
AB 테스트
임의로 나눈 둘 이상의 집단에 서로 다른 컨텐츠를 제시한 뒤, '통계적 가설 검정'을 이용하여 어느 컨텐츠에 대한 반응이 더 효과적인지 파악하는 방법.
소스 코드 및 테스트 자료 참고 : GitHub
문제 정의
온라인 쇼핑몰 페이지 구성에 따른 다양한 실험 결과를 바탕으로 '전환율'이 최대가 되는 구성을 진행.
- 전환율 : 페이지에 접근하여 구매 및 기타 상황이 발생할 확률.
STEP
1. 현황 파악
2. 상품 배치와 상품 구매 금액에 따른 관계 분석
3. 사이트맵 구성에 따른 체류 시간 차이 분석
4. 할인 쿠폰의 효과 분석
5. 체류 시간과 구매 금액 간 관계 분석
5. 구매버튼 배치에 따른 구매율 차이 분석
STEP 1. 현황 파악
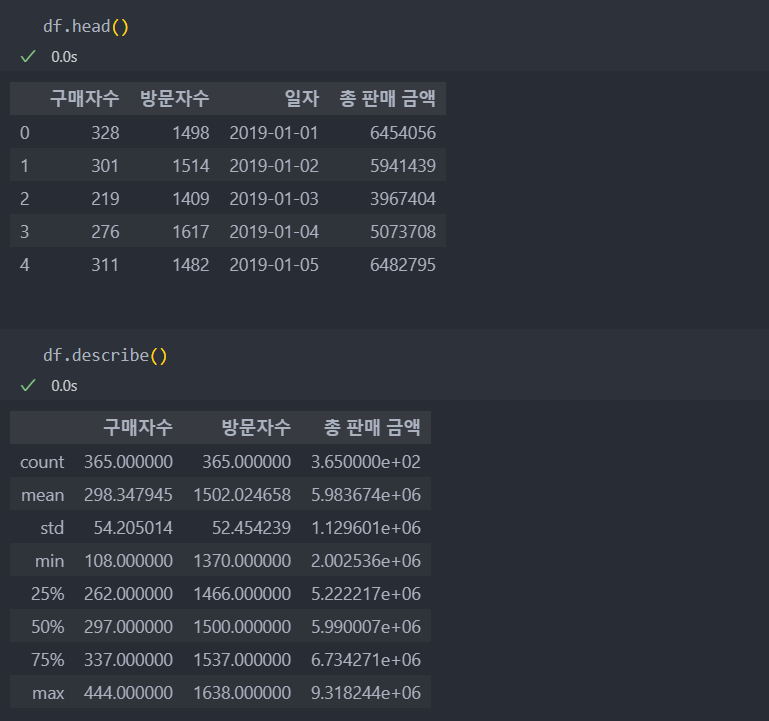
- 구매자수, 방문자수, 총 판매 금액에 대한 기술 통계
- 일자별 방문자수 추이 파악
- 일자별 구매자수 추이 파악
- 일자별 총 판매 금액 추이 파악
일별 추이 데이터를 보고 기술통계를 확인해보자.
추이를 파악해 보기 위해 라인 그래프로 확인해보자.
아래의 그래프를 살펴보면 특별한 방문자/구매자/판매 금액에 대한 패턴(주기성, 계절성)은 보이지 않는다.
