
시작하며
NLP 능력을 갈고닦아 나만의 뾰족한 Skill을 키우고 싶었습니다. 그래서 이번 Wanted Free/Pre Onboarding AI/ML Course 에 참가했습니다! 본 과정을 진행하면서 Pytorch 프레임워크에 대한 능력을 키우고 Modeling, API 서버 구현을 경험하고 공유할 예정입니다.
NLP
NLP(Natural Language Processing)는 사람의 언어를 컴퓨터가 이해하고 생성하는 인공지능의 한 분야입니다. 크게 NLU와 NLG로 카테고리가 분류됩니다. NLU(Natural Language Understanding)는 문장의 의미, 의도를 이해하는 자연어처리 영역입니다. NLG(Natural Language Generation)는 자연어를 컴퓨터가 직접 생성하는 자연어처리 영역입니다.
NLP Task
감정분석, 스토리 생성, 형태소 분석 등등의 태스크가 있습니다. 그 중 Word Embedding, Text Generation에 대해 다뤄보도록 하겠습니다.
Word Embedding
기계 학습 모델은 숫자, 벡터로 된 정보를 읽고 받아들일 수 있습니다. 텍스트 문자를 컴퓨터가 이해할 수 있는 숫자로 변환할 때 우리는 워드 임베딩(Word Embedding)을 사용합니다. 이 워드 임베딩은 유사한 단어가 유사한 인코딩 값을 가질 수 있도록 차원에 매핑합니다.
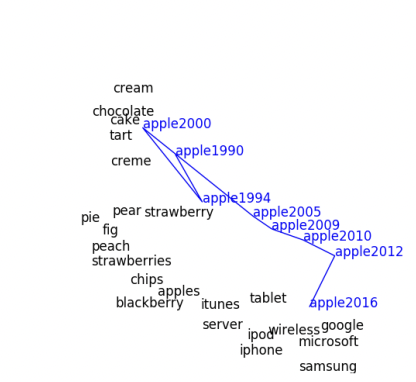
가장 유명한 워드 임베딩 모델은 Word2Vec입니다. 분산 표현을 사용하여 각 단어 간의 의미를 고려해 적절하게 차원에 분포시킵니다. Word2Vec 학습방식은 크게 CBOW와 Skip-gram이 있습니다. CBOW는 주변에 있는 단어를 정보로 중간에 들어갈 단어를 예측하는 방식으로 학습합니다. 그와 반대로 Skip-gram은 중간에 들어있는 단어를 정보로 주변에 있는 단어를 예측하는 방식으로 학습해 나갑니다.

단어 및 문장 텍스트로 이루어진 데이터셋을 학습시켜 볼 수 있습니다. 예를 들어, 영어 매체 감상평에 대한 워드맵을 구성하고 싶다면, IMDb를 활용할 수 있습니다. 영화 후기를 포함한 데이터로 감상평과 제목, 언어, 장르 정보를 제공합니다.
Text Generation
사람이 쓰는 언어를 흉내내어 기계가 직접 텍스트를 생성할 때 사용됩니다. 주어진 정보를 활용하여 새로운 정보를 유추하여 단어 및 문장을 완성하는 방식으로 작동됩니다. 자동완성, 스토리 생성, 캡션 생성 등 다양하게 응용될 수 있습니다.
문장을 기반으로 스토리를 생성하고 싶은 경우에 GPT-2(Generative Pre-trained Transformer 2)모델을 사용할 수 있습니다. '생성적 사전 학습 변환기'라는 뜻이 있는 GPT-2는 2015년 설립된 인공지능 연구소 OpenAI에서 만든 언어모델입니다. 번역, 챗봇 대화에서 우수한 성능을 보이지만 특히 작문 면에서 사람이 쓴 글과 구별이 어려울 정도로 높은 성능을 보이는 자연어 모델입니다. 위 모델 또한 자유롭게 단어 및 문장 텍스트로 이루어진 데이터셋을 선정하여 Fine-Tuning 할 수 있습니다.

캡션 생성을 하고 싶다면, COCO Captions라는 Dataset을 활용할 수 있습니다. 330,000개의 캡션이 있는 이미지로 이루어진 데이터셋입니다. 각 이미지를 설명하는 텍스트를 생성하는 캡션 생성에 쓰일 수 있습니다.
이미지 출처

4개의 댓글


저도 워드임베딩 분야를 더 깊이 공부해보려고 합니다! Word2Vec과 FastText 모두 공부해서 다양하게 활용할 줄 아는 역량을 길러야 할 것 같아요! 글 잘 읽었습니다 :)

좋은글 감사합니다