
문제 정의

자영업 사장님이 되었을 때, 매장 최적의 위치를 찾기 위해 시작하였으나, 지도학습을 위한 '라벨'에 해당하는 '매출'등과 같은 데이터는 외부에서 구할 수 없었다.
그래서 비지도 학습으로 인허가 시설들 및 생활인구수를 바탕으로 밀도를 '군집화'하여 군집별 특성을 찾아낸 후, 그 특성을 바탕으로 위치를 선정할 때 도움이 되는 정보를 얻는 방향으로 프로젝트 진행.
1. 데이터 소개
아래의 데이터들은 전처리를 끝낸 데이터로써, 데이터를 만들기까지의 일명 '노가다' 작업이 많기에 전처리 과정은 생략하고 설명만 하겠다.
1-1. 인허가 시설 데이터
출처 : 인허가 시설
종류 : 36개의 그룹, 196개 업종에 대한 데이터(지역별 : 서울시)
해당 데이터는 여러 정보를 담은 컬럼이 존재하여 EDA 및 전처리를 진행하였으나, 유의미한 결과를 얻지 못해 주소, 위도/경도만 사용.
- googlemaps사용하여 주소로 위도/경도 얻기
import googlemaps
gmaps_key = "나의 구글 맵 API 키 입력" # https://cloud.google.com/maps-platform/ 에서 얻기
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode(주소, language="ko") # 8가지의 버전으로 반환해준다.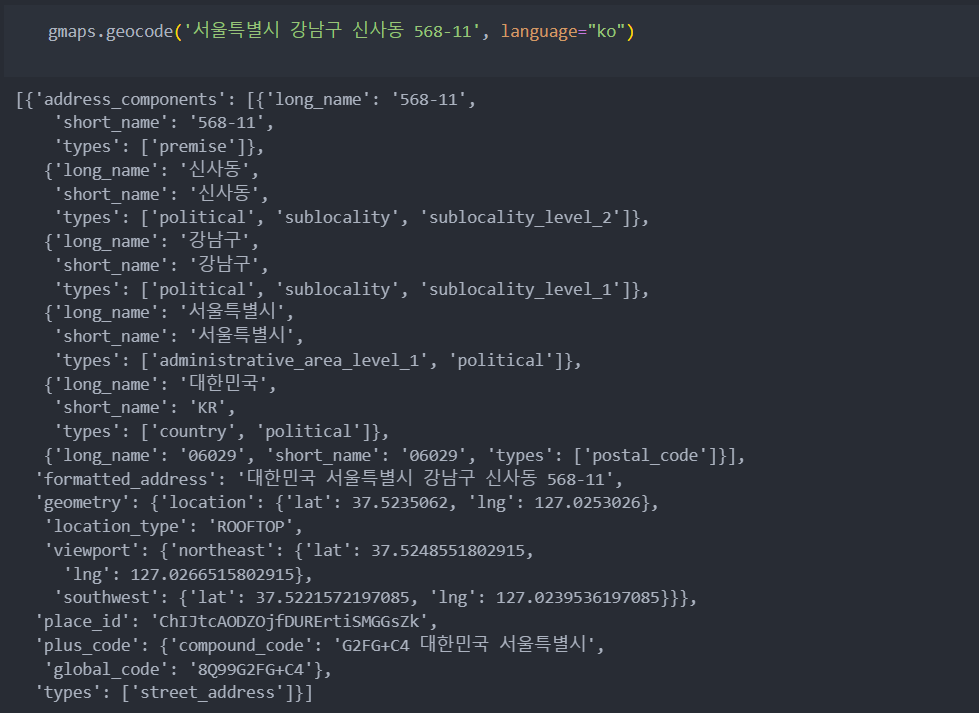
-
데이터는 총 196개의 csv 파일 제공하며 모든 데이터를 합치면 아래와 같이 174만row, 420columns를 가진다.
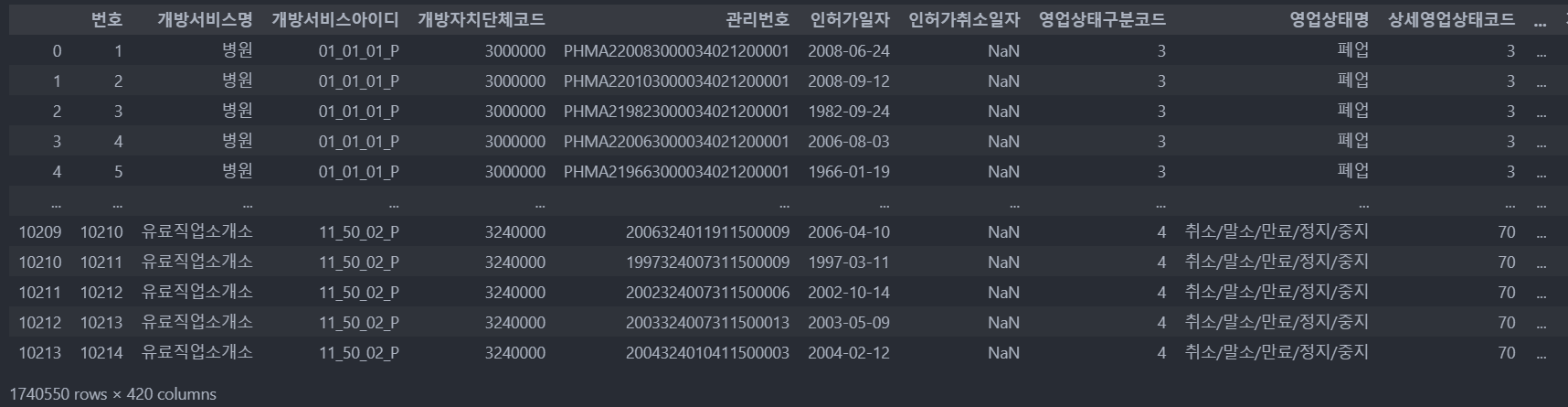
-
데이터 전처리 : 강남구의 각 시설들의 위치 추출.
-해당 데이터 주소 : 2가지(둘 다 다른 형태이거나 둘 중 하나가 없거나)
-필요 데이터 : 강남구 내 시설들의 위도와 경도(위도/경도가 없는 데이터도 존재 -> googlemaps사용하여 주소로 위도/경도 얻기)
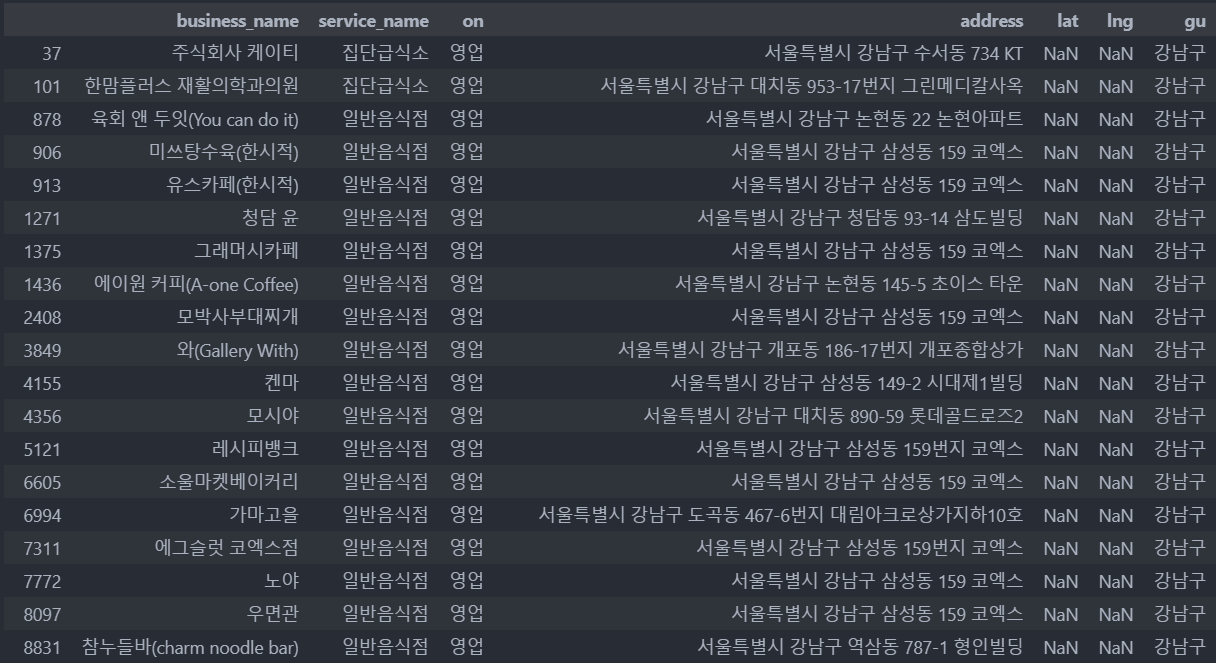
-목적 : 좌표를 중심으로 300m, 500m, 1000m 등의 반경 안 시설의 수를 확인하기 위해
-
필요하다고 선정한 인허가 시설들을 5개의 그룹으로 묶어서 사용하였다.
데이터를 추가로 설명하면, 음식점 데이터에는 2가지 외에도 집단급식소, 휴게음식점도 포함되어 있었으나 집단급식소는 병원을 포함하고 휴게음식점은 편의점과 중복이 있어 제외시켰다. 아래 데이터들은 기본 전처리를 끝낸 데이터.
-음식점(ARR_FOOD.csv) : 관광식당, 일반음식점
-의료시설(ARR_HOSPITAL.csv) : 병원, 의원, 부속의료기관, 약국, 의료법인, 동물병원, 동물약국
-체육시설(ARR_SPORTS.csv) : 골프연습장업, 골프장, 당구장업, 무도장업, 무도학원업, 수영장업, 종합체육시설업, 체육도장업, 체력 단련장업
-숙박시설(ARR_TOURISM.csv) : 관광숙밥업, 숙밥업, 외국인 관광도시 민박업
-문화시설(ARR_CULTURE.csv) : 공연장, 관광 공연장업, 영상상영관

1-2. 편의점 데이터
- 편의점 데이터 출처 : gs25, cu, 7eleven, mini stop, emart24 5개의 브렌드 사이트 크롤링
- 전처리 : 위도/경도가 없는 경우, googlemaps사용하여 주소로 위도/경도 얻기.