방문자수 추이 그래프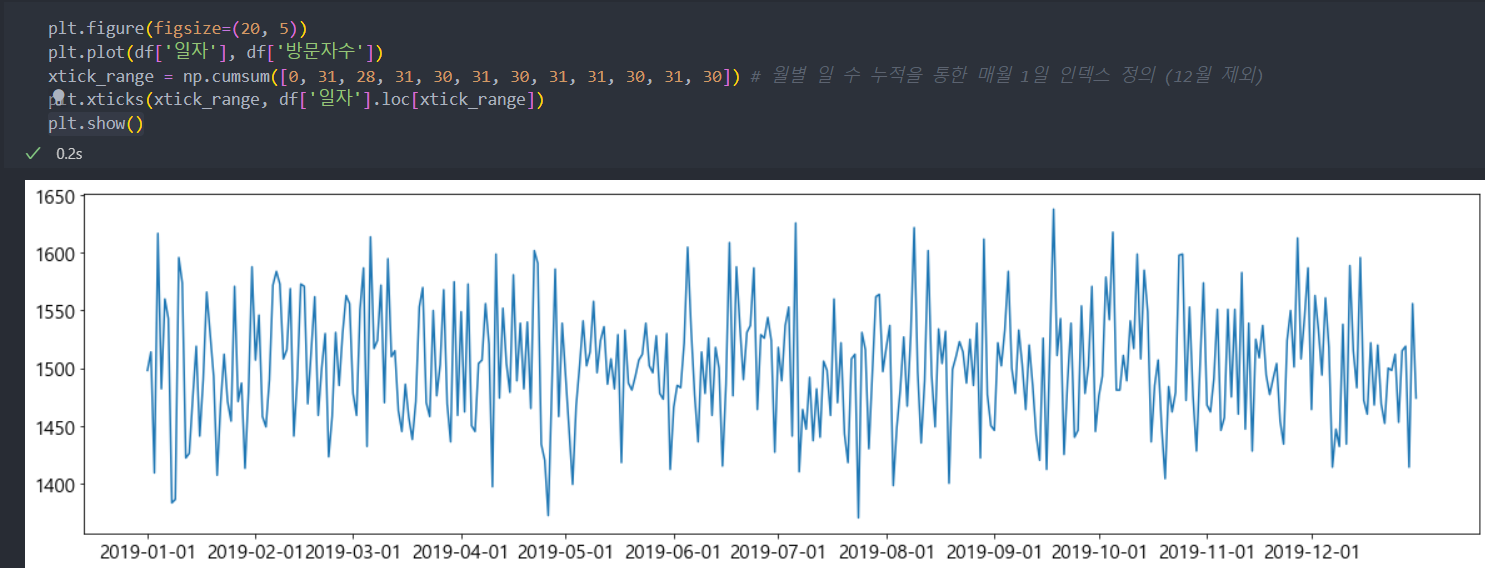
구매자수 추이 그래프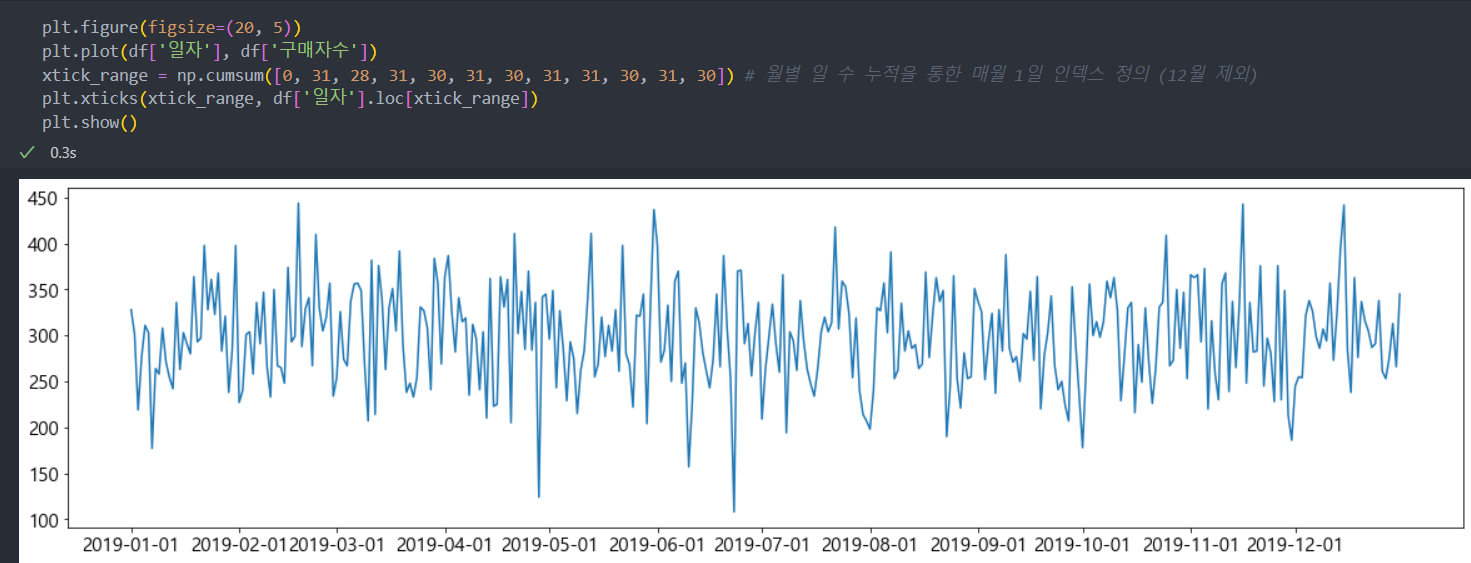
총 판매 금액 추이 그래프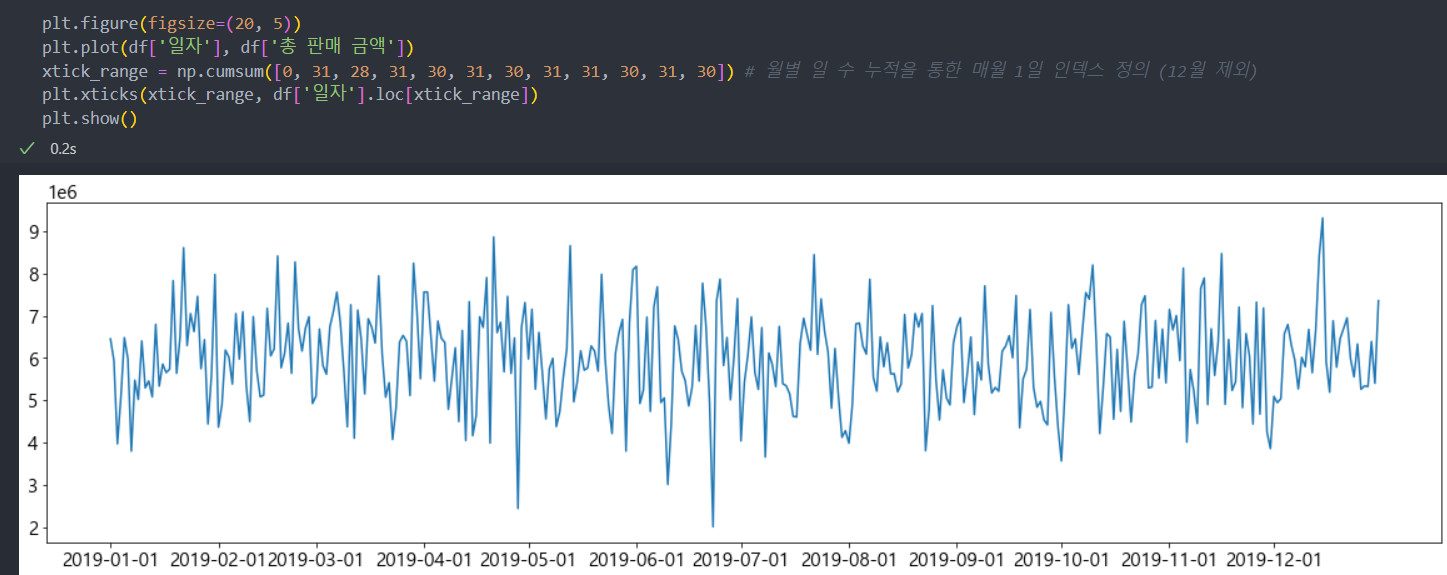
STEP 2. 상품 배치와 상품 구매 금액에 따른 관계 분석
- 일원분산분석을 이용한 상품 배치에 따른 상품 구매 금액 평균 차이 분석(구매 금액이 0원인 것은 제외)
참고 : 일원분산분석과 사후분석- 일원분산분석을 이요한 상품 비치에 따른 상품 구매 금액 평균 차이 분석(구매 금액이 0원인 것은 포함)
