한글 형태소 분석기의 필요성
ElasticSearch를 사용하면서 한글 형태소 분석기가 왜 필요한지에 대해 먼저 알아봅시다.
비교하기
앞서 작성한 글에서 역색인(인덱스)에 대해서 언급했습니다.
이 파트에서는 토크나이저에 따라 문장이 어떤 토큰들로 나뉘는지를 확인해보겠습니다.
Standard
Standard는 ElasticSearch에서 기본 제공하는 토크나이저입니다.
GET _analyze { "tokenizer": "standard", "text": ["격리수준에 대해 알고 계신가요?"] }{ "tokens": [ {"token": "격리수준에", ...}, {"token": "대해", ...}, {"token": "알고", ...}, {"token": "계신가요", ...} ] }
Nori
Nori는 한글 형태소 분석을 지원하는 토크나이저입니다.
(Nori는 추가적인 설치가 필요합니다. 밑에서 다룹니다.)GET _analyze { "tokenizer": "nori_tokenizer", "text": ["격리수준에 대해 알고 계신가요?"] }{ "tokens": [ {"token": "격리", ... }, {"token": "수준", ... }, {"token": "에", ...}, {"token": "대하", ...}, {"token": "아", ...}, {"token": "알", ...}, {"token": "고", ...}, {"token": "계시", ...}, {"token": "ᆫ가요", ... } ] }
ES 색인(저장)과정
여기서는 ElasticSearch의 색인 과정에 대해 자세히 알아보겠습니다.
ElastcisSearch는 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현한다.
ES에 저장되는 도큐먼트는 모든 문자열 필드별로 역 인덱스를 생성하는데, 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리과정을 거칩니다.
과정 자세히 살펴보기
색인 과정은 크게 3단계로 나눌 수 있는데 각 과정이 어떤 역할을 하는지 살펴봅시다.
캐릭터 필터 -> 토크나이저 -> 토큰필터
이 전체과정을 텍스트 분석(Text Analysis)이라고 하고, 이 과정을 처리하는 기능을 애널라이저(Analyzer)라고 합니다.
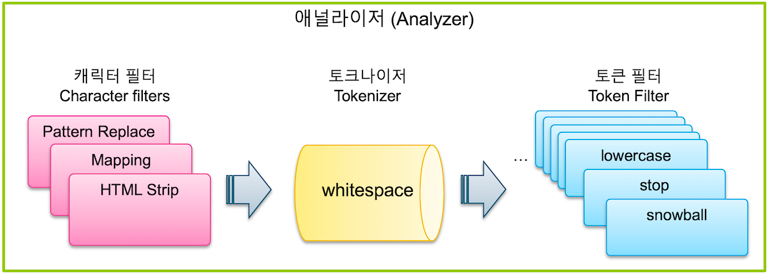
캐릭터 필터
예시 : 힌두-아랍 숫자(٠١٢٣٤٥٦٧٨٩) -> 아랍어-라틴 숫자(0123456789), HTML 요소와 제거 등등
역할 : 문자열을 수신하고 문자를 추가, 제거 또는 변경하여 스트림을 변환
개수 : 0개 이상
토크나이저
예시 : 격리수준 -> 격리/수준, Brown Fox -> Brown/Fox
역할 : 문자열을 받아서 개별 토큰으로 나누고 토큰 스트림을 출력하고, 각 용어의 순서나 위치, 문자 오프셋을 기록
개수 : 반드시 하나!
토큰 필터
예시 : Brown -> brown(lowercase 필터-소문자변환), aws == amazon(synonym 필터-동의어), jumps, jumping -> jump
역할 : 분리된 토큰들을 가공 (각 토큰의 위치나 문자 오프셋을 변경할 수 없음)
개수 : 0개 이상
내용 출처
https://esbook.kimjmin.net/06-text-analysis
https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer-anatomy.html
ElasticSearch Nori 설치 (with Docker)
# ElasticSearch container 확인
docker ps
# ElasticSearch 컨테이너 접속
docker exec -it <container_id> /bin/bash
# 설치
bin/elasticsearch-plugin install analysis-nori
# 재시작
docker restart <container_id>설치된 Nori로 문자 분석하기
[GET] http://localhost:9200/_analyze
{
// 3가지 중 하나 선택
// "analyzer": "standard", // 1
// "analyzer": "nori", // 2
"tokenizer": "nori_tokenizer", // 3
"text": "동해물과 백두산이"
}결과
"analyzer": "standard": 동해물과/백두산이
"analyzer": "nori": 동해/물/백두/산
"tokenizer": "nori_tokenizer": 동해/물/과/백두/산/이