
✔️ 통계 기초 4~5
모집단과 표본

- 표본추출(Sampling) : 모집단으로 부터 표본을 추출 하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 함
- 복원추출(Sampling with replacement) : 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출 될 수 있음
- 비복원추출(Sampling without replacement) : 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
- Random Sampling : 각 개체가 모두 동일한 확률로 추출하는 방법
* 모집단에서 데이터를 추출할 때 주의할 점 : 편향되지 않아야 함
- 불균형 데이터(Imbalanced Data)의 문제
- 데이터가 불균형 데이터 일 경우 문제가 생김
- 우리가 예측모형을 만드는 목적은 관심이 있는 대상이 발생할 확률을 예측하는 경우가 대부분임, 그런데 예측 대상이 전체 대비 아주 낮다면? 모형의 성능이 괜찮을가? (ex: 신용 평가 모형 개발, 제조 불량 예측 등)
1) Sampling 기법을 통하여 해결
2) 모델을 통한 성능 개선(ex: Cost-sensitive learning)
- Sampling 기법 : 관심의 대상의 아주 비율이 낮은 경우 적용
- Over Sampling
- 타겟 데이터 적은 class의 수를 많은 class의 비율만큼 증가 시킴(일정 비율로 복원추출 하는 개념)
- 과도적합의 문제 발생할 수 있음
- Under sampling
- 타겟 데이터의 많은 class의 수를 적은 class의 비율만큼 감소 시킴
- 임의로 뽑은 데이터가 biased(편향)될 수 있고, 모형의 성능이 떨어질 수 있음
- Over Sampling
표본 분포
- 통계량(Statistic): 표본에 기초하여 계산되는 수치 함수를 통계량이라고 함
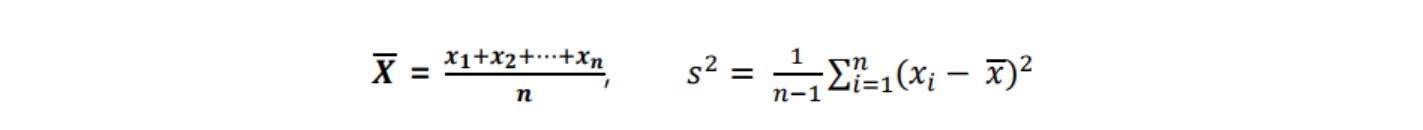
- 표본 분포(Sampling distribution) : 통계량들이 이루는 분포를 표본 분포라고 함
- 표본 평균(Sample mean)