- 카이제곱 검정을 이용한 구매 여부와 상품 배치 간 독립성 파악
참고 : 카이제곱 검정
상품 배치 A, B, C의 데이터를 확인하고 구매 금액과의 관계를 살펴보자.
데이터는 고객 ID별 구매 금액 데이터다.
A, B, C 데이터의 구매 고객은 랜덤하게 배치된 각각 다른 집단이다.
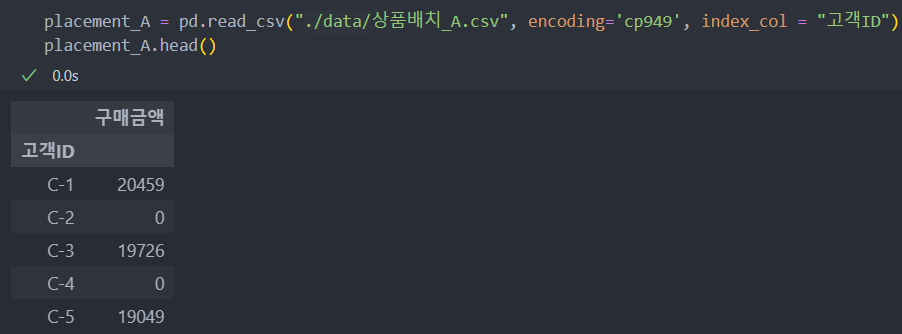
1 구매 금액이 0인 고객의 구매 금액 데이터는 제외
3그룹 이상의 평균 차이를 확인해보기 위해 일원분산분석을 통해 확인해보자.