- convenience store.csv : 5개의 브렌드를 합친 후 기본 전처리를 진행한 데이터.
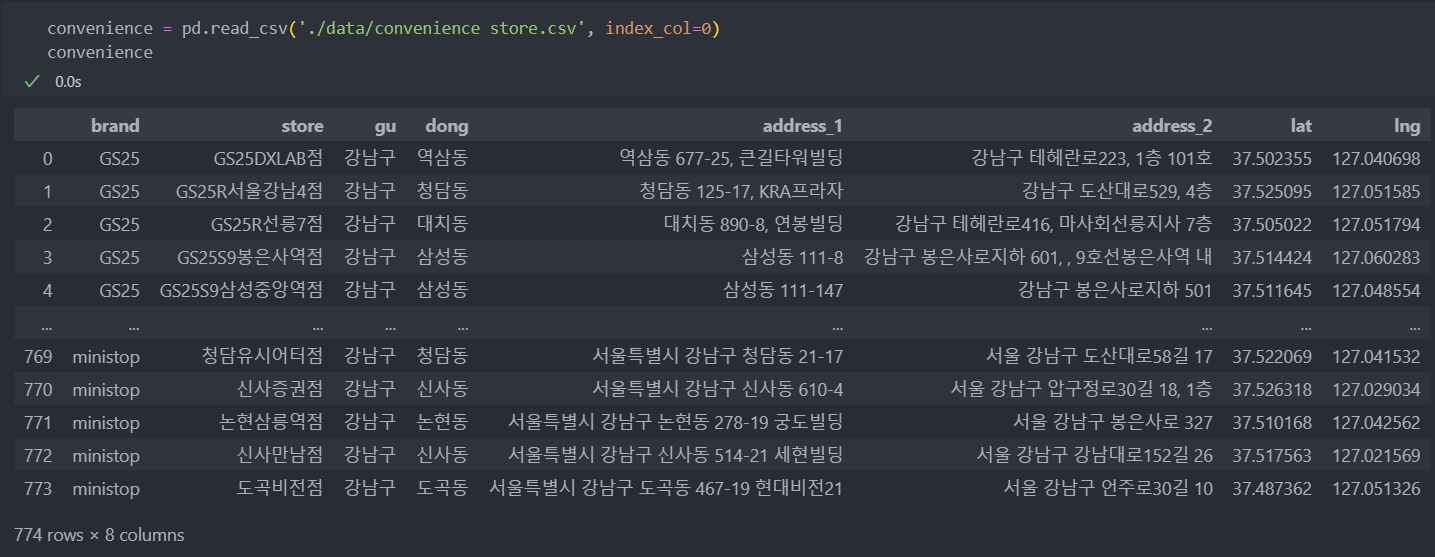
1-3. 공공 데이터
- 강남구지하철.csv : 강남구 지하철역 데이터
- poplutation.csv : '동'별 2023년 6월 생활인구수 전처리 데이터(동별 인구수 + 동별 시설 개수 추가)
- restroom_data.csv : 강남구 화장실 위도/경도
1-4. 서울시 자치구 경계 데이터
- 서울자치구경계_2017.geojson : 지도 시각화 folium의 사용과 강남구의 폴리곤 바운더리 생성을 위해.
1-5. 기타
- random_population_density_500.csv : 강남구 내 랜덤 위도/경도 850개 위치를 '동'별 시설 및 인구대비 시설 밀도 전처리 데이터
2. '동'별 밀도 분석
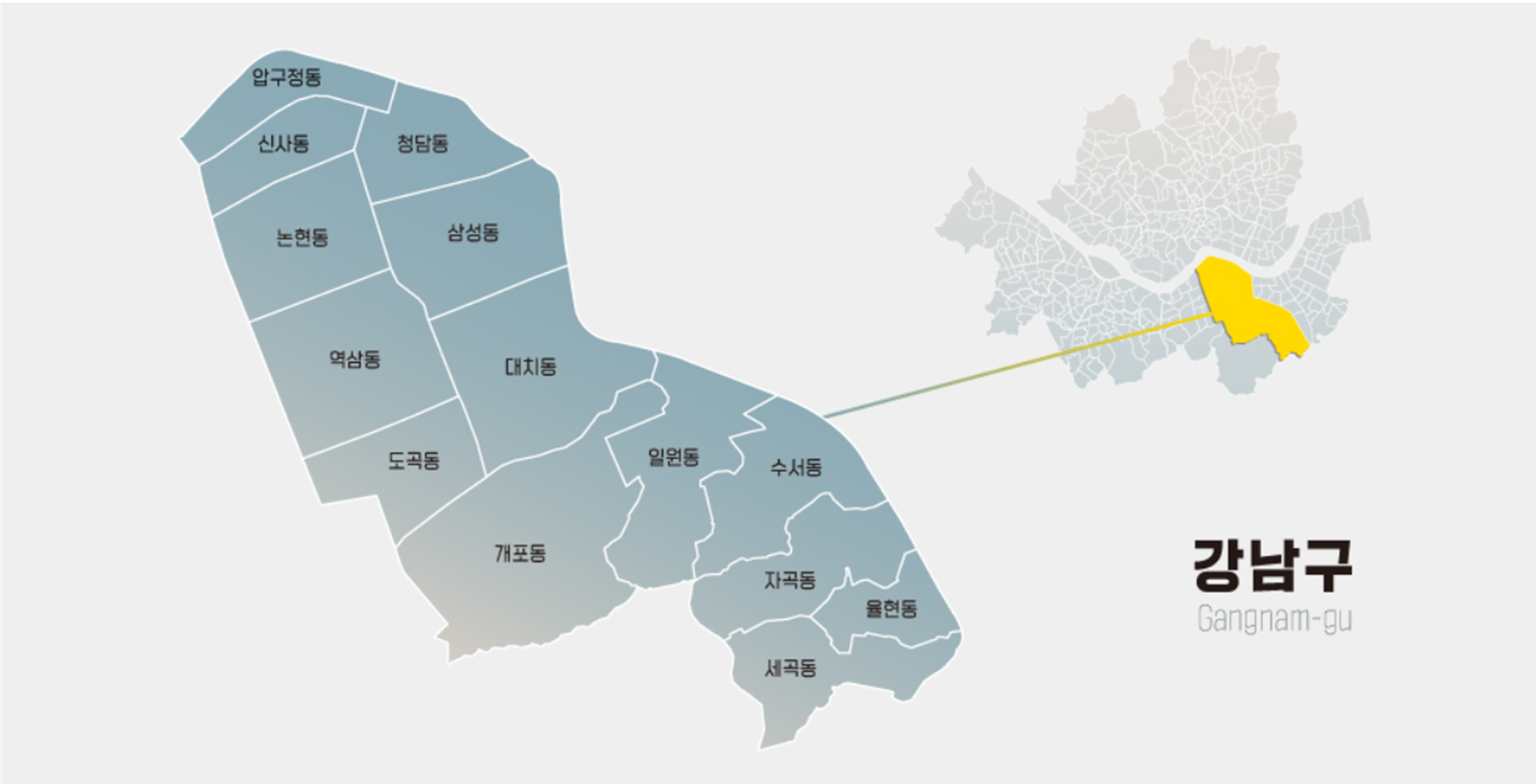
데이터들을 묶어 비교 및 분석에 필요한 '법정동' 기준 '동' 컬럼을 통일시킬 필요성이 있어 아래의 12개 동으로 전처리를 진행하였다.
강남구의 법정동 : 14개
주소 또는 위도/경도로 얻은 데이터로 googlemaps를 사용하여 '동'을 추출하려면 일명 '노가다'가 필요하다.
googlemaps는 8가지의 버전으로 주소를 반환하여 주지만, 어느 버전도 '지번' 기준 통일성 있게 '동'을 반환하여 주지 않는다.
'동'을 반환해 주는 주소나 위도/경도가 있고 아닌 경우도 있어서, '동'을 반환해 주지 않는다면 하나하나 확인하는 '노가다'가 필요하다.
그리고 법정동 또한 논현1동, 논현2동 등 제각각이어서 1동, 2동 등을 법정동 기준으로 묶어주어야 한다.
그나마 건물에 등록된 '위도/경도'라면 노가다를 쉽게 할 수 있도록 반환하지만,
추후 볼 강남구 내 렘덤한 위치들의 '동'주소를 가져오게 되면 더욱 복잡하게 반환한다.
인허가 시설 및 편의점, 지하철, 공중화장실 등 데이터들을 가져와서 '동'별 특성이나 시각화를 할 때는 14개의 동을 12개로 줄여 사용했다.
자곡동, 세곡동, 율현동은 주거 지역이 많아 같은 특성을 띄고 있기에 '행정동' 기준인 세곡동으로 통일하였다.(14개 -> 12개)

시설 데이터들을 '동'을 기준으로 groupby하여 시설들의 개수 데이터와 '동'을 기준으로 인구수의 데이터를 합한 데이터는 다음과 같다.
