측치 처리
결측치가 있다.
df.isnull().sum()
>
InvoiceNo 0
StockCode 0
Description 1454
Quantity 0
InvoiceDate 0
UnitPrice 0
CustomerID 135080
Country 0
dtype: int64결측치가 핵심 특징인 CustomerID에 결측이 있다. CustomerID의 경우 대체할 수 있는 대표값을 선정할 수 없기에 분석함에 있어 방해요소로 작용할 소지가 있기에 CustomerID 결측값은 삭제하도록 한다.
df.dropna(subset=['CustomerID'], how='all', inplace=True)
df.shape
>
(541909, 8) -> (406829, 8)이상치 처리
Quantity에 마이너스 데이터가 존재한다. 반품인지 아니면 다른 사유로 인한 것인지 알 수 없는 데이터다.
그리고 IQR 75% 구간이나 평균 값에 비해 최대값이 매우 크다. 분류나 예측을 해결해야하는 문제가 아니기에, 이상치라기 보다는 우량 고객으로 잠재적으로 분류하고 추후 RFM 지표에서 좀 더 살펴보기로 한다.
Quantity에 마이너스 데이터에 대한 정보가 없으므로 이상치로 간주하고 삭제하도록 한다.
# 0보다 큰 데이터만 다시 할당한다.
df = df[df['Quantity'] > 0]분포를 distplot 그래프로 확인해보자.
plt.figure(figsize=(12, 8))
sns.distplot(df['Quantity'])
plt.show()대부분의 데이터는 0에 가깝게 몰려있다.

0에 몰려있는 데이터를 좀 더 구체적으로 인당 구매 건수를 확인해보자.
# 인당 평균 구매 건수는 약 92건
df.groupby('CustomerID')['Country'].count().mean()
>
91.70868863793501
# 인당 구매 건수는 최소 1에서 최대 7847건
df.groupby('CustomerID')['Country'].count().min(), df.groupby('CustomerID')['Country'].count().max()
>
(1, 7847)그 밖에 특징들을 살펴보자.
# 이용 고객수(4,338명), 이용품목건수(510만건), 이용 나라(37개국)
df['CustomerID'].nunique(), df['Quantity'].sum(), df['Country'].nunique()
>
(4339, 5181696, 37)RFM 지표 정리
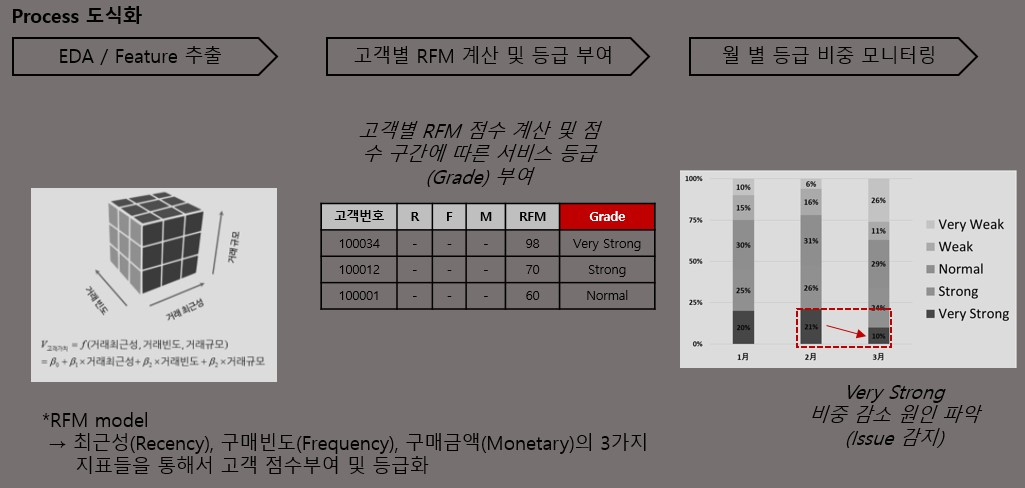
최근성(Recency), 구매빈도(Frequency), 구매금액(Monetary) 3가지의 지표들을 통해서 고객 점수 부여 및 등급화를 진행한다.