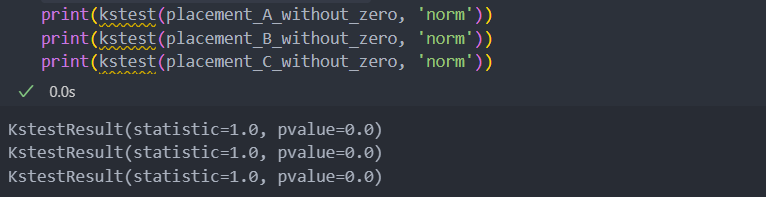
각 그룹이 정규성을 띄는지 확인한 후(p-value<0.05 미만으로 정규성을 띈다),
일원분산분석을 진행한다.
p-value가 0에 수렴하는 것으로 보아 평균에 차이가 있는 그룹이 있는 것을 확인할 수 있다.

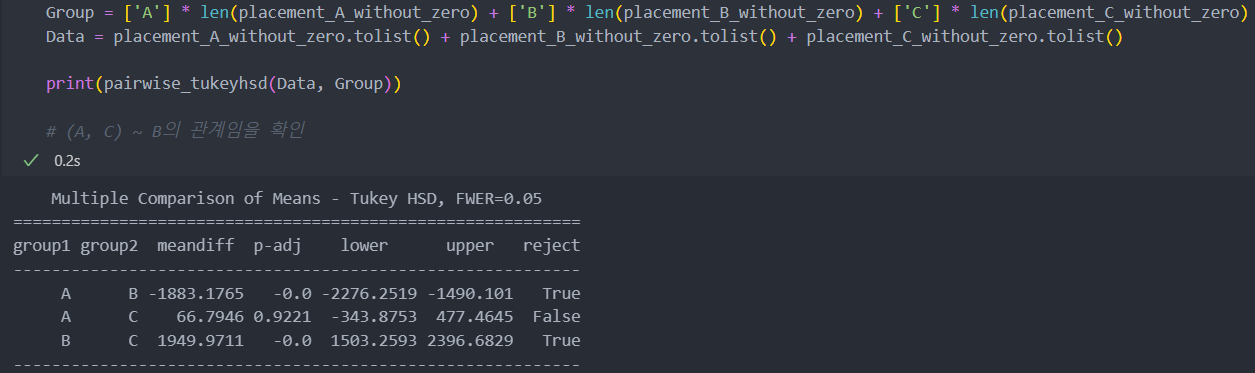
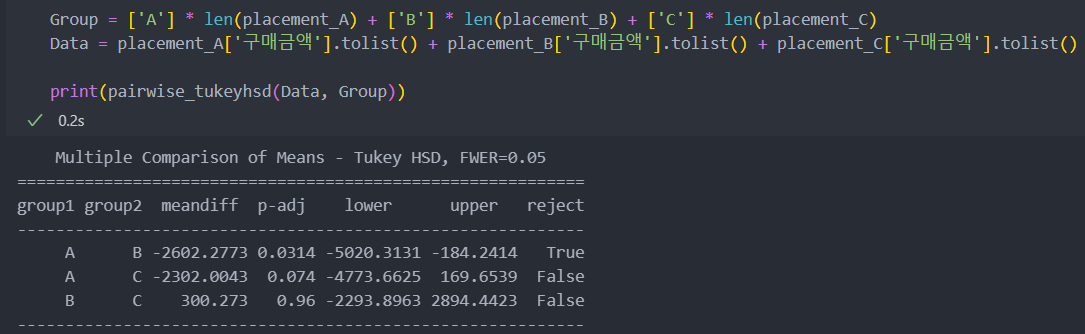
어느 그룹에서 평균 차이가 발생했는지 확인하기 위해 사후 분석을 진행한다.
'A-C'에 비해서 'A-B', 'B-C'에서 meandiff의 차이가 많이 나는 것으로 보아서 그룹 'B'가 'A, C'와는 다른 평균값을 가진다는 것을 확인할 수 있다.
2. 구매 금액이 0인 고객의 구매 금액 데이터 포함
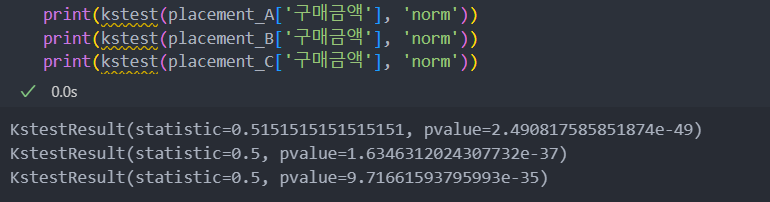
각 그룹이 정규성을 띄는지 확인한 후(p-value<0.05가 0에 매우 가까운 값을 띄고 있으므로 정규성을 띈다),
일원분산분석을 진행한다.
p-value가 0.05 미만인 것으로 보아 평균에 차이가 있는 그룹이 있는 것을 확인할 수 있다.