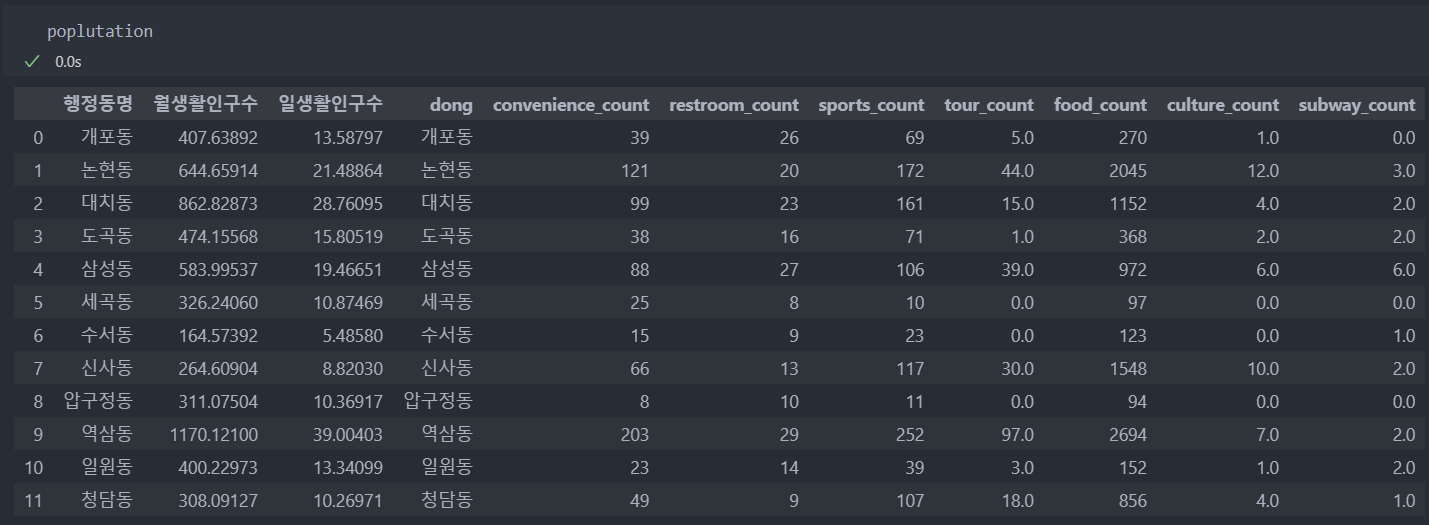
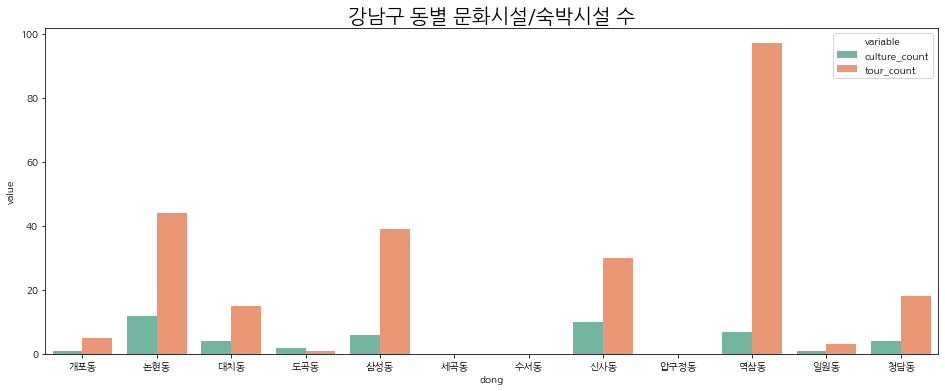
동별로 시설들의 개수를 그래프로 확인해보자.
# 시설 개수가 5개라 한 눈에 들어오지 않아 나누어 보자.
bar_1 = poplutation.melt('dong', 'food_count')
bar_2 = poplutation.melt('dong', ['convenience_count', 'restroom_count', 'sports_count', 'tour_count'])
bar_3 = poplutation.melt('dong', ['culture_count', 'subway_count'])
# 음식점
plt.figure(figsize=(16, 6))
sns.barplot(data=bar_1, x='dong', y='value', hue='variable', palette='Set2', lw=2)
plt.title('강남구 동별 음식점 수', fontsize=20)
plt.show()
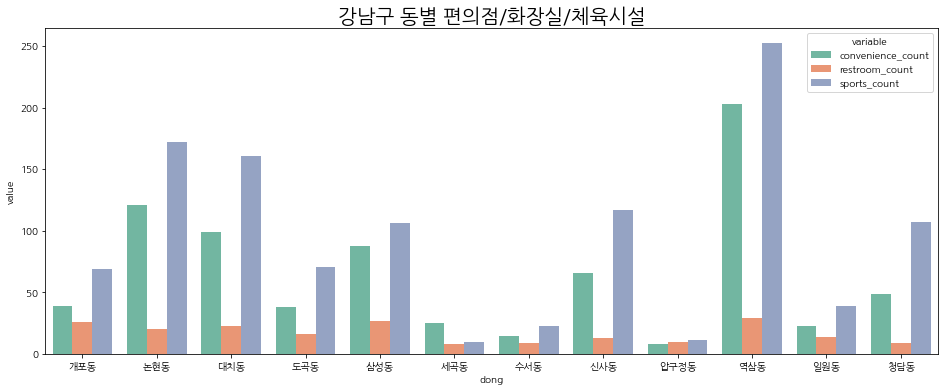
# 편의점/화장실/체육시설
plt.figure(figsize=(16, 6))
sns.barplot(data=bar_2, x='dong', y='value', hue='variable', palette='Set2', lw=2)
plt.title('강남구 동별 편의점/화장실/체육시설/숙박시설 수', fontsize=20)
plt.show()
# 문화시설/숙박시설
plt.figure(figsize=(16, 6))
sns.barplot(data=bar_3, x='dong', y='value', hue='variable', palette='Set2', lw=2)
plt.title('강남구 동별 문화시설/지하철 수', fontsize=20)
plt.show()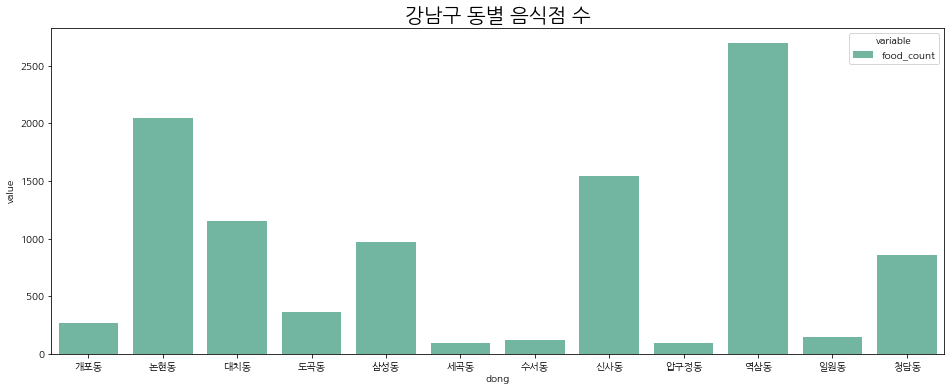
아래는 '동'별 인구수 그래프다.
# '동'별 월 생활 인구수
plt.figure(figsize=(16, 6))
sns.barplot(data=poplutation, x='dong', y='월생활인구수', palette='Set2', lw=2)
plt.title('"동"별 월 생활 인구수', fontsize=20)
plt.show()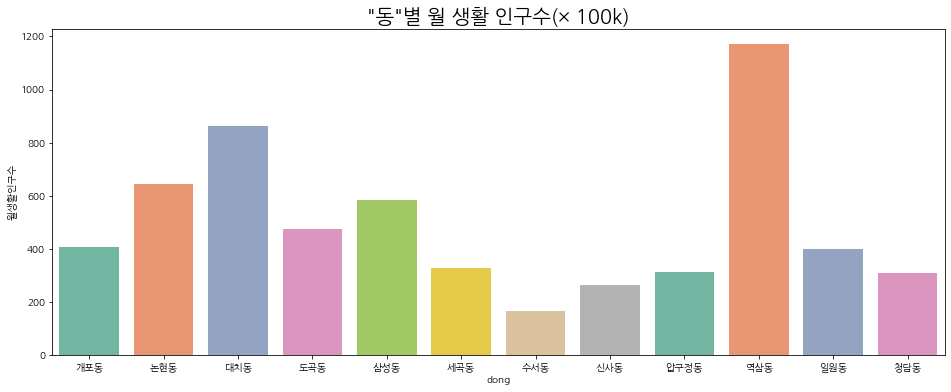
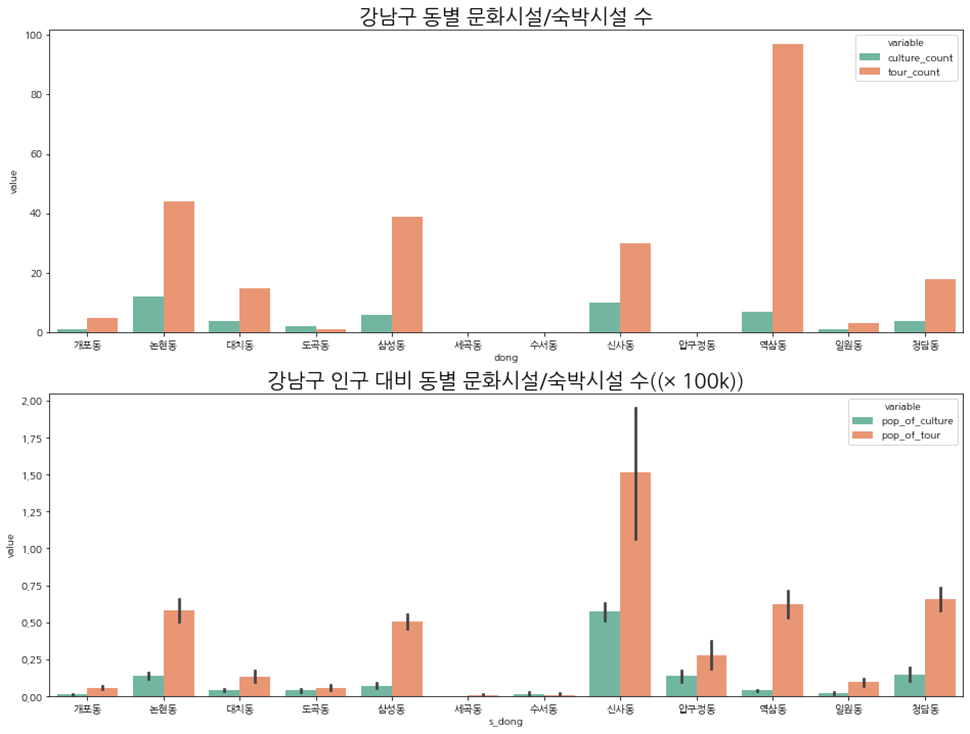
이제 시설수만 놓고 보았을 때와 인구(10만명 당) 대비 시설수도 같을지 확인해보자.
시설수에 인구수(10만명 당)를 나누어 비교해 보았다.
10만명당 나눈 데이터는 연속형 데이터라서 분포를 같이 보도록 하자.
인구 대비로 보았을 때 신사동, 압구정동, 역삼동의 비율이 달라지는 것을 볼 수 있다.