- 표본 평균 기대값 : µ
- 표본 평균 분산 : σ²/n
- 중심극한 정리(central limit theorem)
- 평균이 µ 이고 분산이 σ²인 임의의 모집단에서 랜덤 표본 X₁, X₂, ... , Xn을 추출 할 때 표본의 크기 n이 충분히(n≥30)크면, 표본 평균은 근사적으로 정규분포 N(µ, σ²/n) 을 따른다
1. 카이제곱 분포(Chi-square distribution)
- 확률 변수 Z²₁, Z²₂, ... , Z²n가 표준 정규 분포를 따른다면, 확률 변수 Z는 Z²₁+Z²₂+ ... + Z²n
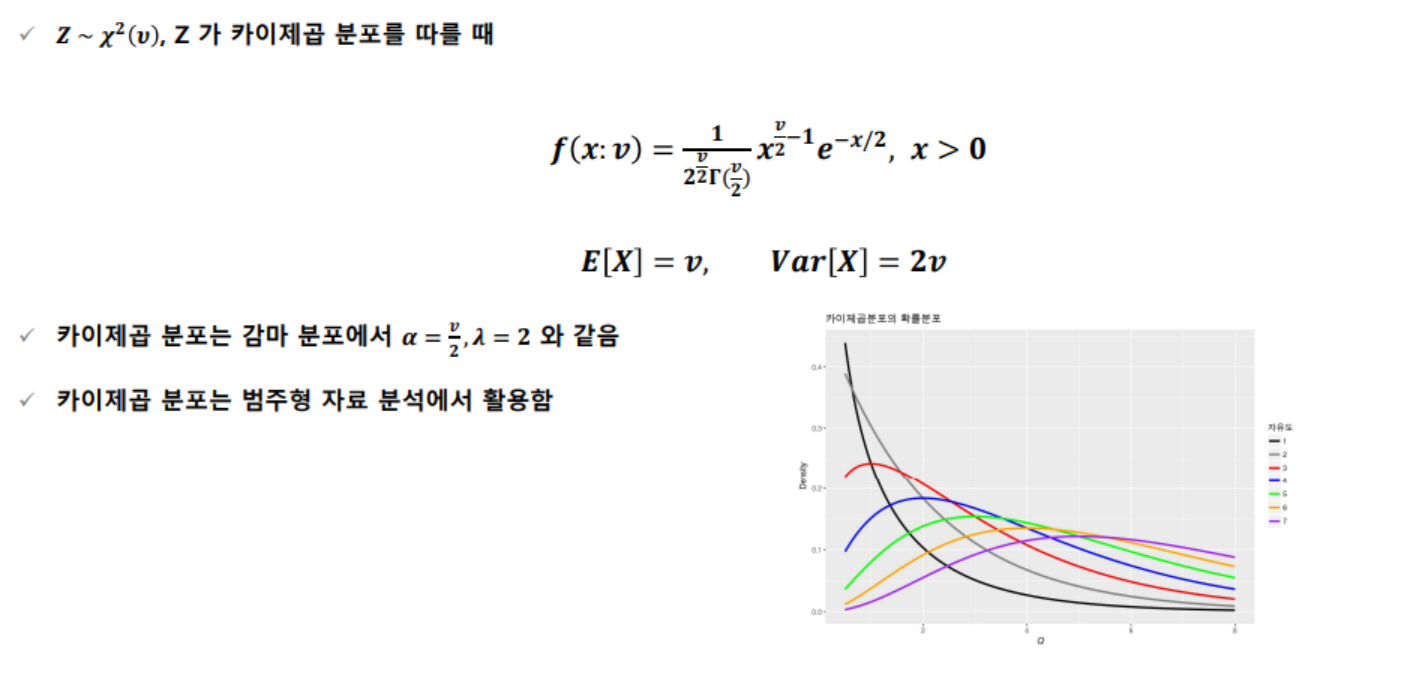
- 자유도(degree of freedom) : 표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미하며 일반적으로 n-1을 사용함