어느 그룹에서 평균 차이가 발생했는지 확인하기 위해 사후 분석을 진행한다.
'B-C'에 비해서 'A-B', 'A-C'에서 meandiff의 차이가 많이 나는 것으로 보아서 그룹 'A'가 'B, C'와는 다른 평균값을 가진다는 것을 확인할 수 있다. 그런데 구매 금액 '0'원을 제외했을 때와는 달리 'A, C'도 유의한 차이가 '없다'고 False값을 반환하는 것으로 보아 약간 애매한 구석이 있다.
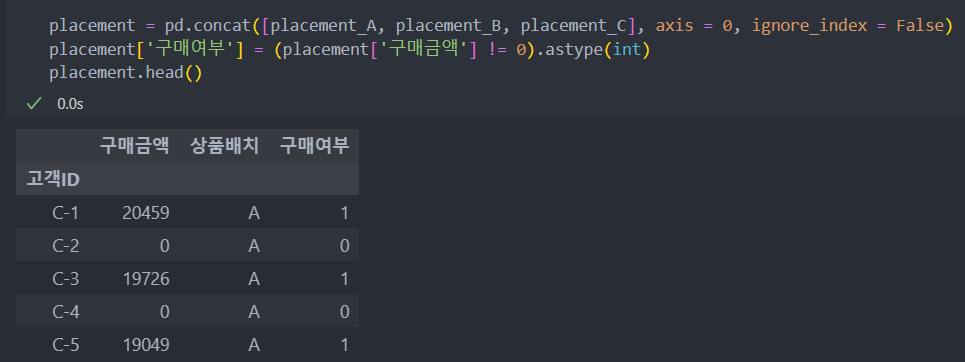
3. 구매 여부와 상품 배치 간 관계 파악
각 그룹 A, B, C에 컬럼을 추가하여 그룹 상품과 구매 여부(미구매:0, 구매:1) 데이터 생성
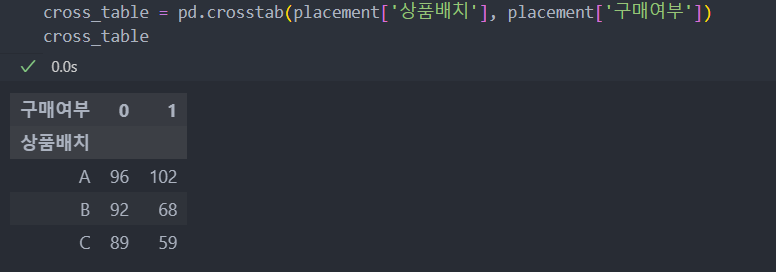
교차 테이블을 생성한다.
그룹 A로 배치를 하였을 때가 'B, C'로 배치하였을 때보다 구매가 많이 일어나는 것으로 보아 상품 배치는 'A'로 하는 것이 적절해 보인다.
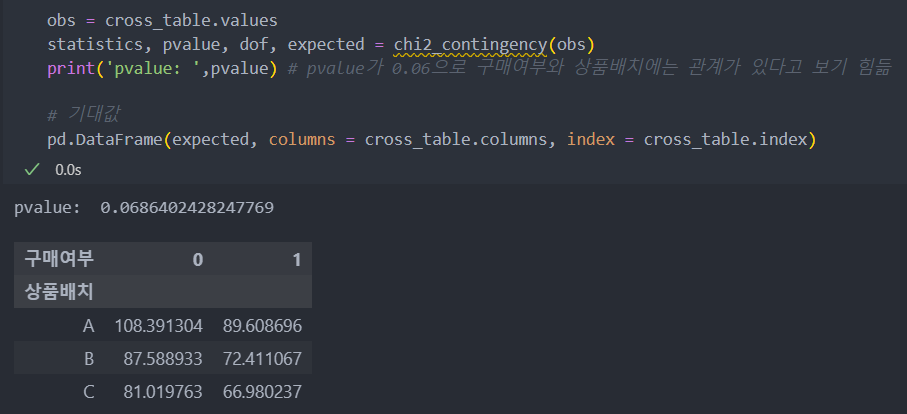
보다 자세한 분석을 위해 카이제곱 검정을 진행한다.
p-value가 0.05 이상인 것으로 보아 구매와 상품 배치는 관계가 있다고 보기는 힘들지만, 기대값과 실제값을 확인하고 교차 테이블을 보았을 때에는 'A'의 배치가 좋아 보인다.
