
NLP의 한 분야 NLG(Natural Language Generation)의 Text Expansion Task에 대해 알아보겠습니다.
Text Expansion
주요한 키워드를 주어 기계가 자동으로 자연어 문장을 생성합니다. 짧은 제목 문장을 생성할 때 또는 키워드만으로 에세이를 작성하고 싶을 때 사용할 수 있습니다. 모델이 학습한 정보로 키워드에 걸맞은 조사, 부사, 형용사를 활용해 문장을 완성합니다.
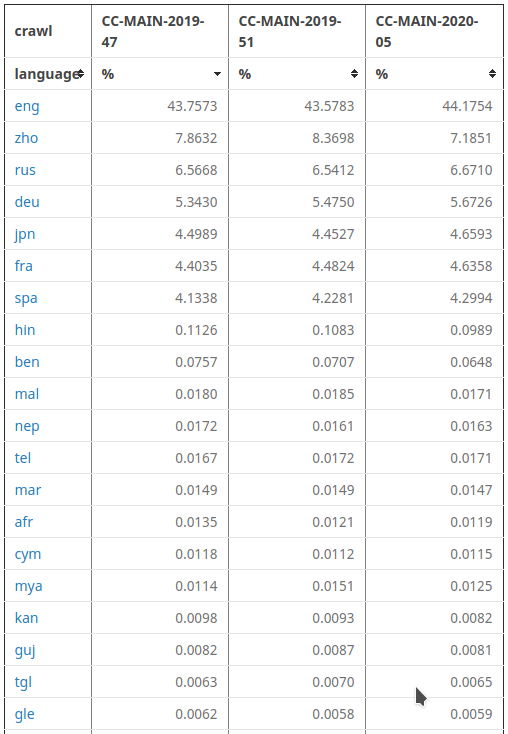
Common Crawl
대표적인 데이터셋으로는 GPT를 학습시킨 Common Crawl이 있습니다. 12년 동안 인터넷 웹페이지에서 Text Corpus를 크롤링한 페타바이트 데이터셋입니다. 다양한 언어의 텍스트 데이터로 이루어져 있습니다. AWS(아마존 웹 서비스)의 퍼블릭 테이터셋 그리고 다양한 아카데미 클라우드 플랫폼에서 제공합니다.
BART
Seq 2 Seq모델을 사전훈련하기 위한 Denoising Encoder 모델입니다. 이 모델은 일반적인 Tranformer-based Neural Machine Translation Architecture를 사용합니다. 작동방식은 두 개의 단계로 구성됩니다. (1) 임의의 노이즈 함수로 텍스트를 손상하고 (2) 원본 텍스트를 재구성하는 모델을 학습하여 학습됩니다.
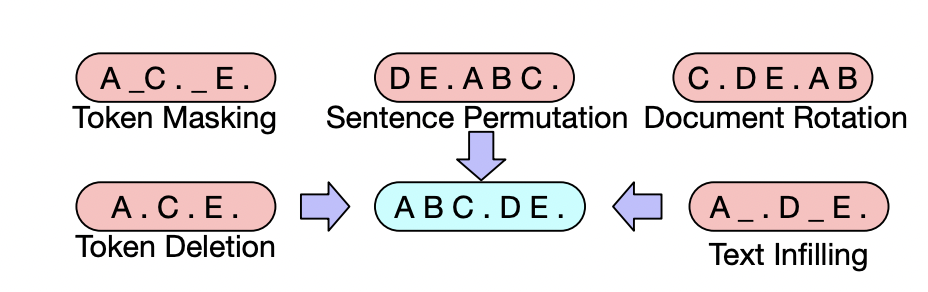
위 사진과 같이 텍스트 토큰을 마스킹하거나, 문장의 변형, 토큰 삭제 등의 방식으로 임의의 노이즈를 주어 텍스트를 손상합니다. 이러한 방식으로 재구성하여 모델을 학습하게 됩니다.