3가지의 데이터를 스캐일링을 진행 한 후에 더하여 RFM 지표 점수를 매겨서 등급을 부여한다. 그래서 고객의 등급이 어떻게 변화하는지 모니터링을 하고 원인 파악을 할 때 사용을 할 수 있다.
하지만 등급을 나눌 때의 기준 선정에 있어 정해전 명확한 기준이 없기에, 등급을 부여할 때 적절하게 숙고하여 지정이 되어야 한다.
최근성(Recency)
CustomerID별로 가장 최근에 구매한 날짜를 기준으로 최근성을 선정한다. 데이터는 2010-1년의 자료로 다소 시간이 지난 시점이기에 데이터를 기준으로 가장 마지막 날을 현재로 가정하고 진행을 한다.
df['Date'].min(), df['Date'].max()
>
(Timestamp('2010-12-01 00:00:00'), Timestamp('2011-12-09 00:00:00'))먼저 datatime 형식으로 날짜를 수정하고, 전체 날짜에서 가장 마지막 날을 현재로 지정하고 현재 시점에서 CustomerID별 최근 날짜(day 기준)를 빼서 '일'로 계산한다.
# 계산을 위해 날짜를 datetime으로 변형
df['Date'] = pd.to_datetime(df['InvoiceDate'].str.split(' ').str[0])
# 고객 ID별 최근 구매일
recency_df = df.groupby('CustomerID', as_index=False)['Date'].max()
recency_df.columns = ['CustomerID', 'LastPurchaseDate']
# 고객 ID별 최근 구매일로부터 지난 날짜 : day
recency_df['recency'] = recency_df['LastPurchaseDate'].apply(lambda x: (df['Date'].max() - x).days) 
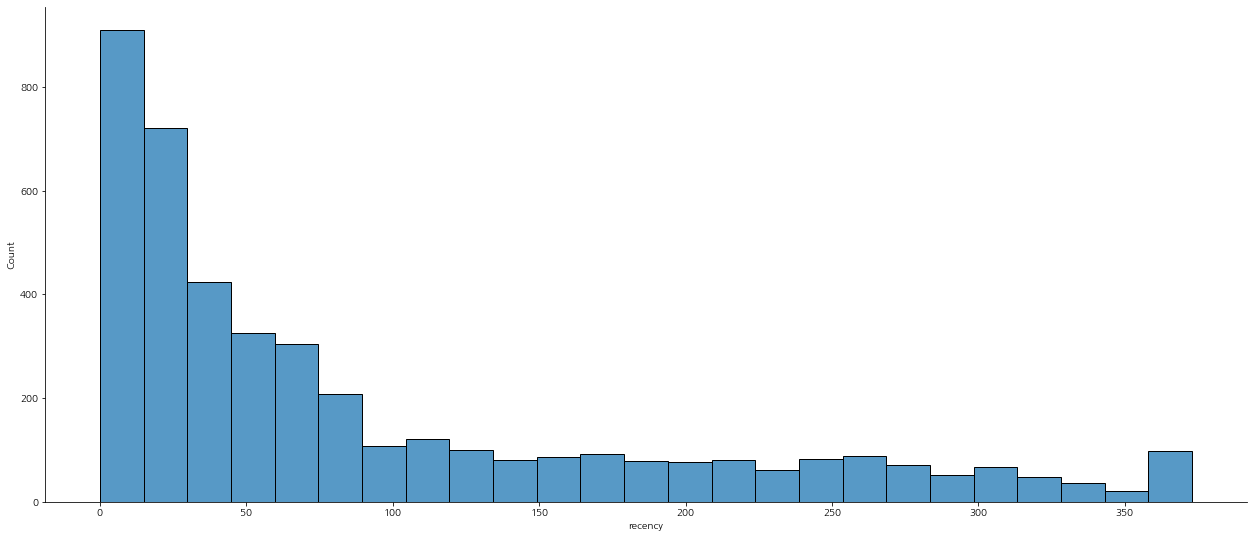
그래프로 고객별 최근에 구매한 날짜를 기준으로 확인해보면, 아래와 같이 최근 구매한 구매 고객 비율이 높은 것을 확인할 수 있다.