STEP 3. 사이트맵 구성에 따른 체류 시간 차이 분석
- 사이트맵별 체류시간 평균 계산
- 일원분산분석을 이용한 사이트맵에 따른 체류 기간 평균 차이 분석
각 A, B, C의 사이트 맵의 데이터를 가지고 분석해보자.
먼저, 사이트맵별 체류 시간들을 가져와서 사이트맵별 평균 체류 시간을 확인해보자.
아래의 각 체류시간의 차이가 유의한 차이를 가지는 것인지 확인해보자.
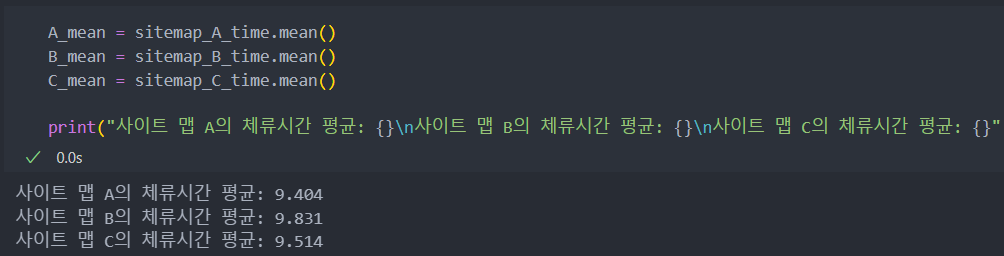
평균값이 비슷해 보이는 것의 분포를 시각화하여 자세히 들여다보자.
체류 시간의 편차가 A -> B -> C로 갈수록 커지고 있다.
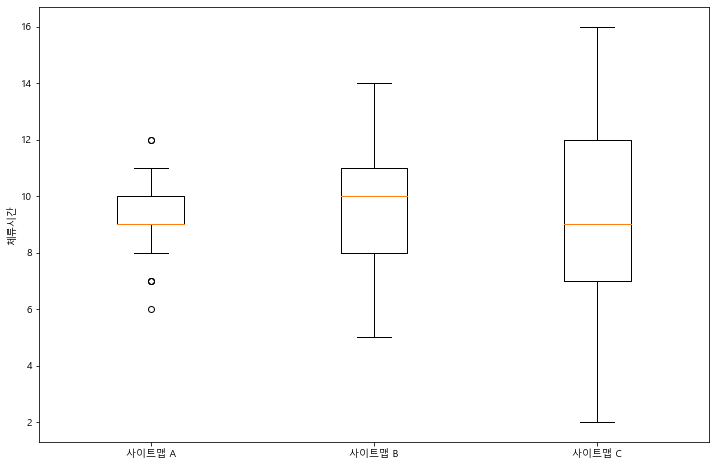
정규분포를 따르는지 확인해 보니 0이거나 0에 수렴하는 것으로 보아 정규성을 띄고 있다고 볼 수 있다.
이제 일원분산분석을 진행해보자.
p-valeu가 0.2 정도이므로 사이트맵의 체류 시간은 우연에 의한 것이라 판단할 수 있다.
위의 박스 플롯의 편차를 가지고 판단을 내려야 할 수도 있다.

STEP 4. 할인 쿠폰의 효과 분석
- 발행후와 전의 구매 횟수 차이에 대한 기술 통계
- 발행 전, 발행 후의 구매 횟수에 대한 시각화
- 쌍체 표본 t검정을 이용한 차이 유의성 검정
참고: 쌍체표본 t검정
쿠폰 발행 전과 후의 비교 데터를 가지고 분석을 진행해보자.
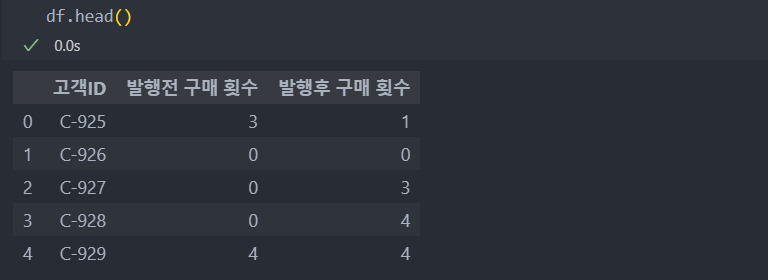
쿠폰 효과를 기술 통계 분석을 하기 위해 (발행 후 - 발행 전) 구매의 차이를 확인해보자.
평균적으로는 1.25번 더 구매를 한 것으로 보이나 최소값이 음수이고 표준편차가 2 이상으로 추가 검증이 필요해 보인다.