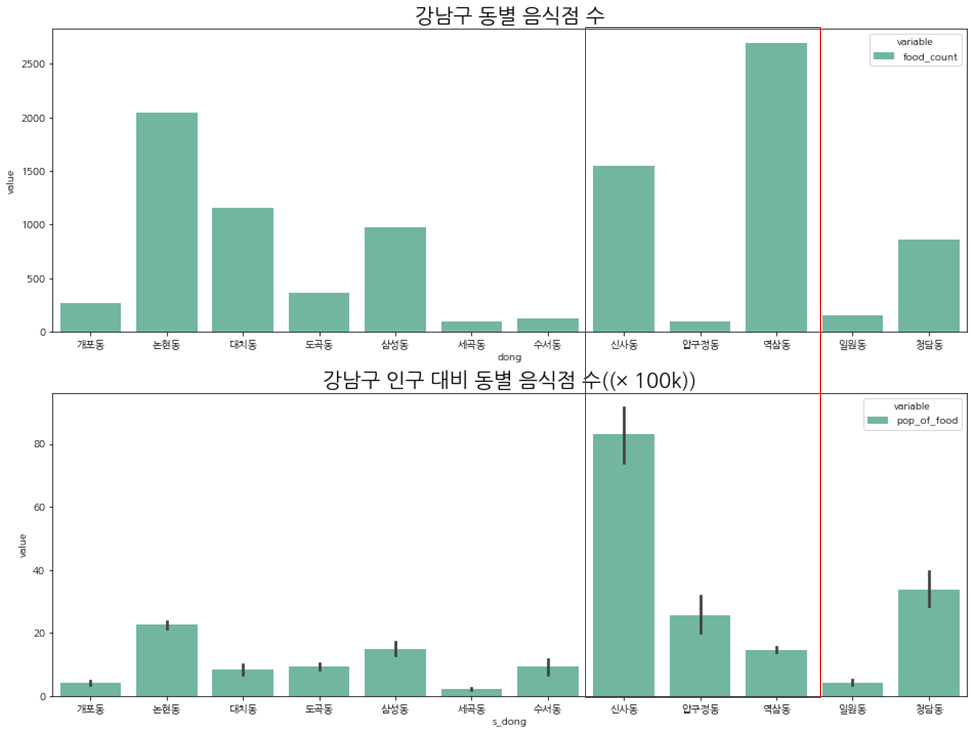
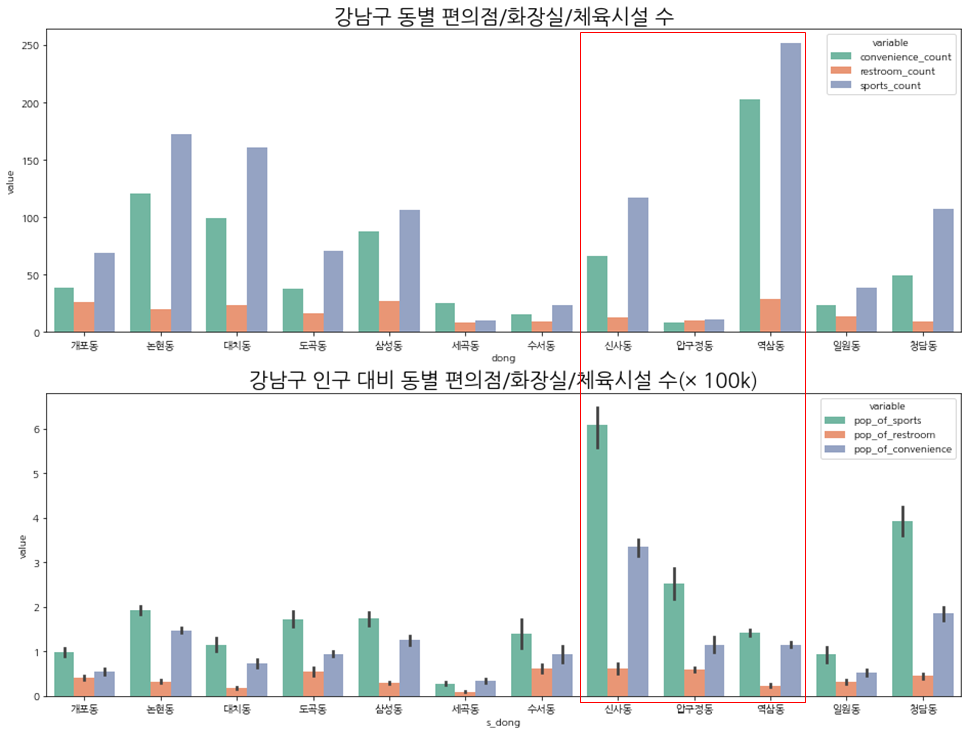
3. 모델링
먼저 강남구 폴리곤 바운더리를 생성하고 그 바운더리 안에 랜덤 좌표를 생성한다.
그리고 생성한 위도/경도(좌표) 기준 반경 500미터 내 시설별 개수를 추출 및 전처리를 진행한다.
라벨 데이터가 없어 KMeans를 사용하여 좌표들의 특성을 구별하였다.
랜덤 좌표 생성
from shapely.geometry.polygon import Polygon
Polygon을 사용하여 폴리곤 바운더리를 생성한다.
폴리곤 바운더리는 강남구 내 시설물이 들어서지 못하는 산과 강은 제외하고 생성하였다.
그래서 산과 강 부분에는 좌표가 생성되었어도 제외가 된다.
리스트 안의 튜플로 첫번째는 경도이고 두번째는 위도이다.
polylist = [
(127.0158715456462, 37.52395552514407), \
(127.03404427570877, 37.48455972739361), \
(127.04138283634332, 37.48556651426365), \
(127.04501866584928, 37.47730743834274), \
(127.05109704553787, 37.47143038122402), \
(127.08181938718701, 37.488766534231814), \
(127.0829699570822, 37.486260930171355), \
(127.07976935335684, 37.48555133810168), \
(127.08025449404848, 37.48456891064258), \
(127.07596786895694, 37.48317518162543), \
(127.07585253680503, 37.48093174415405), \
(127.08014959673851, 37.481631694208154), \
(127.08196827786045, 37.48015279205741), \
(127.08589130090392, 37.480023864131155), \
(127.09622503041525, 37.48009699103141), \
(127.09607233059212, 37.484457996448725), \
(127.0968868132337, 37.484772684201445), \
(127.09785785720334, 37.48375374466706), \
(127.10049344132076, 37.48462551028881), \
(127.09964813686373, 37.48665349416874), \
(127.10261025731748, 37.486434716842325), \
(127.10411019888349, 37.48364027975824), \
(127.09961923020603, 37.48191421556131), \
(127.10257722231188, 37.4788122144288), \
(127.10497607049953, 37.48026073177465), \
(127.10492453516474, 37.475746721996316), \
(127.10001850811862, 37.47610237034757), \
(127.09248874886488, 37.47578414076369), \
(127.08669531549697, 37.47135556484104), \
(127.09276829953566, 37.46414286714414), \
(127.09964233625507, 37.46525452474618), \
(127.1012649179668, 37.461432857267), \
(127.09940991577305, 37.460461339593685), \
(127.10162320409935, 37.45890971654731), \
(127.10782171773475, 37.46211182557879), \
(127.11387871956023, 37.461097011051415), \
(127.1234727951866, 37.46660156429503), \
(127.09986054922331, 37.49332977890127), \
(127.06956401375487, 37.50279404849988), \
(127.06595858545498, 37.51822131133216), \
(127.05383896278687, 37.52730956318118), \
(127.02705198082393, 37.53395010704315)]
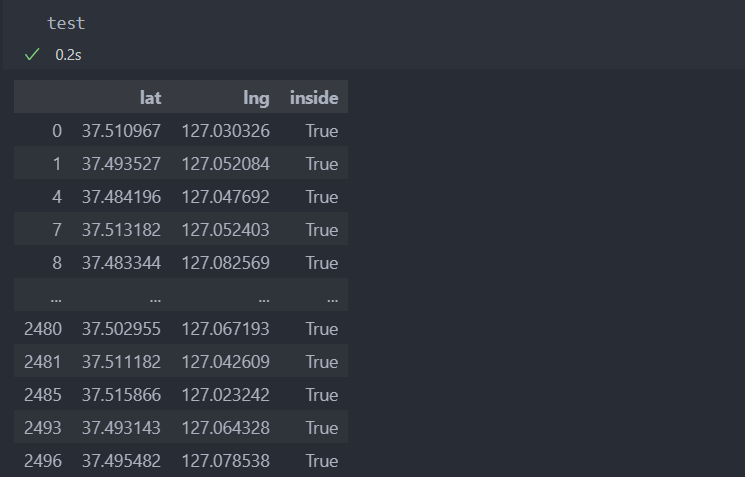
polygon = Polygon(polylist)이 폴리곤 바운더리를 사각 박스를 치고 2500개의 좌표를 생성시킨다.
그리고 폴리곤 바운더리 안에 들어온 좌표만 골라내면 약 1000개의 좌표가 생성이 된다.
# 폴리곤 바운더리 좌표값 담기(최대/최소값 얻기 위해)
lat = []
lng = []
for pol in polylist:
lat.append(pol[1])
lng.append(pol[0])
# 입력하는 최소값과 최대값 사이에 샘플 수 만큼 수치 생성 함수
def generate_random_numbers(min_value, max_value, num_samples):
random_numbers = []
for _ in range(num_samples):
random_numbers.append(random.uniform(min_value, max_value))
return random_numbers
# 최대값과 최소값 사이의 값을 각각 2500개씩 생성
lat_range = generate_random_numbers(37.45901355607214, 37.53719881898076, 2500) # 위도
lng_range = generate_random_numbers(127.0088013935976, 127.12288623841854, 2500) # 경도
test = pd.DataFrame({'lat': lat_range, 'lng':lng_range})
# lambda함수를 사용하여 폴리곤 안에 들어오는 좌표만 사용(True값만 사용)
test['inside'] = test.apply(lambda x: polygon.contains(Point(x['lng'], x['lat'])), axis=1)
test = test[test['inside']==True]폴리곤 바운더리 안의 좌표는 다음과 같다.
