V3 - 좀 더 복잡한 엔티티 다루기
이 글에서는 기존 Product 엔티티를 좀 더 복잡하게 만들어 볼 것이다.
그림과 같이 상품에 태그를 달아줘보자.

DB - 상품 태그 추가
다음 엔티티들을 추가해준다. (BaseTimeEntity는 이전 글에서 다뤘다.)
@Data
@Entity
@NoArgsConstructor
public class ProductV3 extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private int price;
private int stock;
private String name;
public ProductV3(int price, int stock, String name) {
this.price = price;
this.stock = stock;
this.name = name;
}
public void buy() {
stock--;
}
}@Data
@Entity
@NoArgsConstructor
public class TagV3 {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true)
private String tagName;
public TagV3(String tagName) {
this.tagName = tagName;
}
}@Data
@Entity
@NoArgsConstructor
public class ProductTagV3 {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "product_id")
private ProductV3 product;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "tag_id")
private TagV3 tag;
}DB에서는 제품에 태그를 달 준비를 마쳤다.
제품에 태그를 달아주는 컨트롤러와 서비스 코드는 생략하겠다.
궁금하다면 상위에 링크로 달아둔 관련 코드를 확인하자.
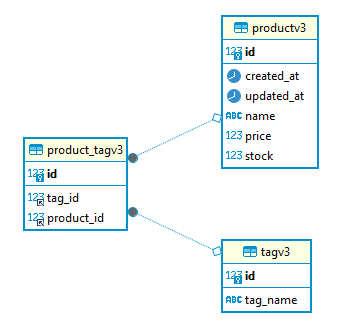
loststash 구성 (실패함)
V2에서는 Product 테이블의 데이터를 가져와서 단순했지만,
V3에서는 Product-ProductTag-Tag 테이블을 조인해서 가져온 후에 해당 데이터를 종합해야 한다.
만약 1번 상품에 2개의 태그가 있다면 쿼리 결과는 다음과 같을 것이다.

하리보 젤리 201 상품과 관련된 태그 이름들은 {하리보, 캔디류}이다.
2개의 ROW로 결과가 나오지만 하나의 문서로 만들어 주어야 한다.
즉 여러 태그 정보를 하나의 Product 문서의 nested 필드로 들어갈 수 있도록 종합해주어야 한다.
logstash 처리과정
DB에서 가져온 후 product_id 별로 가져온 데이터를 모을 것이다. 마지막으로 종합된 데이터를 ES로 밀어 넣을 것이다.
우리가 설정할 logstash.conf
input -> DB에서 데이터 가져오기
filter -> 가져온 데이터를product_id별로 종합하기
output -> 종합된 데이터 ES로 밀어넣기
logstash.conf 구성 변경
product_v2와 product_v3로 나눴다.
input과 output은 V2와 구성이 크게 바뀌진 않았다.
product_id별로 종합하기 위한 filter의 aggregate 플러그인을 사용했다.
하지만 결과적으로 product_v3에 대한 처리는 실패했다.
input {
# v2 설정
jdbc {
type => "product_v2"
...
}
# v3 설정
jdbc {
type => "product_v3"
jdbc_driver_library => "${JDBC_DRIVER_PATH}"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://${MYSQL_HOST}:${MYSQL_PORT}/${MYSQL_DB}"
jdbc_user => "${MYSQL_USER}"
jdbc_password => "${MYSQL_PASSWORD}"
schedule => "*/30 * * * * *"
statement => "
SELECT p.id as product_id, p.price, p.stock, p.name, p.created_at, p.updated_at, t.id as tag_id, t.tag_name
FROM productv3 p
LEFT JOIN product_tagv3 pt ON p.id = pt.product_id
LEFT JOIN tagv3 t ON pt.tag_id = t.id
WHERE updated_at > :sql_last_value
"
}
}
filter {
if [type] == "product_v3" { # 데이터 타입이 product_v3일 경우에만 처리
aggregate {
task_id => "%{product_id}" # product_id를 기준으로 데이터를 그룹화
code => "
# product_id로 그룹화된 데이터를 설정합니다
map['id'] = event.get('product_id')
map['price'] = event.get('price')
map['stock'] = event.get('stock')
map['name'] = event.get('name')
map['createdAt'] = event.get('created_at')
map['updatedAt'] = event.get('updated_at')
# tagInfoV3 배열을 초기화하거나 기존 배열을 사용합니다
map['tagInfoV3'] ||= []
# tag_id와 tag_name을 tagInfoV3 배열에 추가합니다
if event.get('tag_id') != nil
map['tagInfoV3'] << {'id' => event.get('tag_id'), 'tag_name' => event.get('tag_name')}
end
logger.info('Aggregated event: ', map)
event.cancel()
"
push_map_as_event_on_timeout => true # 이전 map을 최종 이벤트로 푸시
timeout => 20 # 3초 동안 그룹화를 유지
}
}
}
output {
if [type] == "product_v2" {
elasticsearch {
hosts => ["http://es01:9200"]
index => "product_v2"
document_id => "%{id}"
user => "elastic"
password => "changeme"
}
}
if [type] == "product_v3" {
stdout { codec => rubydebug } # output 결과를 확인하기 위한 로그
elasticsearch {
hosts => ["http://es01:9200"]
index => "product_v3"
document_id => "%{id}"
user => "elastic"
password => "changeme"
}
}
}
aggregate : event와 map
aggregate에서 event와 map을 다루는데 다음 그림과 같이 처리되는 것이다.