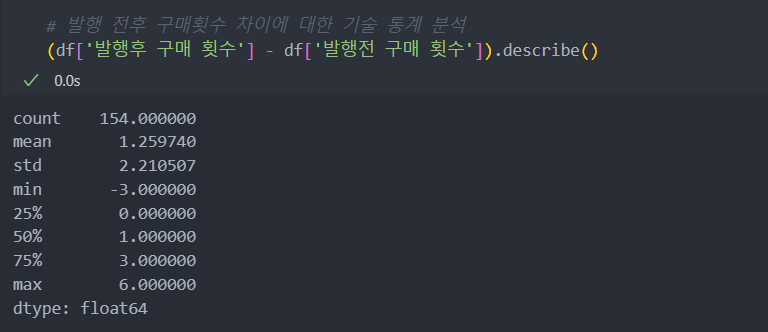
통계 수치와 더불어 시각적인 데이터를 통해 좀 더 세밀하게 보자.
그래프를 보았을 때 겹치는 구간을 제외하고 평균적으로 구매 횟수가 높아짐을 파악할 수 있다.
추가로 쌍체표본 t검정을 진행하기 위해 정규성 검정을 진행해보자.
p-value가 0에 수렴하는 것으로보아 정규성을 가진다.

쌍체표본 t검정을 진행해보자.
p-value가 0에 수렴하는 값으로 보아 우연이 아님을 알 수 있다.

STEP 5. 체류 시간과 구매 금액 간 관계 분석
- 구매 금액과 체류 시간의 산점도 시각화
- 구매 금액과 체류 시간 간 상관관계 분석
참고: 상관 분석
체류 시간과 구매 금액 데이터를 불러와서 분석해보자.
체류 시간에 따른 구매 금액이 어떻게 되는지 산점도 그래프로 자세히 보자.
그래프를 보았을 때 체류 시간이 길어질수록 구매 금액도 커지는 경향이 있다는 것을 확인할 수 있다.
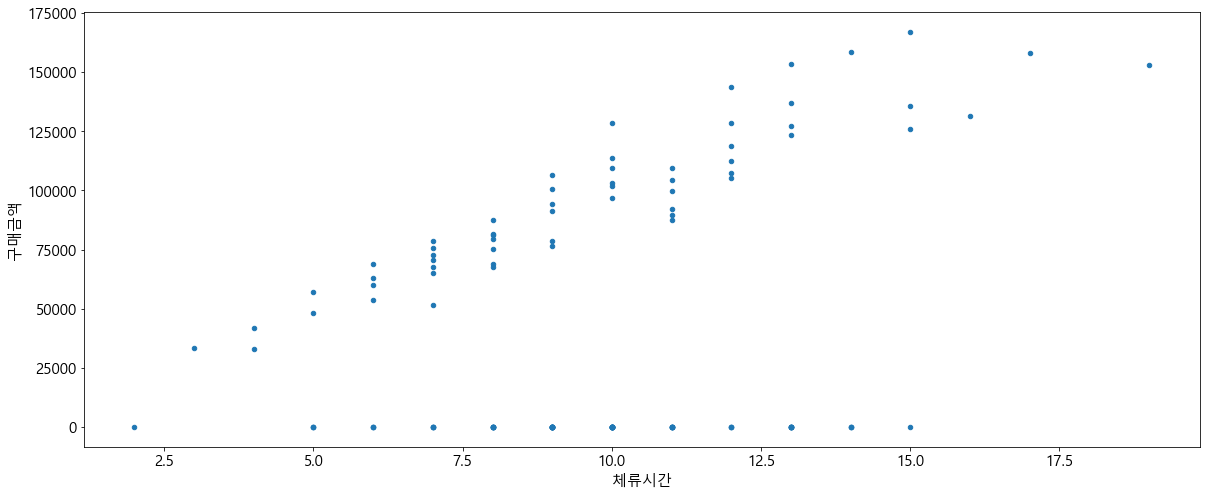
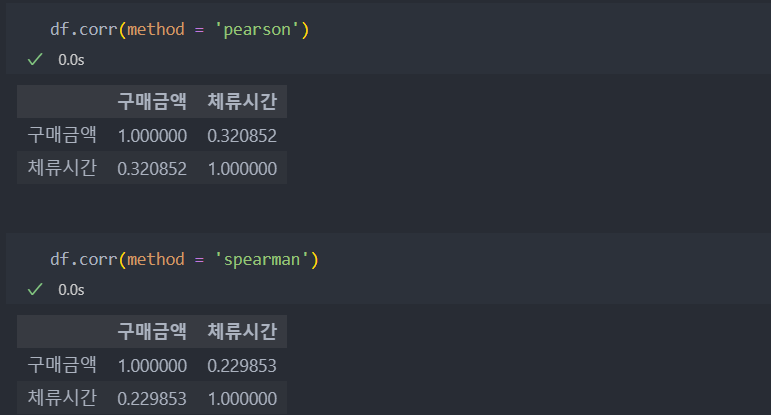
그럼 어떤 상관 관계가 있는 것인지 상관 분석을 통해 좀 더 자세히 보자.