이제 생성된 랜덤 좌표를 folium으로 지도 시각화를 하면 다음과 같다.
m = folium.Map(location=[37.4966, 127.0628], zoom_start=13) # location:지도의 중심 위치, zoom_start:지도 크기 단계
m.choropleth(geo_data=geo_str, fill_color='#bdbbbb')
for idx, row in test.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
radius=50
).add_to(m)
m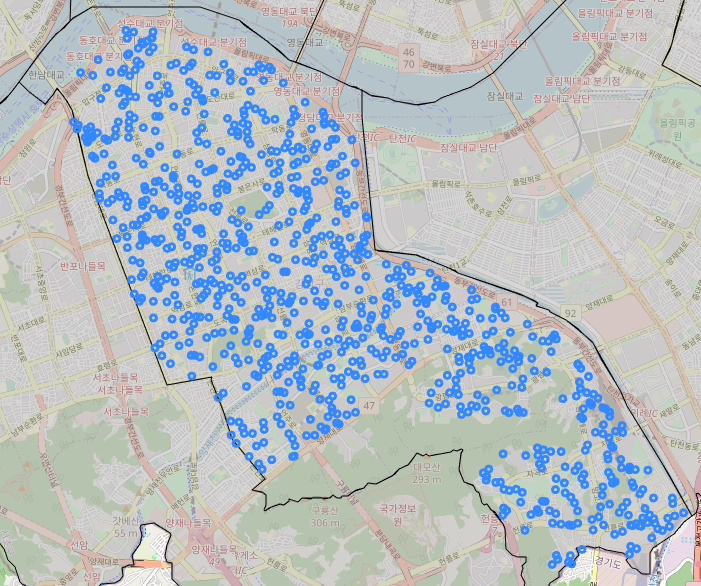
haversine(a, b, unit=)
haversine에 좌표 2곳을 입력하면 두 좌표 사이의 거리를 반환해주는 함수다.
주요 인자:
- 첫번째 a자리 : 현재 좌표
- 두번째 b자리 : 다른 좌표
- unit : 거리 측정 기준('m': 미터)
아래 지도는 강남구 내 음식점들의 위도/경도를 바탕으로 위치를 지도 시각화 한 것이다.
haversine를 이용하여 랜덤 좌표를 중심으로 반경 500미터 안의 음식점 포함 모든 시설별 '수'를 랜덤 좌표 데이터에 추가할 것이다.
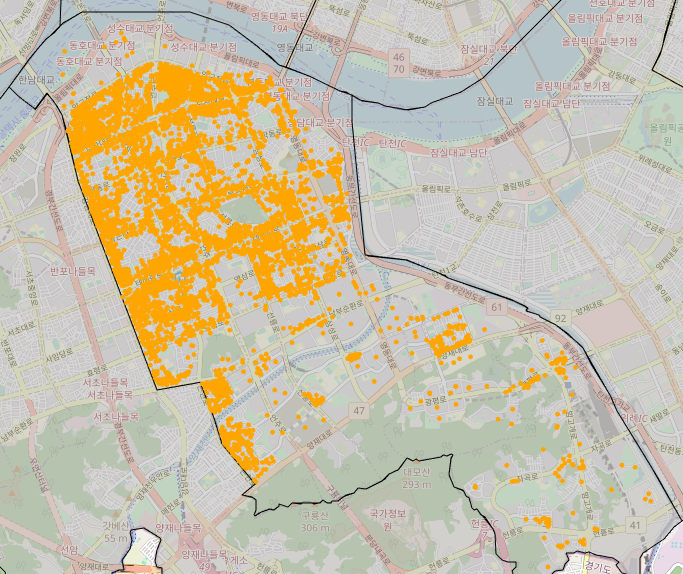
# 시설별 데이터 리스트에 담기 -> 데이터 안의 위도 경도 사용을 위해
lists = [food, convenience, hospital, sports, tour, restroom, culture ]
# 랜덤 좌표를 입력하면 반경500m 주변 시설들의 갯수 구하기
within = []
for index, row in test.iterrows():
within_500m = []
c_lat = row['lat']
c_lng = row['lng']
c = (c_lat, c_lng)
within_500m.append(c_lat)
within_500m.append(c_lng)
for lis in lists:
count = 0
for idx, r in lis.iterrows():
lat = r['lat']
lng = r['lng']
sub = (lat, lng)
if haversine(c, sub, unit='m') < 500:
count += 1
within_500m.append(count)
within.append(within_500m)랜덤 좌표별 모든 시설들의 좌표와 비교하면서 거리가 500보다 작은 거리에 있는 수를 세어서 가져온다.
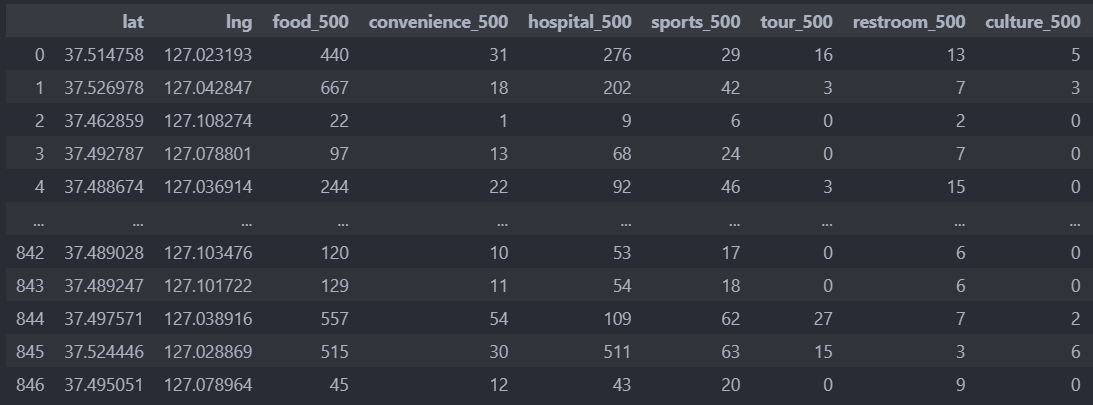
이제부터 데이터는 random_population_density_500.csv를 사용한다.
500미터 내 시설 수 뿐만이 아니라 '동'별로 특성을 파악하려면 googlemaps를 사용하여 랜덤 좌표의 위도/경도에 해당하는 '동'을 추가해야 한다. 그리고 '동'을 기준으로 인구수를 추가시켜, 인구수 대비 시설 밀도도 확인해야 한다.
위도/경도만으로 '동'을 추가하는 작업은 '노가다' 작업이기에 '동'이 전처리 된 데이터를 사용하면 된다.
KMeans
random_population_density_500에는 주소, 위도/경도, 좌표 내 시설물 개수, 동, 인구대비 시설물 수 등의 데이터를 사용하여 군집화를 하여 라벨을 붙여줄 것이다.
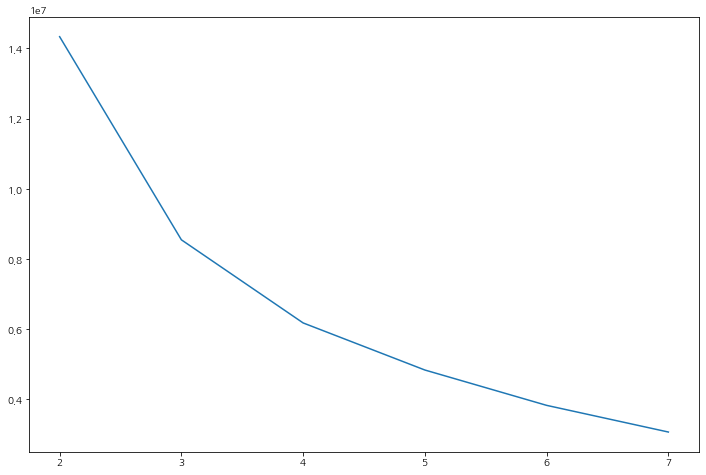
먼저 군집을 몇 개로 해야 할 것인지 확인해보자.
inertia
군집 간 거리 합을 나타내는 'inertia' 지수가 급격히 떨어지는 지점을 보통 적정 군집수로 사용한다.
X = random_population_density_500[['food_500', 'convenience_500', 'hospital_500', 'sports_500', 'tour_500', 'restroom_500', 'culture_500']]
inertia_ls = []
k_range = range(2, 8)
for k in k_range:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
inertia = kmeans.inertia_
print(f'K : {k}, inertia: {inertia}')
inertia_ls.append(inertia)
plt.figure(figsize=(12, 8))
sns.lineplot(x=k_range, y=inertia_ls)
plt.show()군집수가 적을 수록 높은 값을 나타낸다.
하지만 2, 3개를 쓰기에는 특성을 구분하는데 너무 적은 숫자라 판단하여 5개를 사용하기로 한다.
그리고 실루엣 계수 그래프는 다음과 같다.
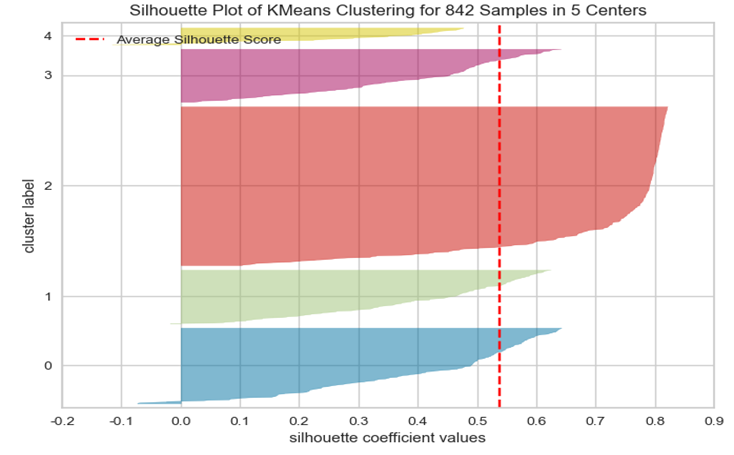
5개로 나뉜 값에 라벨을 추가하자.
라벨은 유의미한 값이 아닌 단순히 군집으로 나뉜 것을 구별하기 위한 것이다.
predict = pd.DataFrame(kmeans.predict(train_X), columns=['cluster'])
df = pd.concat([train_X, predict], axis=1)DecisionTreeClassifier
군집화가 잘 되었다면, 군집화 결과인 라벨을 지도학습의 라벨로 사용하면 점수가 잘 나올 것이라 보고 진행했다.
accuracy_score가 94% 잘 나누어졌다고 판단한다.