- 카이제곱 분포는 자유도 v의 크기에 따라 모양이 달라짐 자유도가 커질수록 분포가 좌우 대칭 형태로 됨
- 카이제곱 분포는 자유도가 커지면서 표준정규 분포에 근사하며, v≥30이면, 확률을 근사적으로 정규분포로 구할 수 있음
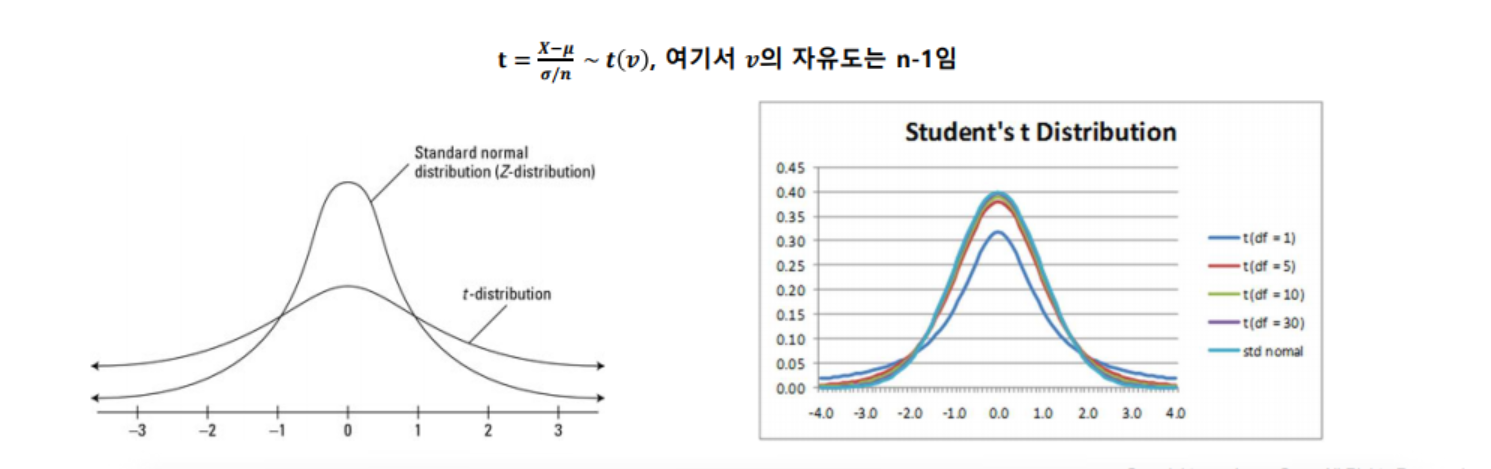
2. T분포(t-distribution)
- Z ~ N(0,1) 을 따르고, Y ~ X² 일 때, T = Z/√(Y/v)
- 만약 확률 변수 X가 정규분포를 따르고 모표준편차 σ를 안다면, Z = (X-µ)/(σ/n) ~ N(0,1)
- 만약 모표준편차 σ를 모른다면, σ를 대신해서 표본표준편차 s를 이용해 확률변수 Z를 정의
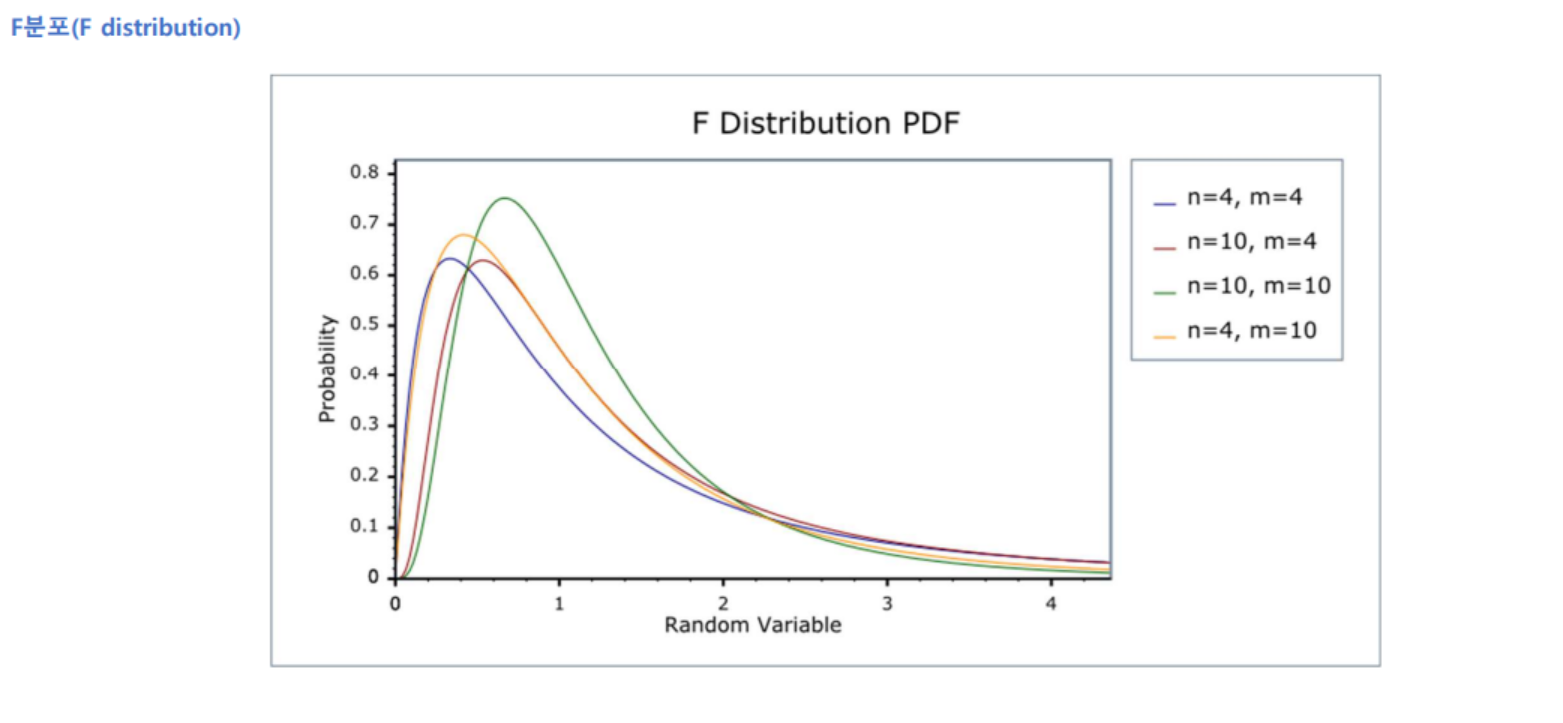
3. F분포(F distribution)
- Y₁ ~ X²(v₂), Y₂ ~ X²(v₂)이면, F ~ (Y₁/v₁)/(Y₂/v₂), F > 0