통계학에서는 30% 정도가 되면 약한 선형 관계가 있다고 하지만, 실제 데이터에서 피어슨 상관 관계에서 30%의 상관 관계가 있다는 것은 유의미한 상관 관계가 있다고 판단한다. 그리고 스피어만 상관 관계(순위)는 피어슨 보다는 작고 체류 시간이 길다고 해서 무조건 구매 금액이 크다라고 단정 짓기는 어렵다는 것으로 확인할 수 있다.
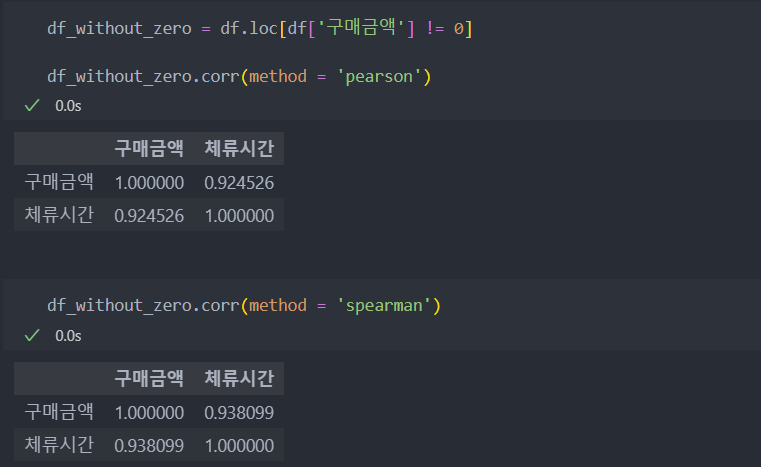
체류 시간에 상관없이 구매 금액이 0원인 데이터는 제외하고 다시 보자.
그러면 매우 큰 상관 관계를 보이는 것을 확인할 수 있다.
어떻게든 고객들이 사이트에 체류를 오래하도록 붙잡아야할 필요성이 매우 필요해 보인다.
STEP 6. 구매버튼 배치에 따른 구매율 차이 분석
- 결측 대체
- pivot table을 이용한 교차 테이블 생성
참고: 데이터 집계- 카이제곱검정을 이용한 독립성 검정
구매 버튼의 배치에 따른 데이터를 가지고 분석해보자.
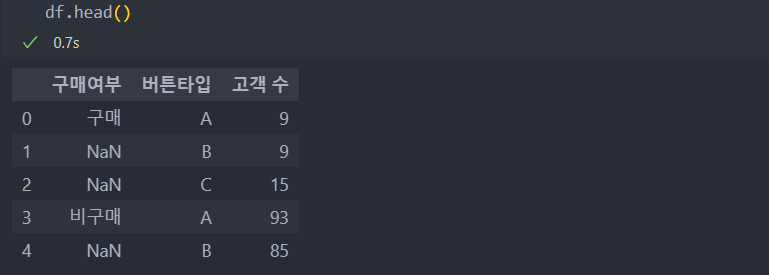
결측치가 보이는데, 엑셀 파일에서 가지고 온 것으로 결측치가 아니라 셀통합으로 인해 판다스로 불러오면서 결측치가 된 경우이다.
그래서 fillna에서 인자를 'ffill'로 앞의 데이터로 결측치를 채워준다.
데이터를 pivot_table로 집계하여 인덱스에는 구매/비구매를 컬럼에는 버튼 종류 그리고 값에는 고객수를 넣고,
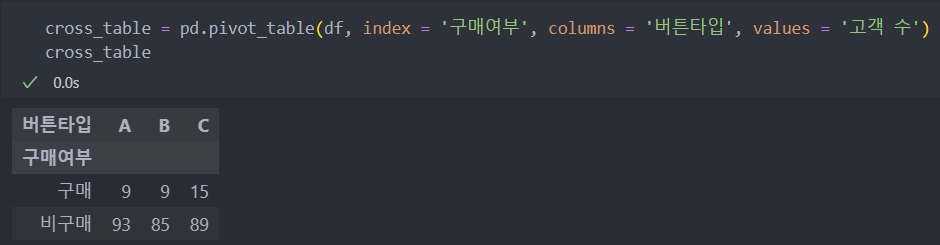
카이제곱 검정을 진행해보자.
p-value가 0.38로 버튼과 구매와는 관계가 없을 확률이 높다는 것을 확인할 수 있다.