# data/label 데이터 나누기
X = df[['food_500', 'convenience_500', 'hospital_500', 'sports_500', 'tour_500', 'restroom_500', 'culture_500']]
y = df['cluster']
# 학습/평가 데이터로 나누기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=29)
# 모델 인스턴스
DC = DecisionTreeClassifier(max_depth=5, random_state=13)
# 학습
DC.fit(X_train, y_train)
# 예측
pred = DC.predict(X_test)
# 평가지수 확인
accuracy_score(y_test, pred)
accuracy_score : 0.9411764705882353
# plot_tree 그래프 그려보기
plt.figure(figsize=(12,8))
plot_tree(DC)
plt.show()
4. 특징 EDA 및 시각화
5개의 밀도 그룹 특징
라벨을 붙인 뒤, 라벨별 특성을 확인해보자.
평균값으로 보자.
# 군집별 '평균' 구하기
df_0 = df[df['cluster']==0]
df_1 = df[df['cluster']==1]
df_2 = df[df['cluster']==2]
df_3 = df[df['cluster']==3]
df_4 = df[df['cluster']==4]
column_means0 = df_0.mean(axis=0)
column_means1 = df_1.mean(axis=0)
column_means2 = df_2.mean(axis=0)
column_means3 = df_3.mean(axis=0)
column_means4 = df_4.mean(axis=0)
df_means = pd.DataFrame([column_means0, column_means1, column_means2, column_means3, column_means4])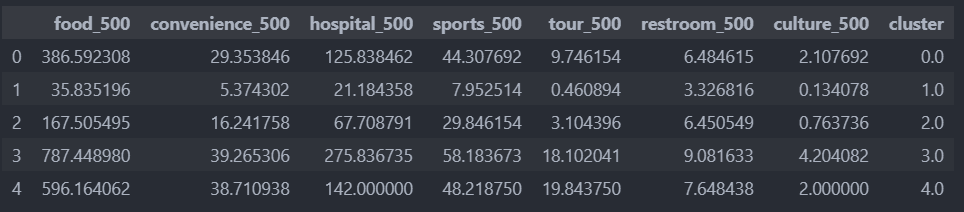
중앙값으로 보자.
# 중앙값
df_0 = df[df['cluster']==0]
df_1 = df[df['cluster']==1]
df_2 = df[df['cluster']==2]
df_3 = df[df['cluster']==3]
df_4 = df[df['cluster']==4]
column_means0 = df_0.median(axis=0)
column_means1 = df_1.median(axis=0)
column_means2 = df_2.median(axis=0)
column_means3 = df_3.median(axis=0)
column_means4 = df_4.median(axis=0)
df_means = pd.DataFrame([column_means0, column_means1, column_means2, column_means3, column_means4])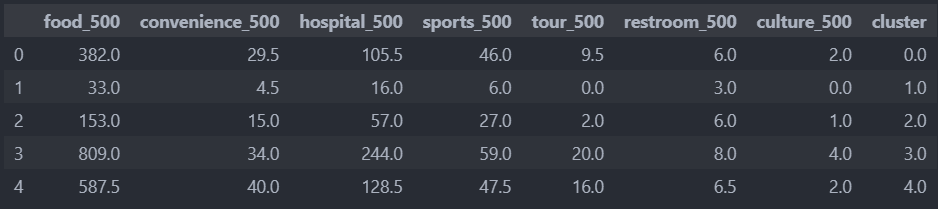
평균값이든 중앙값이든 분포가 비슷한 것을 확인할 수 있다.
시설 밀도 레벨
이제 밀도가 높은 순으로 '밀도 레벨'을 부가하여 시각화를 진행한다.
- 밀집도 순서: 3 -> 4 -> 0 -> 2 -> 1
밀집도를 추가하는 함수를 만든다.
# 밀집도 순서 추가하는 함수
def cluTolevel(df):
lev = []
for idx, row in df.iterrows():
if row['cluster'] == 3:
lev.append(4)
if row['cluster'] == 4:
lev.append(3)
if row['cluster'] == 0:
lev.append(2)
if row['cluster'] == 2:
lev.append(1)
if row['cluster'] == 1:
lev.append(0)
return lev
level = cluTolevel(df)그리고 밀집도별 시각화를 위해 밀도별로 색깔을 지정하여 좀 더 직관적으로 볼 수 있도록 함수를 작성한다.
- 밀집도 레벨 순서 : 빨 -> 주 -> 노 -> 초 -> 파
def color_select(row):
level = row.level
if level == 4:
return '#e87272' #빨 가장 밀도가 높음
elif level == 3:
return '#e8a372' #주
elif level == 2:
return '#e8dc72' #노
elif level == 1:
return '#37874a' #초
elif level == 0:
return '#6c99d9' #파 가장 밀도가 적음기존 데이터에 cluster와 밀도 레벨을 추가한다.
random_population_density_500['level'] = level
random_population_density_500['cluster'] = df['cluster']랜덤 좌표의 시설들의 밀도 레벨을 지도 시각화해보자.
반을 중심으로 상권지역인 위쪽은 밀도가 높고 주거지역은 밀집도가 낮은 것을 확인할 수 있다.
# 랜덤 좌표들의 시설물 밀도
m = folium.Map(location=[37.4966, 127.0628], zoom_start=13)
m.choropleth(geo_data=geo_str, fill_color='#bdbbbb')
for idx, row in random_population_density_500.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
radius=50,
color=color_select(row),
fill_color=color_select(row)
).add_to(m)
m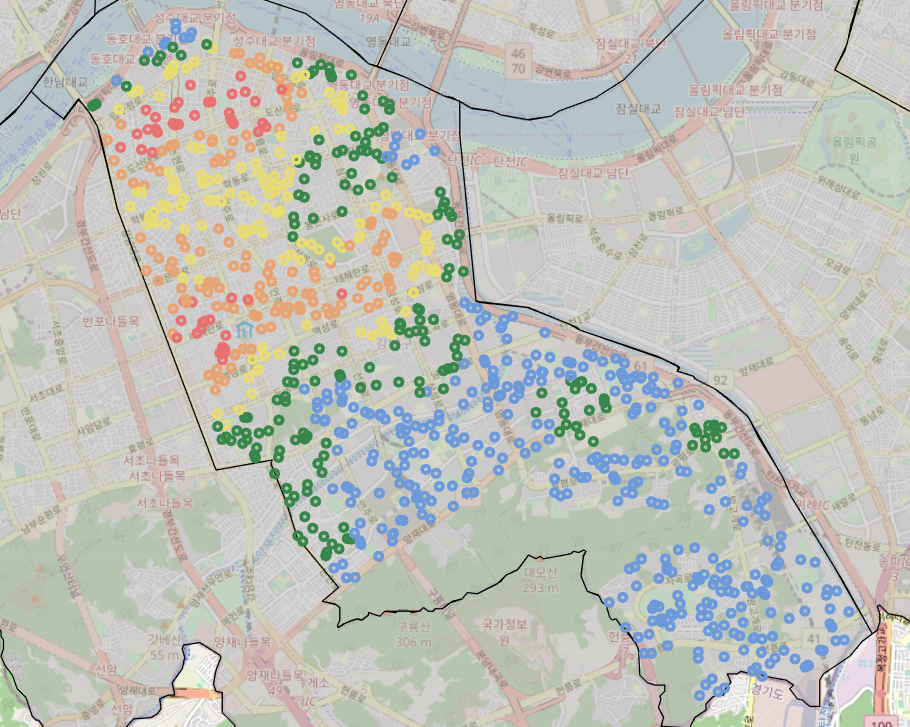
생활인구(10만명) 대비 시설 밀도 레벨
이제는 생활인구(10만명)대비 시설물의 밀집도를 확인해보자.
10만명당 시설물을 계산한 것을 가져온다.
df = random_population_density_500[['lat', 'lng', 'pop_of_convenience', 'pop_of_restroom', 'pop_of_sports', 'pop_of_tour', 'pop_of_food', 'pop_of_culture', 'pop_of_hospital']]그리고 다시 KMeans의 군집을 5개로 하여 군집화를 한다.
X = df[['pop_of_convenience', 'pop_of_restroom', 'pop_of_sports', 'pop_of_tour', 'pop_of_food', 'pop_of_culture', 'pop_of_hospital']]
# 인스턴스
kmeans = KMeans(n_clusters=5)
# 학습
kmeans.fit(X)
# 군집화 결과를 기존의 데이터이 붙이기
predict = pd.DataFrame(kmeans.predict(X), columns=['cluster'])
df = pd.concat([X, predict], axis=1)
# cluster별로 '평균'을 보고 밀집도 순서를 확인.
df_0 = df[df['cluster']==0]
df_1 = df[df['cluster']==1]
df_2 = df[df['cluster']==2]
df_3 = df[df['cluster']==3]
df_4 = df[df['cluster']==4]
column_means0 = df_0.mean(axis=0)
column_means1 = df_1.mean(axis=0)
column_means2 = df_2.mean(axis=0)
column_means3 = df_3.mean(axis=0)
column_means4 = df_4.mean(axis=0)
df_means = pd.DataFrame([column_means0, column_means1, column_means2, column_means3, column_means4])인구수 대비 시설 밀집도 순서 : 1 -> 3 -> 2 -> 4 -> 0

다시 밀도 순서를 재배치 하고
# 밀도 레벨 추가 함수 -> 밀도 순으로 번호 부여
def pop_of_cluTolevel(df):
lev = []
for idx, row in df.iterrows():
if row['cluster'] == 1:
lev.append(4)
if row['cluster'] == 3:
lev.append(3)
if row['cluster'] == 2:
lev.append(2)
if row['cluster'] == 4:
lev.append(1)
if row['cluster'] == 0:
lev.append(0)
return lev
level = pop_of_cluTolevel(df)밀도에 색깔을 부여한다.
# 밀도에 색깔 부여
def pop_of_color_select(row):
level = row.pop_of_level
if level == 4:
return '#e87272' #빨 가장 밀도가 높음
elif level == 3:
return '#e8a372' #주
elif level == 2:
return '#e8dc72' #노
elif level == 1:
return '#37874a' #초
elif level == 0:
return '#6c99d9' #파 가장 밀도가 적음기존 데이터에 다시 부여된 level을 추가하고 지도 시각화를 해보자.