구매빈도(Frequency)
한 고객의 구매 빈도를 계산할 때, 아래와 같이 'InvoiceNo'가 같은 것으로 한 번에 여러 건의 물품을 구매한 것은 한 번의 구매로 계산한다.
그래서 CustomerID별 unique한 InvoiceNo를 하나의 구매 건수로 보고 진행한다.
# 중복 구매는 삭제
frequency_df = df.drop_duplicates(subset=['CustomerID', 'InvoiceNo'], keep='first')
# CustomerID당 구매 건수
frequency_df = frequency_df.groupby('CustomerID', as_index=False)['InvoiceNo'].count()
frequency_df.columns = ['CustomerID', 'frequency']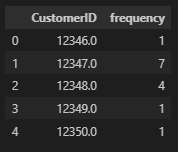
구매금액(Monetary)
CustomerID별 모든 구매 금액 합산을 한다.
# 구매 금액 계산
df['total_cost'] = df['UnitPrice'] * df['Quantity']
# CustomerID별 총 구매 금액
monetary_df = df.groupby('CustomerID', as_index=False)['total_cost'].sum()
monetary_df.columns = ['CustomerID', 'monetary']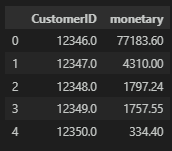
RFM 데이터 합치기
앞서 계산한 최근성(Recency), 구매빈도(Frequency), 구매금액(Monetary) 3가지의 지표를 merge한다.
rfm = pd.merge(recency_df, frequency_df, on='CustomerID')
rfm = pd.merge(rfm, monetary_df, on='CustomerID')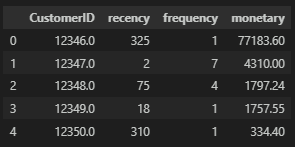
RFM 지표를 통한 서비스 이용 수준 측정
Min Max scaling
3가지 지표의 수치가 맞지 않고 특히 금액의 경우 차이가 심하기에 scaling을 통해서 정규화(0과 1사이의 값)를 진행해야 한다.
# recency는 숫자가 작을수록 최근 구매일이기에 점수가 더 높아야 한다. 그래서 스캐일링 후 역수를 취해야 한다.
rfm['recency'] = minmax_scale(rfm['recency'], axis=0, copy=True)
rfm['recency'] = 1 - rfm['recency']
# frequency, monetary scaling
rfm['frequency'] = minmax_scale(rfm['frequency'], axis=0, copy=True)
