6주차 과제는 Deep learning Tutorial, Prevent overfit으로 오버피팅을 방지해보는 과제를 해보았다.
데이터는 10개의 범주(category)와 70000개의 흑백 이미지로 구성된 패션 MNIST 데이터셋을 사용한다.
-
One - hot encoding을 진행하고 기본 모델을 생성한다.
-
비교해볼 요인을 위해 Regularizer과 Dropout만을 진행한다.
-
Regularizer
-
Dropout
-
overfitting은 없어졌으나 performance가 좋아지지 않았다.
underfitting에 가까운 상황이었기 때문이다.
이번 7주차에는 가중치 초기화( weight initialization )에 대해 배운다.
일반적으로 신경망 구조에서 output값의 오차를 구한 다음 그 값을 이용하여 역전파 ( back propagation )를 진행하여 가중치( W )를 업데이트 한다.
주로 경사하강법 ( Gradient Descent )를 진행하여 업데이트 하며 이때 가중치들을 편미분하여 진행한다.
하지만 때론 진행과정 중에 gradient 값이 점점 작아져서 경사 소실 ( vanishing gradient )되는 현상이 발생한다. 또한 반대의 경우인 경사 폭발 ( exploding gradient )과정도 발생하는데 이러한 경우들에는 학습이 제대로 이루어지지 않는다.
따라서 학습 전에 가중치들을 적절한 값으로 초기화시키는 것이 중요한데 이때 가중치 초기값을 아주 작은 값으로 설정하는 것이 좋다. 또한 무작정 작은 난수로 설정하는 법은 심층 신경망 ( DNN )에서 적합하지 않다.
이와 같은 문제를 해결하기 위해 첫번째 방법으로 Xavier Initailization 방법이 있다.
이 방법은 glorot initialization이라고도 부르며 보편적으로 잘 수행되며 현재는 fan-in과 fan-out을 모두 고려하는 방식을 선택하고 있다.
- fan-in : 들어오는 layer의 unit 개수
- fan-out : 현재 layer의 unit 개수
또 다른 방식으로는 He Initialization이 있는데 이 방법은 fan-in만 고려하며 ReLU계열에 특화된 방식이다.
data의 형태에 따라 다르므로 두 가지 방식 다 사용해보고 결정을 하면된다.
Xavier Initialization ( glorot_normal )
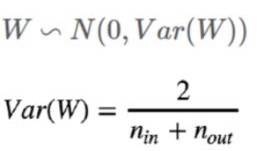
Xavier Initialization ( glorot_uniform )
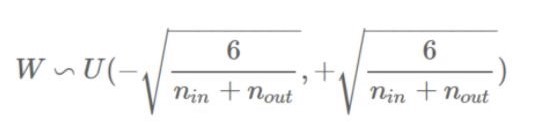
He Initialization ( He_normal )
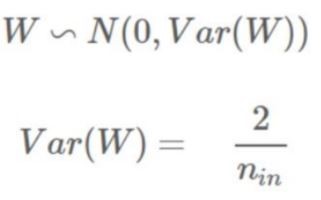
He Initialization ( He_uniform )
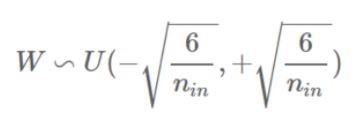
Optimizer
-
learning rate 에 따른 train loss변화
-
SGD
SGD
: random 하게 추출한 mini - batch씩 gradient descent 진행한다.
batch size = mini - batch size
단점 : 해당 위치에서의 gradient만 고려한다.
gradient dimension 별로 차이가 크면 minimum을 찾기 어렵다.
local minimum or plateaus => gradient descent 멈춘다.
해결책 : 관성
gradient에 관성을 주는 경우
learning rate에 관성을 주는 경우
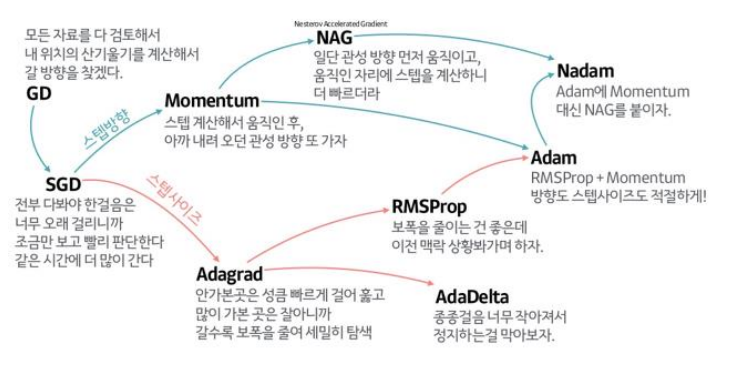
Gradient 계보
- SGD + momentum
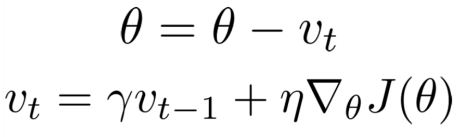
gradient (dW) 방향으로 가야할 게 velocity ( v_(t-1))의 영향을 받아 actual step ( momentum 방식의 gradient ) 으로 간다.
- NAG ( Nesterov Accelerated Gradient )
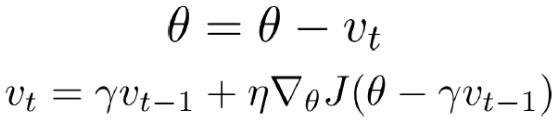
momentum 방향으로 갔을 때 예상되는 지점의 gradient를 사용한다.
그래서 더 converge 잘 되고 minimum도 더 잘 찾음.
learning rate ( step size ) 계보
- Adagrad ( Adaptive Gradient )
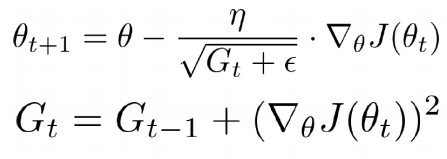
G_(t-1)에 저장된 이전 속력이 계속 빨랐다면 learning rate를 나눠서 속력을 낮춘다.
G_(t-1)에 저장된 이전 속력이 계속 느렸다면 learning rate를 나눠서 속력을 가속화한다.
- Rmsprop ( Root Mean Squared Prop )
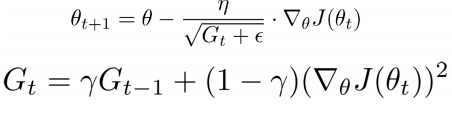
인접한 속력의 영향력을 더 받아서 이전의 속력이 큰 것 때문에 step size가 0에 가까워 지는 걸 방지.
- Adam ( Adaptive Moment Estimation )
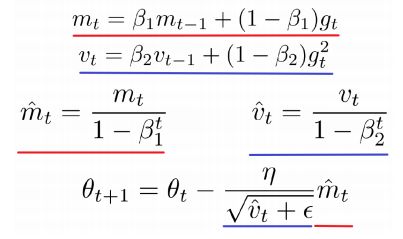
step size와 step direction 모두 관성을 부여했다.
대체적으로 성능이 좋다.
학습이 진행될수록 learning rate가 작아져서 bad learning rate에 converge 할 수 있는데 이 감소를 rectified하게 만드는 방법
대체적으로 Adam이 좋지만 data마다 optimizer가 다릅니다.
가능 한 다 사용한 후 판단...