- 서로 독립인 두 정규모집단의 분산 또는 표준편차들의 비율에 대한 통계적 추론, 분산분석 등에 활용됨
추정
- 추정(estimation) : 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 함
- 추정량(estimator) : 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함
- 모수를 추정 하는 방법에는 점 추정(point estimation)과 구간 추정(interval estimation)이 있음
- 점 추정 : 모수를 하나의 특정값으로 추정 하는 방법
- 구간 추정 : 모수가 포함될 수 있는 구간을 추정하는 방법
점추정
- 성질
- 일치성(Consistency): 표본의 크기가 모집단의 크기에 근접해야 함
- 표본이 크기가 크면 클수록(모집단에 가까울 수록) 추정량의 오차가 작아짐 - 불편성(unbiased estimator): 추정량이 모수와 같아야 함
- 모수가 θ이고 추정량이 ŏ라고 정의하면, E[ŏ] = θ 이고, 이를 불편 추정량 이라고 함
- 즉, E[ŏ] = θ 일때의 추정량을 불편 추정량이라고 하고, 같지 않다면 편의(biased) 있다고 함
- 유효성(efficiency): 추정량의 분산이 최소값이어야 함
- 모수에 대한 추정량의 분산이 작을 수록 추정량이 효율적이다는 의미임
- 만약 모수 θ 의 불편 추정량이 ŏ₁, ŏ₂이라면 Var[ŏ₁] < Var[ŏ₂]이면, ŏ₁효율적인 추정량임
- 일치성(Consistency): 표본의 크기가 모집단의 크기에 근접해야 함
- 평균오차제곱(Mean Squared Error, MSE) : 평균오차제곱이 최소값이어야 함
- E[(ŏ-θ)²]이 최소이어야 함
구간추정
- 모수가 포함될 수 있는 구간을 추정하는 방법
- 신뢰구간(confidence level) : 추정값이 존재하는 구간에 모수가 포함될 확률
- 신뢰 수준은 100 * (1-α)% 로 계산
- α : 오차 수준
- 신뢰 수준 95%라는 것은 구간 추정된 값의 오차가 발생할 확률이 5%라는 것을 의미
- 이 오차를 유의 수준(significant level)이라고 하며, p= 0.05라고 함