쿼리 결과에서 각각의 ROW가 이벤트가 되고,
map을 통해서 이 event(row)결과를 처리하고 누적시킨 후에 보내는 것이다.
event.close() 코드가 있는 이유도 Tag 정보를 누적시킨 후 ES로 보내기 위함이다.
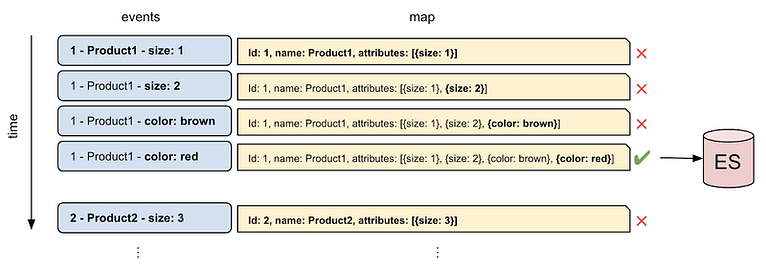
event를 누적시키지 않고 바로 ES로 밀어넣으면 앞서 든 예시와 같이 하나의 Product에 대한 정보가 중복으로 들어가게 된다.

실패한 이유가 무엇일까?
event.cancel()을 주석처리하면 각각의 쿼리 row가 output으로 나온다.
하지만
event.cancel()의 주석을 해제하면 product_id를 기준으로 tag 정보가 집계가 되지만 output쪽으로 데이터가 나가지 않는다.
나는 누적된 map정보가 push_map_as_event_on_timeout을 설정으로 푸시되지 않는 것 같다고 생각했다.
이것을 해결할 방법을 아직 찾지 못했다.
언제까지나 이제 막 기술을 접한 사람의 추측이기 때문에 해결방법을 알고 계신다면 댓글을 남겨주시면 감사하겠습니다.
스프링 스케줄러 활용
그래서 정말 단순하게 가기로 했다.
스프링 스케줄러를 통해서 30초마다 전체 데이터를 다시 저장해주기로 했다.
스프링 메인 클래스에 @EnableScheduling를 추가해주고 다음 스케줄러를 구성했다.
@Slf4j
@Service
@RequiredArgsConstructor
public class ProductInfoScheduler {
private final ProductTagSyncRepository productTagSyncRepository;
private final ProductSearchV3Repository searchRepository;
@Scheduled(cron = "*/30 * * * * *")
public void sync() {
log.info("Start Syncing - {}", LocalDateTime.now());
List<ProductInfoV3> all = productTagSyncRepository.findAll();
searchRepository.saveAll(all);
}
}ProductTagSyncRepository와 ProductV3Repository 코드는 링크를 달아둔다.
단순히 Product-ProductTag-Tag 정보를 다 가져오고 Document로 변환하는 코드이기 때문에 알아서 구현하면 된다.
JPA N+1, multiplebagfetchexception을 피하기 위해서
LEFT 조인으로 Product_Tag만 가져오고 LAZY 로딩으로 변환하는 방식으로 진행했다.
그래서jpa.properties.hibernate.default_batch_fetch_size=100를 추가해줬다.
참고하면 좋을 내용
https://www.youtube.com/watch?v=fBfUr_8Pq8A&t=1667s
위 영상은 NHN에서 ElasticSearch 데이터 색인을 위해 사용하는 방법과 검색 최적화를 위한 방법을 다루고 있다.
NHN은 2가지 방식을 병행한다.