rfm['monetary'] = minmax_scale(rfm['monetary'], axis=0, copy=True)
# score 산출
rfm['score'] = rfm['recency'] + rfm['frequency'] + rfm['monetary']
# score scaling : 점수 등급 100이 최대값
rfm['score'] = minmax_scale(rfm['score'], axis=0, copy=True) * 100
rfm['score'] = round(rfm['score'], 0)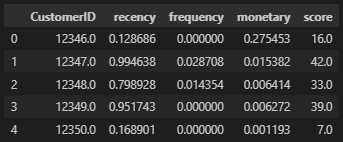
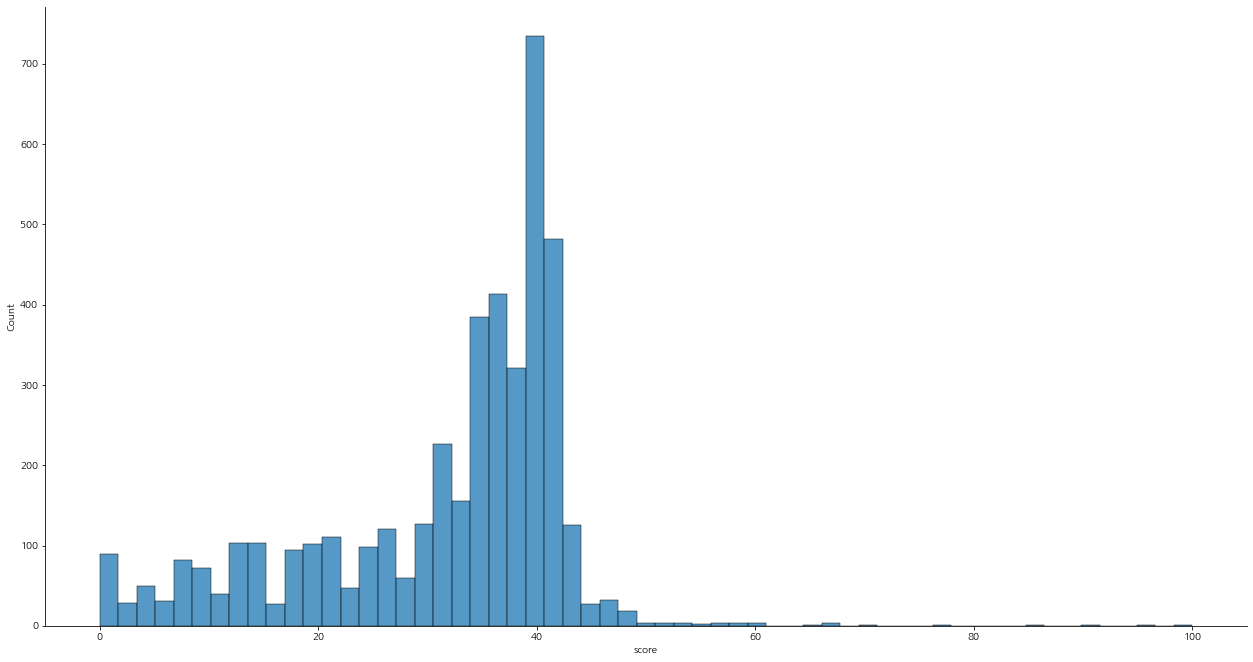
score의 분포를 살펴보면 아래와 같다.
Grade 지정
score를 기준으로 등급을 다음과 같이 지정한다.
- 60 이상 : very strong
- 40 ~ 60 : strong
- 20 ~ 40 : normal
- 20 ~ 10 : week
- 10 이하 : very week
# 등급 함수
def get_grade(x):
if x >= 60:
x = 'very strong'
elif 40 <= x < 60:
x = 'strong'
elif 20 <= x < 40:
x = 'normal'
elif 10 <= x < 20:
x = 'week'
elif x < 10:
x = 'very week'
return x
# 함수 사용
rfm['grade'] = rfm['score'].apply(get_grade)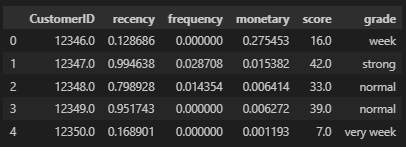
지표 기획
기존의 데이터에 RFM 데이터를 merge하고 지표 기획을 살펴보자.
# merge
df = pd.merge(df, rfm, how='left', on='CustomerID')
# 월별 지표 확인을 위해 년-월 컬럼 생성
df['Month'] = df['Date'].dt.strftime('%Y-%m')월별 이용 고객 현황
월별로 구매 고객의 이용 현황을 살펴보자.
customer_df = df.groupby('Month', as_index=False)['CustomerID'].nunique()
plt.figure(figsize=(25, 8))
plt.plot(customer_df['Month'], customer_df['CustomerID'], label='Customer')
plt.legend()
plt.show()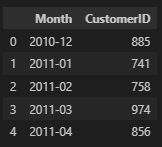
그래프로 고객의 추이를 살펴보면 아래와 같은데, 계속 우상향 그래프를 그리다가 12월에 급감하는 현상을 볼 수 있다.