- 모평균의 구간 추정
- 모집단의 분산을 아는 경우

- 모집단의 분산을 모르는 경우

- 표본의 크기 결정
- 허용오차(permissible error) : 추정한 값이 틀려도 허용할 수 있는 오차
- 정규분포의 신뢰구간을 통해 허용 오차를 계산

- 모집단의 분산을 아는 경우
모비율 추정
모비율 점추정
- 비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면 ‘1’ 아니면 ‘0’일 때, 1의 속성을 갖는 것의 개수를 X라고 하면 X ~ B(n,p) 임
- 이 때 모비율의 점추정량을 표본 비율(sample proportion)이라고 함 (ϸ = X/n)
- 예시) A대학의 취업에 성공한 학생의 비율은 몇%일가? 표본을 통해서 전체 비율을 추정함
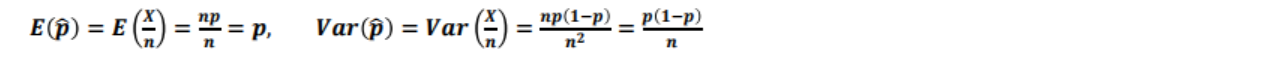
모비율 구간추정
- 모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 np>5, n(1-p)>5 를 동시에 만족 해야 함
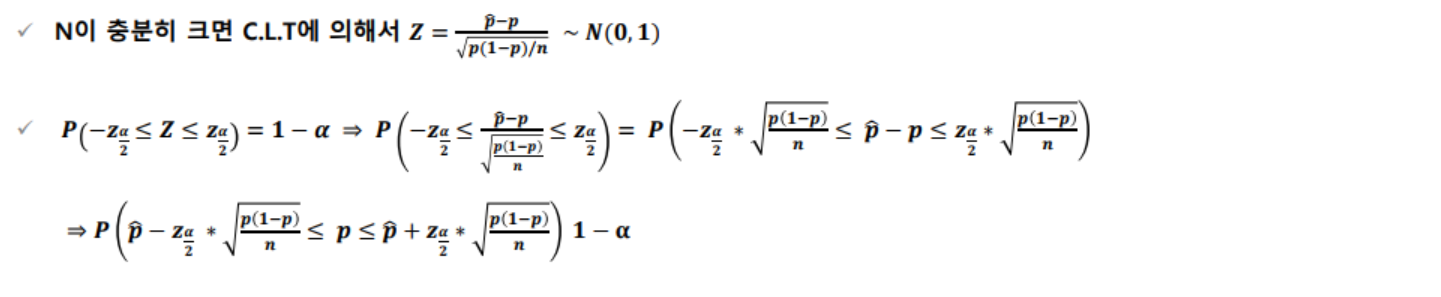