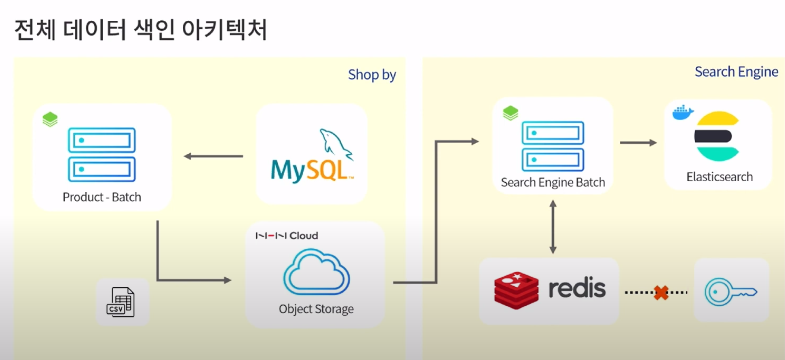
전체 데이터 색인
매일 정해진 시간에 새로운 인덱스를 생성하고 기존 사용중이던 인덱스를 백업용으로 보관하는 작업 (ES - Aliases 활용)
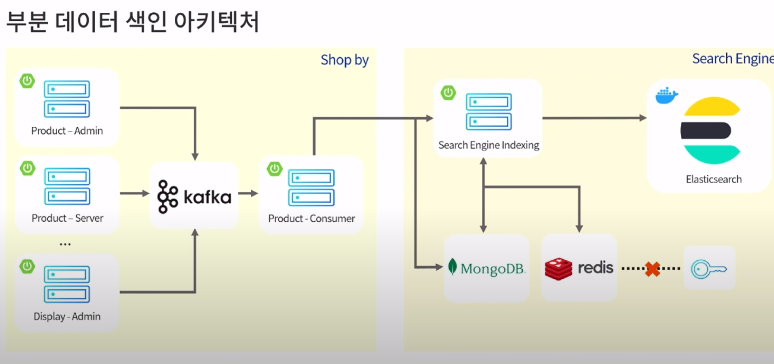
부분 데이터 색인
이미 색인된 데이터를 최신화 데이터로 재색인해주는 작업
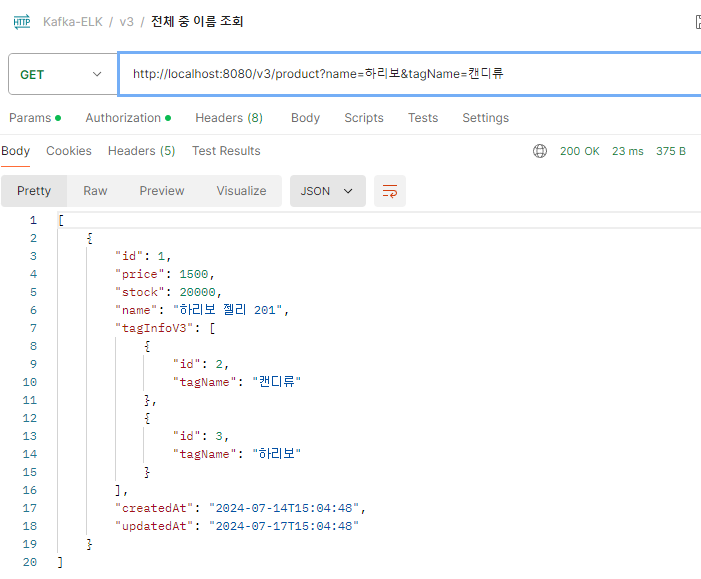
결과
레포지토리를 다음과 같이 구현하고 검색해본다.
@Repository
public interface ProductSearchV3Repository extends ElasticsearchRepository<ProductInfoV3, Long> {
@Query("""
{
"bool": {
"must": [ {"match": {"name": "?0"}} ]
}
}
""")
List<ProductInfoV3> findWithName(String name);
@Query("""
{
"nested": {
"path": "tag_info_v3",
"query": {
"bool": { "must": [{"match": {"tag_info_v3.tag_name": "?0"}} ] }
}
}
}
""")
List<ProductInfoV3> findWithTagName(String tagName);
@Query("""
{
"bool": {
"must": [
{
"bool": {
"must": [ {"match": {"name": "?0"}} ]
}
},
{
"nested": {
"path": "tag_info_v3",
"query": {
"bool": { "must": [{"match": {"tag_info_v3.tag_name": "?1"}} ] }
}
}
}
]
}
}
""")
List<ProductInfoV3> findWithNameAndTagName(String name, String tagName);
}TagName 검색 결과
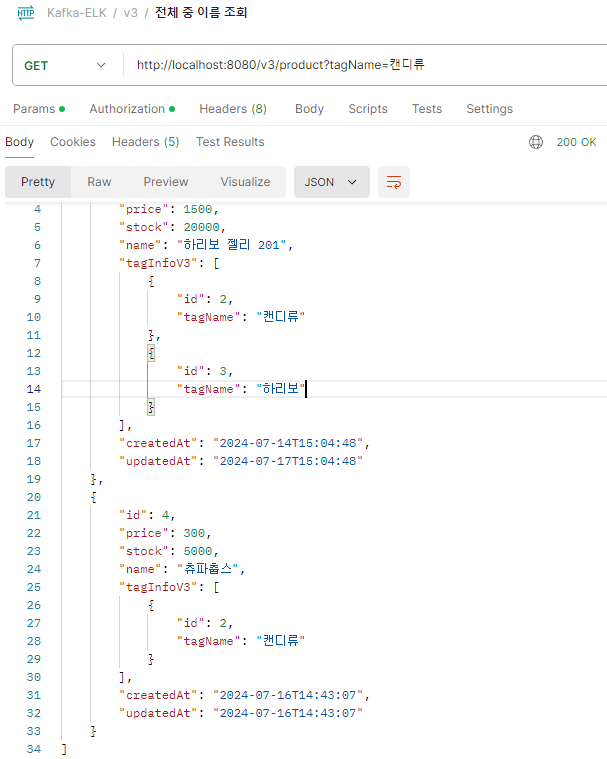
ProductName & TagName 검색 결과