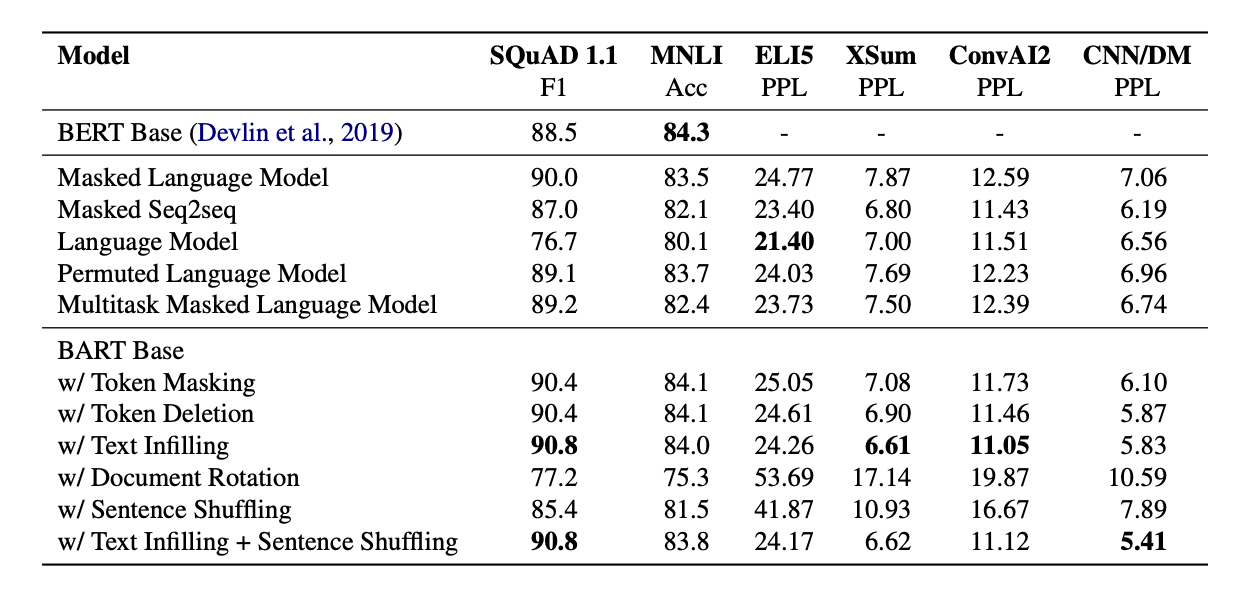
일반적인 BERT 기반 모델보다 BART 기반 모델이 대체로 더 좋은 성능을 내는 것을 확인할 수 있습니다.
LeakGAN
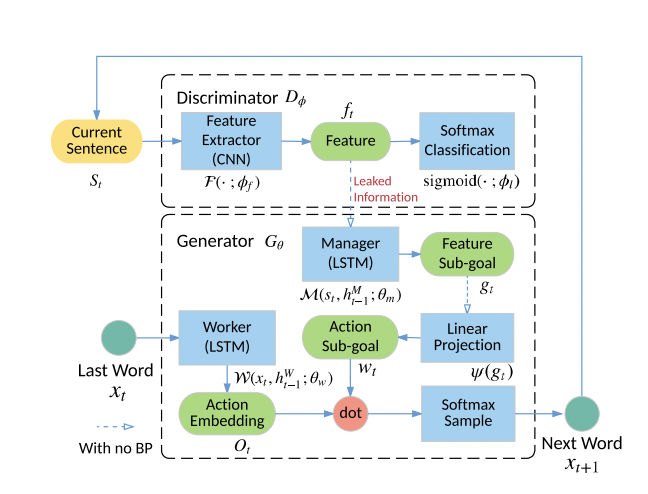
GAN(Generative Adversarial Nets)을 텍스트 생성에 적용한 모델입니다. 기존에는 Scala Guiding Signal 문제로 20단어 내외의 짧은 문장만 생성할 수 있었습니다. 이 LeakGAN은 더 긴 텍스트를 제너레이팅하여 그 문제를 해결하기 위해 만들어졌습니다. 사람의 수동 감독 없이 LeakGAN은 Manager와 Worker 간의 상호 작용을 통해서 문장 구조를 학습할 수 있다는 장점이 있습니다.

좋은 글 감사합니다