✔️ 통계 심화 1~2
가설검정
- 가설 검정 = 가설(Hypothesis) + 검정(Testing)
- 가설(hypothesis): 주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추축을 가설이라고 함
- 통계학에서는 특히 모수를 추청 할 때 모수가 어떠하다는 증명하고 싶은 추축이나 주장을 가설이라고 함
- 귀무 가설(Null hypothesis: H₀)
- 기존의 사실(아무것도 없다, 의미가 없다)
- 대립가설과 반대되는 가설로 연구하고자 하는 가설의 반대의 가설로 귀무 가설은 연구 목적이 아님
- Ex) H₀ : 코로나 백신이 효과가 없다 , H₀ : µ = 0
- 대립 가설(Alternative hypothesis: H₁)
- 데이터로 부터 나온 주장하고 싶은 가설 또는 연구의 목적으로 귀무가설의 반대
- Ex) H₁: 코로나 백신이 효과가 있다 , H₁: µ ≠ 0 or µ ≥ 0
- 제1종 오류(type I error): 귀무가설이 참이지만, 귀무가설을 기각하는 오류
- H₀를 기각할 확률이 α 라고 하면 채택하게 될 확률은 1−α 로 표시할 수 있음
- 제1종 오류를 범할 확률의 최대허용 한계를 유의수준이라고 하며, α 라고 표시
- 제2종 오류(type II error): 귀무가설이 기각해야 하지만, 귀무가설을 채택하는 오류
- 검정통계량: 귀무가설이 참이라는 가정하에 얻은 통계량
- 검정결과 대립가설을 선택하게 되면 귀무가설을 기각(reject)함
- 검정결과 귀무가설을 선택하게 되면 귀무가설을 기각하지 못한다고 표현함
- P-value: 귀무가설이 참일 확률
- 0~1사이의 표준화된 지표(확률값)
- 귀무가설이 참이라는 가정하에 통계량이 귀무가설을 얼마나 지지 하는지를 나타낼 확률
- 기각역(reject region): 귀무가설을 기각시키는 검정통계량의 관측값의 영역
- 가설 검정의 절차
- 가설 수립
- H₀ : 코로나 백신이 효과가 없다
- H₁ : 코로나 백신이 효과가 있다
- 유의 수준 결정: 유의 수준 정의
- 기각역 설정
- 검정통계량 계산
- 의사 결정
- 가설 수립
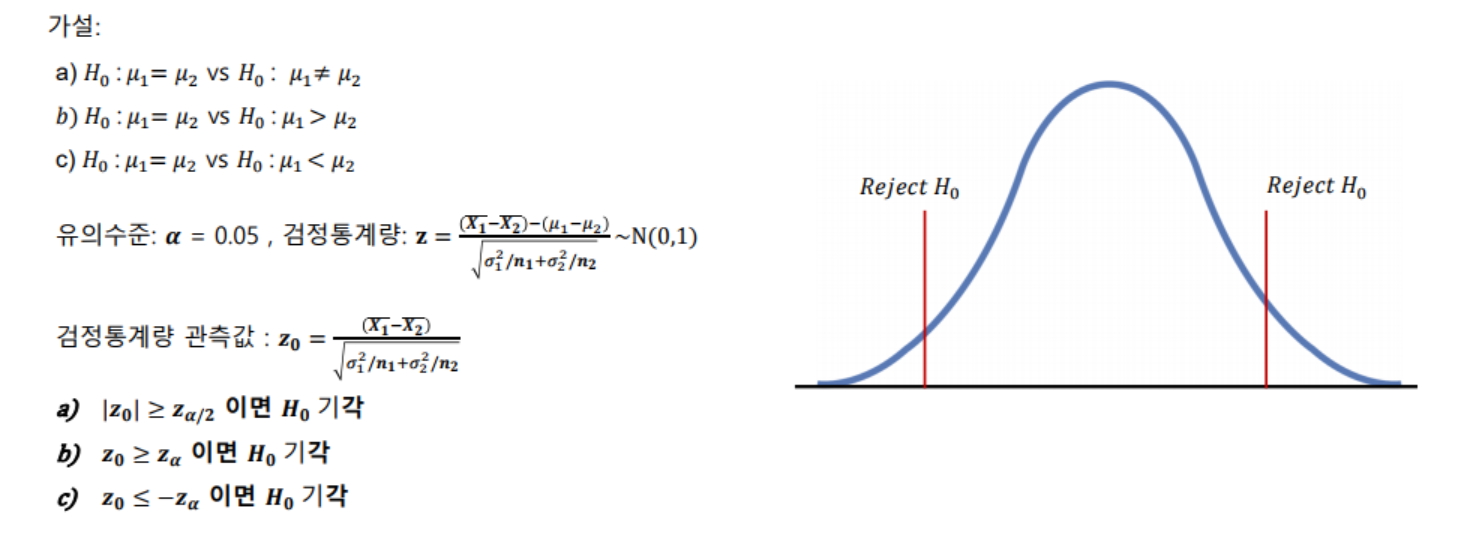
- 검정 방법
- 양측검정(two-side test) : 대립가설의 내용이 같지 않다 또는 차이가 있다 등의 양쪽 방향의 주장
- A백신과 B백신의 코로나 면역력에는 차이가 있다
- A팀과 B팀의 평균 연봉은 차이가 있다
- 단측검정(one-side test) : 한쪽만 검증하는 방식으로 대립가설의 내용이 크다 또는 작다 처럼 한쪽 방향의 주장
- A제품의 수율이 B제품의 수율보다 크다
- A팀의 평균 연봉이 B팀의 평균 연봉보다 크다
- 양측검정(two-side test) : 대립가설의 내용이 같지 않다 또는 차이가 있다 등의 양쪽 방향의 주장
단일 표본에 대한 가설 검정
- 모평균 가설검정 - 모분산을 아는 경우