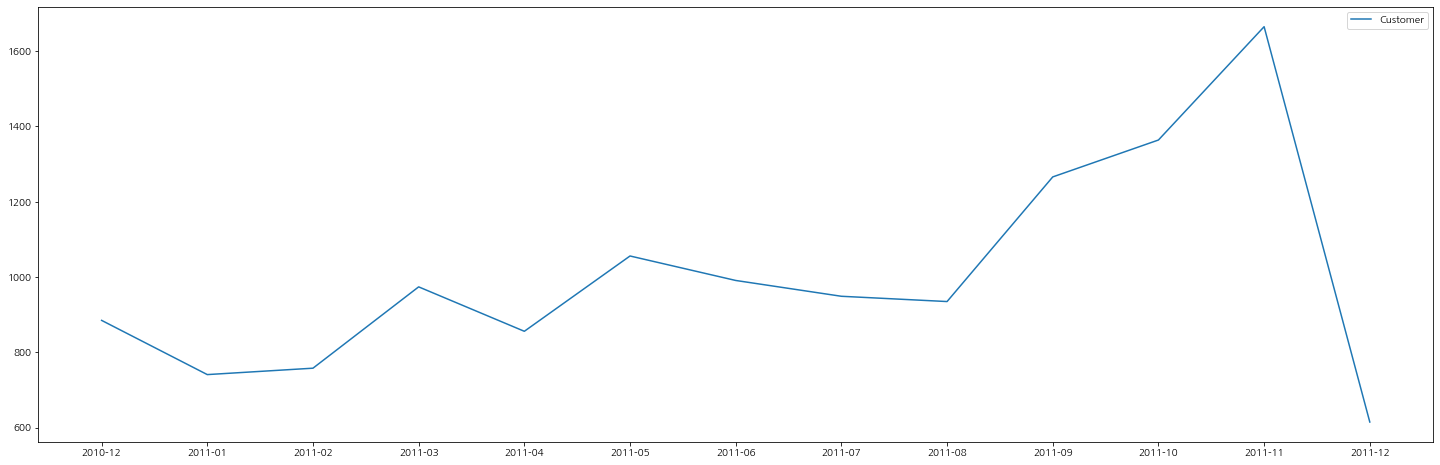
데이터를 자세히 살펴보면 12월의 데이터는 31일이 아닌 9일간의 데이터임을 알 수 있다. 그래서 12월 이용자 수에 3을 곱하여 예측해보면 전처적인 이용 고객수는 우상향을 그린다고 판단이 된다.
df['Date'].max()
>
Timestamp('2011-12-09 00:00:00')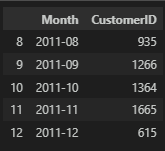
월별 이용 구매 건수
11년 12월 데이터는 1/3의 데이터이기에 경향을 살펴볼 때 무시하고, 구매 건수도 우상향으로 점차 늘어나는 경향이 있음을 확인할 수 있다.