# 기존 데이터에 인구수 대비 레벨 붙이기
random_population_density_500['pop_of_level'] = level
# 랜덤 좌표들의 인구수 대비 시설물 밀도 지도 시각화
m = folium.Map(location=[37.4966, 127.0628], zoom_start=13)
m.choropleth(geo_data=geo_str, fill_color='#bdbbbb')
for idx, row in random_population_density_500.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
radius=50,
color=pop_of_color_select(row),
fill_color=pop_of_color_select(row)
).add_to(m)
m2곳이 눈에 띄는데, 강남역 주변과 테헤란로 주변의 시설물의 밀집도가 높았지만 생활인구수(10만명)로 나누었을 때에는 밀집도가 떨어지는 것을 볼 수 있다.
그리고 수석역 주변은 평균적으로는 낮은 밀집도이지만 주거지역에서는 높은 편이었는데, 생활인구수(10만명)로 나누었을 때에는 밀집도가 오히려 올라가는 것을 볼 수 있다.
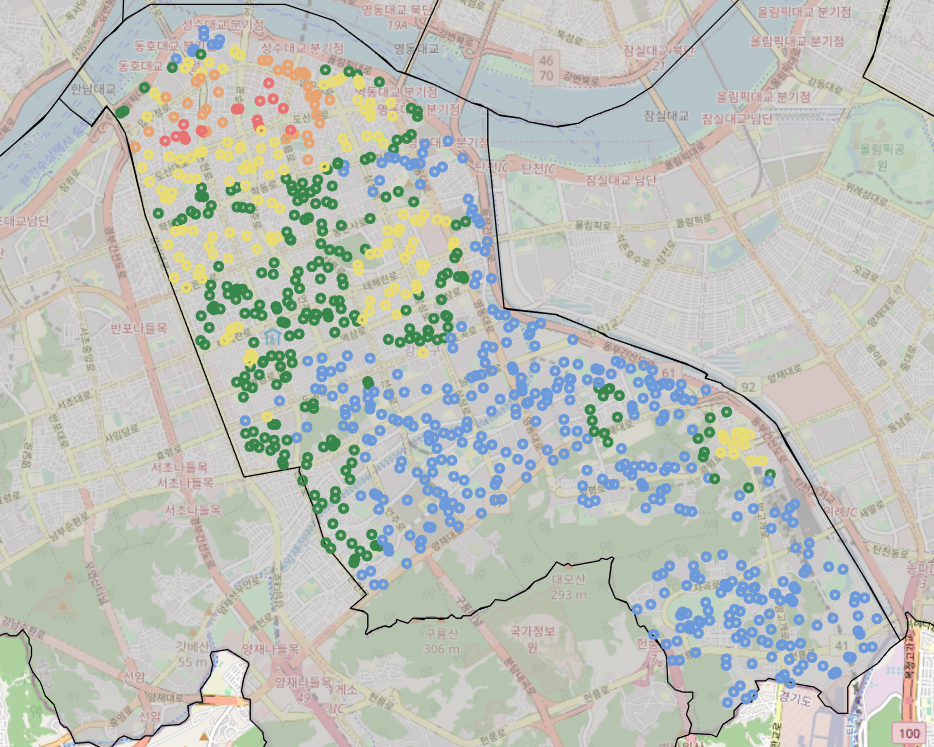
시설 밀도와 생활인구 대비 밀도 차이
그렇다면 시설별로 살펴보았을 때, 인구수 대비 밀도가 올라가는 지역은 자영업을 시작하기에 좋은 위치는 아닌 것 같아 보이고
밀도가 내려가는 부분은 자영업을 시작하기에 괜찮은 지역일 수 있을 것 같다.
그리고 밀도 변화가 없는 지역은 시설물과 인구수가 적절히 분포되어 있다고 봐도 될 것 같다.
그러면 밀도별 차이를 지도 시각화를 해보자.
# 밀도 레벨 차이
random_population_density_500['diff_level'] = random_population_density_500['pop_of_level'] - random_population_density_500['level']
# 밀도 증감을 색깔로 시각화하는 함수
# 차이 : 빨: 밀도 증가 / 노: 밀도 변화 없음 / 파: 밀도 감소
def r_color_select(row):
level = row.diff_level
if level < 0:
return '#6c99d9' #파 추천지역
elif level == 0:
return '#e8dc72' #주 평균 지역
else:
return '#e87272' #빨 비 추천지역
m = folium.Map(location=[37.4966, 127.0628], zoom_start=13)
m.choropleth(geo_data=geo_str, fill_color='#bdbbbb')
for idx, row in random_population_density_500.iterrows():
folium.Circle(
location=[row['lat'], row['lng']],
radius=50,
color=r_color_select(row),
fill_color=r_color_select(row)
).add_to(m)
m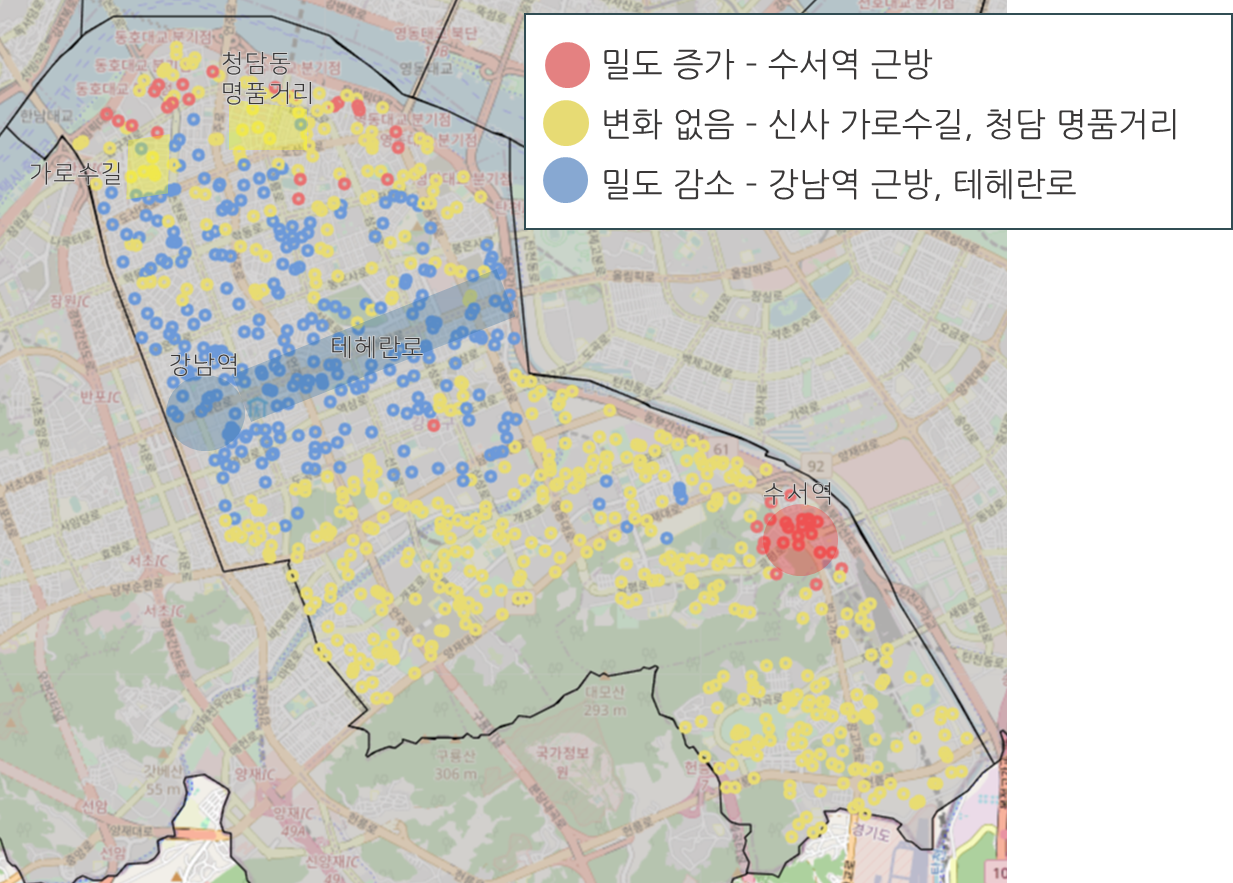
지하철역 주변 밀도
지하철역 500미터 반경 내 시설물 밀도를 확인해보자.
지하철역 주변 시설들의 위/경도 반환 함수를 먼저 작성하고
# 강남구 지하철역 반경 500m 이내 시설들의 위/경도 반환 함수
def facilityTo500(df):
low = []
l = []
for i, r in subway.iterrows():
c = (r['위도'], r['경도'])
for idx, r in df.iterrows():
lat = r['lat']
lng = r['lng']
sub = (lat, lng)
if haversine(c, sub, unit='m') < 500:
l = []
l.append(lat)
l.append(lng)
low.append(l)
return low지하철역 주변 500미터 내 시설별 개수를 만든다.
lists = [food, convenience, hospital, sports, tour, restroom, culture]
r_within = []
# 강남구 지하철 좌표
for i, r in subway.iterrows():
r_with = []
c = (r['위도'], r['경도'])
r_with.append(r['위도'])
r_with.append(r['경도'])
# 인허가 시설 모든 좌표
for lis in lists:
count = 0
for idx, row in lis.iterrows():
lat = row['lat']
lng = row['lng']
sub = (lat, lng)
if haversine(c, sub, unit='m') < 500:
count += 1
r_with.append(count)
print(r_with)
r_within.append(r_with)그리고 KMeans를 다시 적용하여 지하철역의 좌표를 가지고 level을 생성한다.