- 모평균 가설검정 - 모분산을 모르는 경우(소표본)
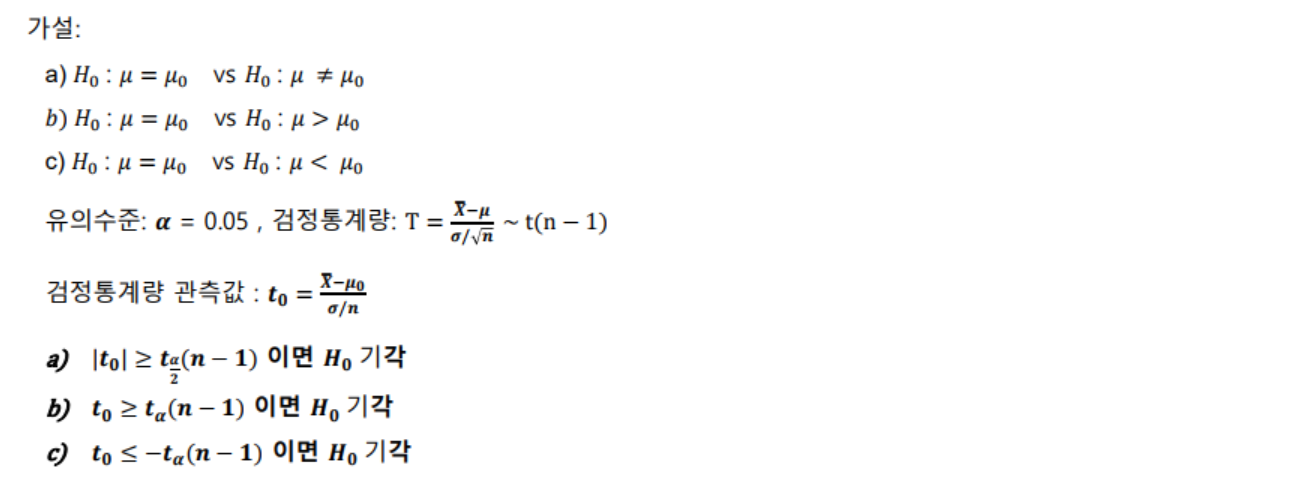
- 모비율 가설검정
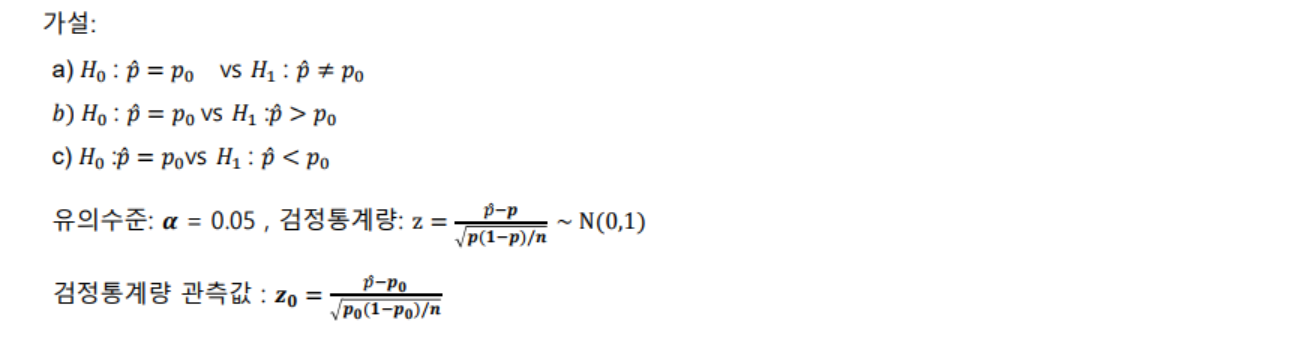
두 표본에 대한 가설 검정
- 대표본 - 모분산을 아는 경우
- 소표본 - 모분산을 모르는 경우