count_df = df.groupby('Month', as_index=False)['InvoiceNo'].nunique()
plt.figure(figsize=(25, 8))
plt.plot(count_df['Month'], count_df['InvoiceNo'], label='count')
plt.legend()
plt.show()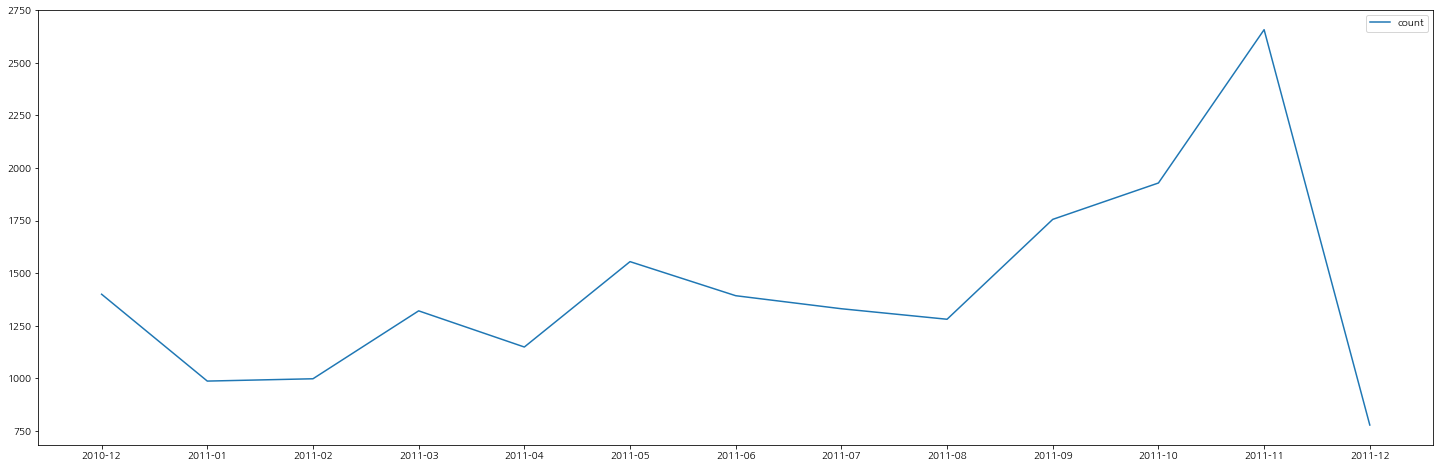
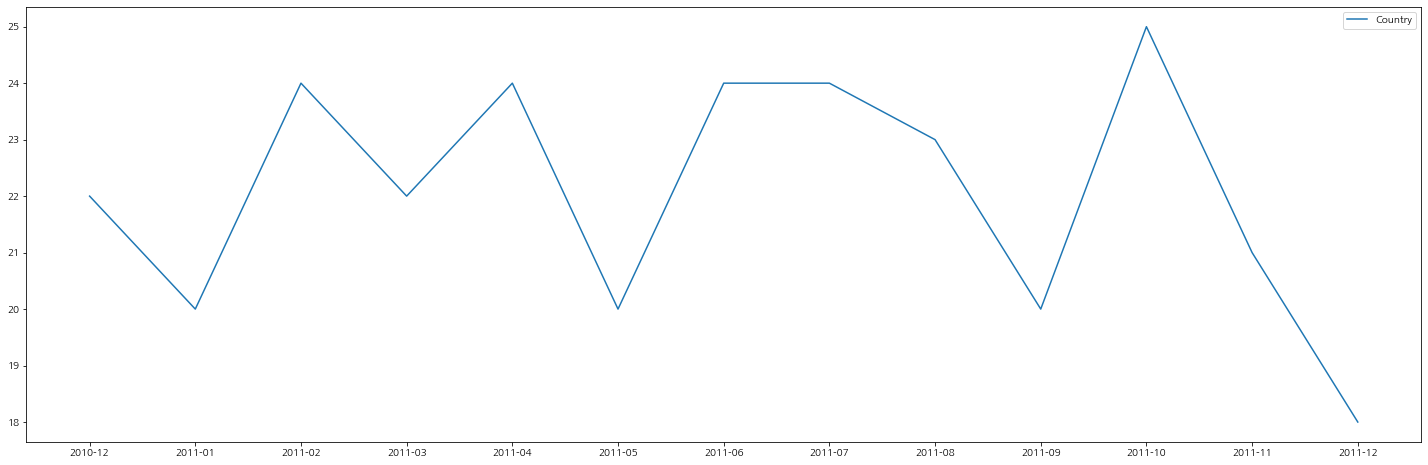
월별 이용 국가
이용 국가의 구매 건수 현황이다. 영국이 가장 충성도가 높은 것으로 보아서 영국을 타겟으로 마케팅을 좀 더 중점적으로 배치할 수 있을 것 같다.