#가져올 컬럼 이름
cols = ['lat', 'lng', 'food_500', 'convenience_500', 'hospital_500', 'sports_500', 'tour_500', 'restroom_500', 'culture_500']
# DataFrame 만들기
r_df = pd.DataFrame(r_within, columns=cols)
X = r_df[['food_500', 'convenience_500', 'hospital_500', 'sports_500', 'tour_500', 'restroom_500', 'culture_500']]
# KMeans 적용
predict = pd.DataFrame(kmeans.predict(X), columns=['cluster'])
r_df = pd.concat([r_df, predict], axis=1)
level = cluTolevel(r_df)
r_df['level'] = level # level 반환
# 지하철역 반경 500m 이내의 시설들의 위도/경도 반환
food_500 = facilityTo500(food)
convenience_500 = facilityTo500(convenience)
hospital_500 = facilityTo500(hospital)
sports_500 = facilityTo500(sports)
tour_500 = facilityTo500(tour)
restroom_500 = facilityTo500(restroom)
culture_500 = facilityTo500(culture)
# 음식점 빨강, 편의점 파랑, 병원 초록, 스포츠 초록, 여행 파랑, 화장실 보라, 문화 보라로 시각화
def m_color(idx):
if idx == 0:
return '#e87272' #빨
elif idx == 1:
return '#e8a372' #주
elif idx == 2:
return '#e8dc72' #노
elif idx == 3:
return '#37874a' #초
elif idx == 4:
return '#6c99d9' #파
elif idx == 5:
return '#6c99d9' #파
elif idx == 6:
return '#6c99d9' #파
# 지하철 밀도 레벨별 색상
def subway_color_select(row):
level = row.level
if level == 4:
return 'red' #빨 가장 밀도가 높음
elif level == 3:
return 'orange' #주
elif level == 2:
return 'beige' #노
elif level == 1:
return 'green' #초
elif level == 0:
return 'blue' #파 가장 밀도가 적음
# 지도 시각화
lists = [food_500, convenience_500, hospital_500, sports_500, tour_500, restroom_500, culture_500]
m = folium.Map(location=[37.4966, 127.0628], zoom_start=13)
m.choropleth(geo_data=geo_str, fill_color='#bdbbbb')
for idx, lis in enumerate(lists):
for row in lis:
folium.Circle(
location=[row[0], row[1]],
radius=10,
color=m_color(idx) # idx에 따라 원형 마커 색상 선택
).add_to(m)
for idx, row in r_df.iterrows():
folium.Marker(location=[row['lat'], row['lng']],
popup='random',
icon=folium.Icon(color=subway_color_select(row))).add_to(m)
m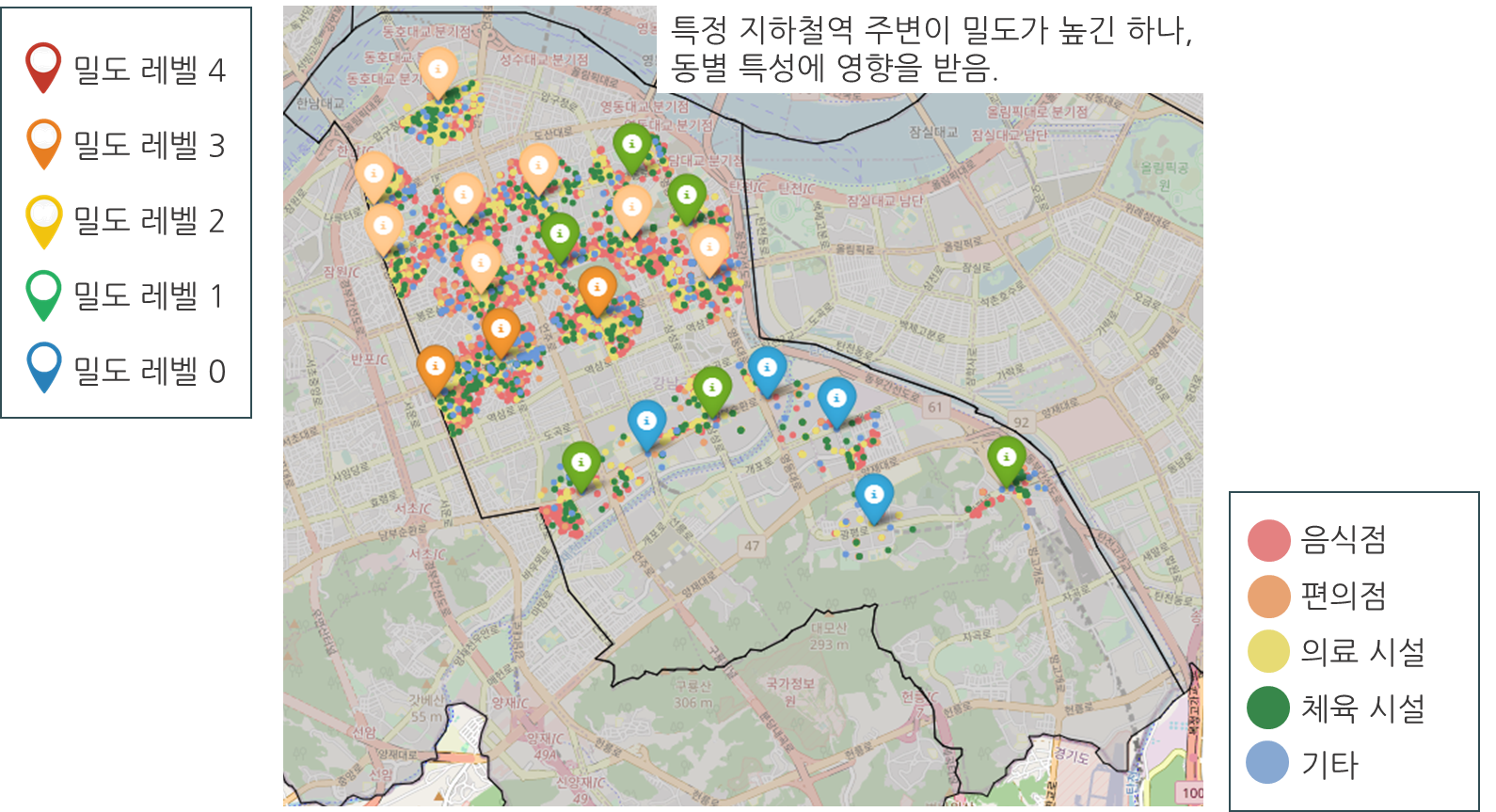
활용방안
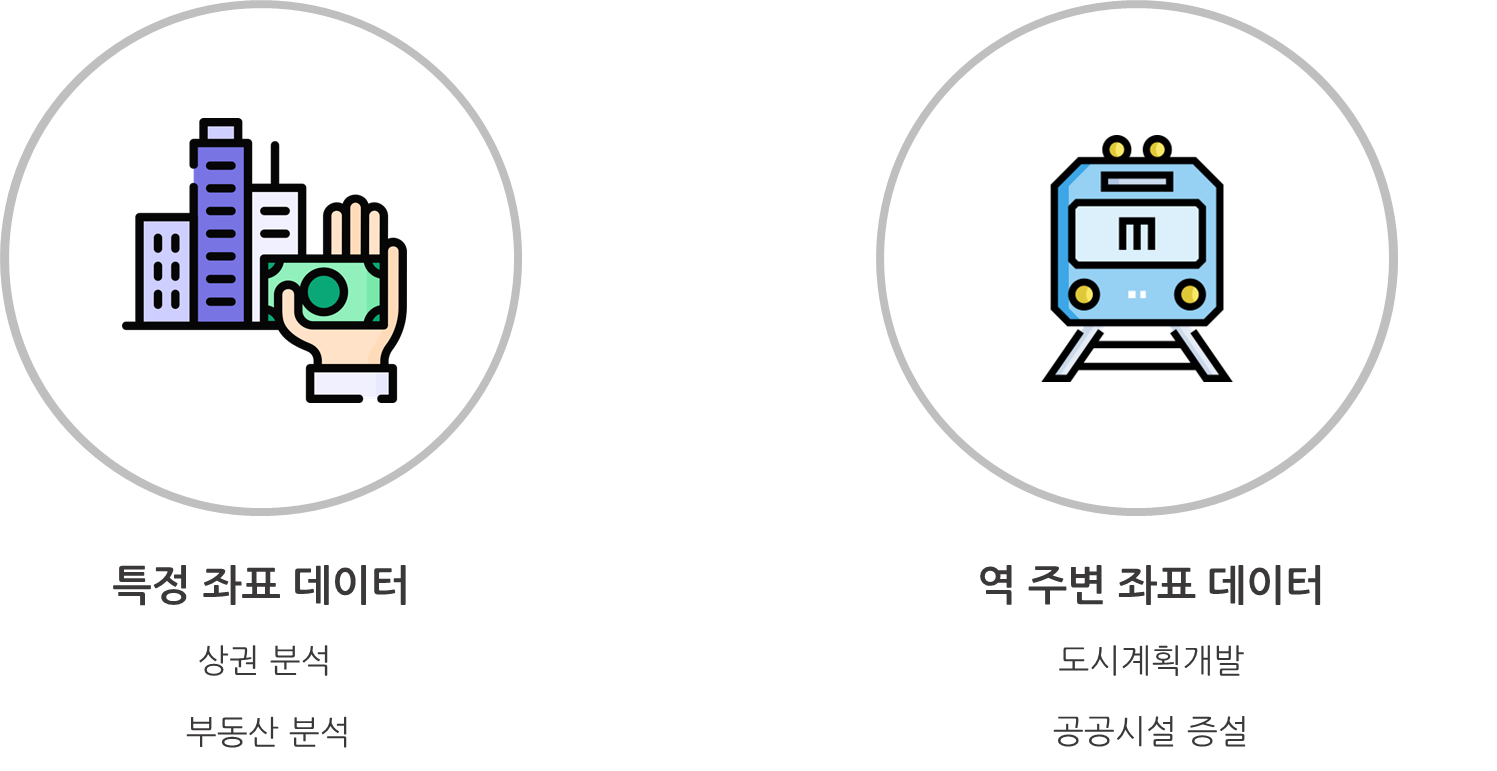
1) 랜덤좌표를 이용했을 때
[상권 및 부동산 시장 분석]
- 부동산 투자자 : 관심있는 구역의 주변정보 및 유동인구를 파악할 수 있음
- 프랜차이즈 및 자영업자 : 관심있는 구역에 경쟁업체 밀집도를 파악 가능 유동인구 데이터를 통해 잠재고객이 어느정도 있는지 파악 가능
2) 역 좌표를 이용했을 때
[도시계획개발에 대한 인사이트 제공]
- 도시계획가 및 강남구청 관계자 : 역 주변 밀집도 및 상권분석을 통해 행정동 개발을 위한 우선순위를 파악할 수 있음 (유동인구 데이터와 주변 시설 밀집도 분석 활용)
3) 공공시설 관련
- 유동인구가 많은 지역이고 밀집화된 구역이지만 화장실, 문화 시설, 체육 시설이 열악한 지역 파악 후 증설하기 위한 정보 파악