- 대응비교

범주형 자료분석
1. 적합도 검정(goodness of fit test)
- 범주형 자료(categorical data)
- 관측된 결과를 어떤 속성에 따라 몇 개의 범주로 분류 시켜 도수로 주어진 데이터
- 범주형 자료 분석(categorical data analysis)
- 범주형 자료에 대한 통계적 추론 방법
- 범주형 자료 분석은 카이제곱 검정으로 추론함
- t-test 와 카이제곱 검정의 차이
- t-test: 연속형 변수의 차이에 대한 검정
- 명목형 변수에 대한 검정시 카이제곱 검정을 사용
적합도 검정
- 관측된 값들이 추론하는 분포를 따르고 있는지 검정, 한 개의 요인을 대상으로 검정
ex) 멘델의 유전 법칙에 부합하는지 검사하기 위해 테스트할 때, 완두콩의 잡종 비율이 A:B:C = 1:1:2 였다고 가정해 보자. 100개의 콩을 조사한 결과 A가 25 B가 20 C가 55개 였다면 앞선 가정이 맞는지 유의수준 0.05에서 검정해보자 - χ² = ∑( (Oὶ-Eὶ)² / Eὶ ), 자유도 = 범주의 개수 - 1
- O(observed frequency, 관찰 빈도) : 데이터로 부터 수집된 값
- E(expected frequency, 기대 빈도) : 기대값과 비슷한 개념

2. 독립성 검정(test of independence)
- 관측된 값을 두 개의 요인으로 분할하고 각 요인이 다른 요인에 영향을 끼치는지(독립)를 검정
ex) 지지하는 정당과 사는 지역(A,B,C구)은 관련이 있는지 알아보기 위해서 1000명을 뽑아서 조사한 자료가 있을 때, 지지 정당과 사는 지역이 독립인지 유의수준 0.05에서 검정해보자 - 관측된 값을 두 개의 요인으로 분할하고 각 요인이 다른 요인에 영향을 끼치는지(독립)를 검정

3. 동일성 검정(test of homogeneity)
- 서로 다른 세개 이상의 모집단으로 관측된 값들이 범주내에서 동일한 비율을 나타내는지 검정
ex) 남녀의 핸드폰 선호가 동일한지 조시하기 위해서 남자 100명, 여자 200명을 조사하였다. 유의 수준 0.05에서 동일한지 조사하여라

- 서로 다른 모집단에서 관측된 값들이 범주내에서 동일한 비율을 나타내는지 검정

상관분석
- 상관관계(correlation coefficient)
- 두 변수간의 함수 관계가 선형적인 관계가 있는지 파악할 수 있는 측도가 상관계수 임
vwx y,z) - ρ = Corr(X,Y) = Cov(X,Y) / √Var(X)√Var(Y)
- 두 변수간의 함수 관계가 선형적인 관계가 있는지 파악할 수 있는 측도가 상관계수 임
- 상관계수 : −1 ≤ ρ ≤1
- 상관계수가 1에 가까울 수록 양의 상관계가 강함
- 상관계수가 -1에 가까울 수록 음의 상관관계가 강함
- 상관계수가 0에 가까울 수록 두 변수 간의 상관관계가 존재하지 않음
- 상관계수가 0이라는 것은 두 변수 간에 선형 관계가 존재 하지 않는 다는 것임
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