# United Kingdom가 압도적으로 높다. 이커머스 본사가 영국일 가능성이?
df.groupby('Country', as_index=False)['InvoiceNo'].nunique().sort_values(by='InvoiceNo', ascending=False)
plt.figure(figsize=(25, 8))
plt.plot(country_df['Month'], country_df['Country'], label='Country')
plt.legend()
plt.show()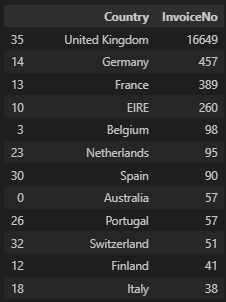
그리고 1, 5, 9월에 이용자수가 떨어진 것의 이유를 살펴볼 이유가 있어 보인다.
월별 Grade 이용 비중
월별로 Grade 현황 데이터를 pivot_table로 정리를 하고 그래프로 확인해보자.
Grade의 비중이 어떻게 변화하는지 살펴볼 수 있다.
# pivot_table을 사용하여 '월'별 등급 현황 정리
pivot_df = pd.pivot_table(grade_df, index='Month', columns='grade', values='CustomerID')
pivot_df.fillna(0, inplace=True)
pivot_df['total'] = pivot_df['normal'] + pivot_df['strong'] + pivot_df['very strong'] + pivot_df['very week'] + pivot_df['week']
# 표준화를 위해 총 합에서 각 등급을 나눠준다.
pivot_df.iloc[:, 0] = pivot_df.iloc[:, 0] / pivot_df.iloc[:, -1]
pivot_df.iloc[:, 1] = pivot_df.iloc[:, 1] / pivot_df.iloc[:, -1]
pivot_df.iloc[:, 2] = pivot_df.iloc[:, 2] / pivot_df.iloc[:, -1]
pivot_df.iloc[:, 3] = pivot_df.iloc[:, 3] / pivot_df.iloc[:, -1]
pivot_df.iloc[:, 4] = pivot_df.iloc[:, 4] / pivot_df.iloc[:, -1]
pivot_df_1 = pivot_df.drop('total', axis=1)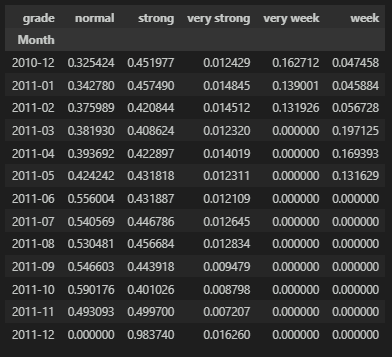
이를 그래프로 그려보자.
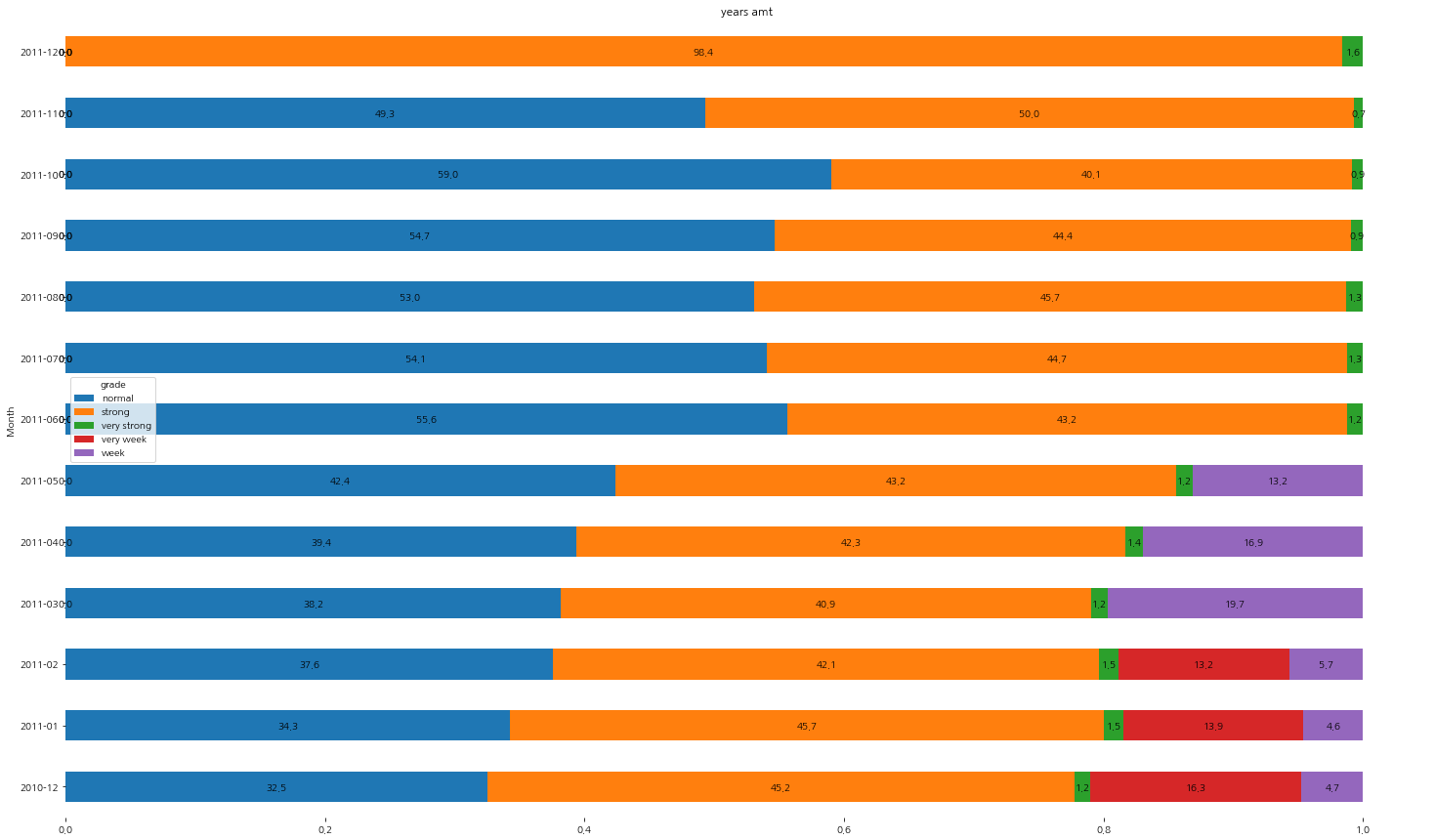
ax = pivot_df_1.plot(kind='barh', stacked=True, title='years amt', rot=0)
for p in ax.patches:
left, bottom, width, height = p.get_bbox().bounds
ax.annotate('%.1f'%(width*100), xy=(left+width/2, bottom+height/2), ha='center', va='center', color='black')
plt.box(False)
plt.gcf().set_size_inches(25, 20)
plt.show()파란색의 normal 등급은 늘어나는 추세이고, 충성도가 높다고 판단되는 주황색 strong 등급은 줄어들지도 늘어나지도 않고 있다. 그리고 녹색의 충성도가 가장 높은 very strong 등급의 비율은 고정되어 있어 이 비율을 늘릴 필요가 있어 보인다. 또한 가장 충성도가 낮은 고객은 초반 3개월에 나타나는데 이는 더 이상 해당 이커머스에 흥미가 없어져 나갔거나 충성도가 오르게 되어 없어졌을 수도 있기에 좀 더 면밀하게 살펴봐야 할 필요성이 있어 보인다. 마찬가지로 충성도가 낮은 보라색 등급도 초반 6개월 후 보이지 않게된 원인이 무엇인지 파악해야 할 필요성이 있다.
기대 효과
영업 이익 증감 원인 파악 및 대응책을 수립하여 영업 이익 증대와 서비스 이용 고객 증대를 기대한다.
개발된 지표를 통해 모니터링 및 이슈 파악
