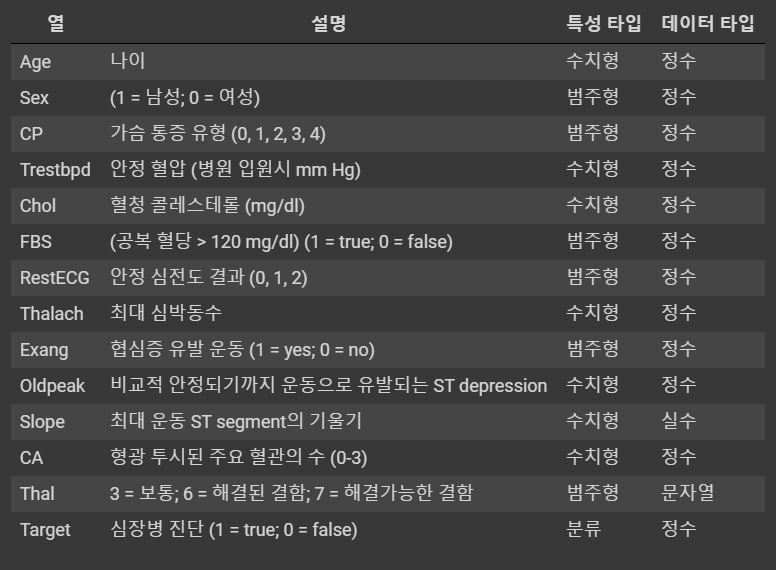
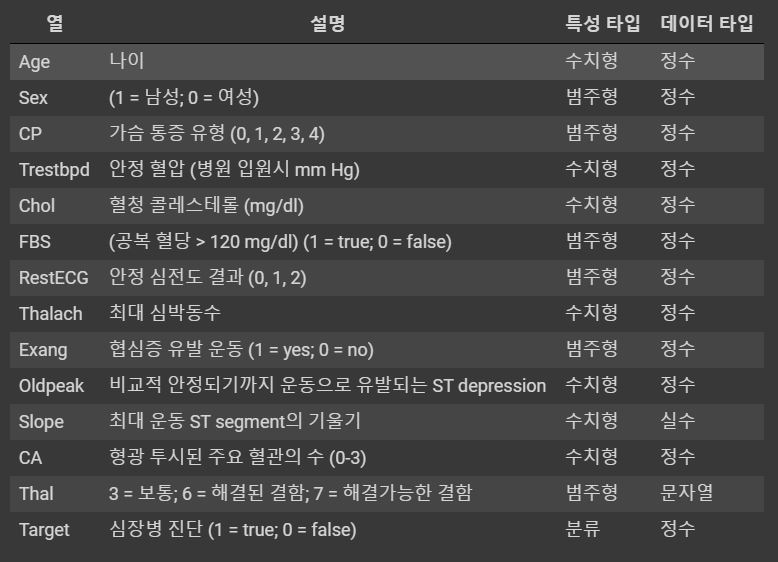
7주차 과제에서는 Normalization, Standardization, Initialization, optimization을 하는 법을 배운다.
Dataset으로는 클리블랜드의 심장병 재단에서 제공한 작은 데이터셋을 쓰며 환자의 심장별 발병 여부를 예측해본다.
1
from sklearn.preprocessing import StandardScaler이후 인스턴스 시키고 fit_transform메서드를 이용해 standardization하고 저장한다.
2
from sklearn.preprocessing import MinMaxScaler위와 같이 실행한다.
3
from tensorflow.keras.optimizers import SGD
sgd = SGD(learning_rate=0.001, momentum=0.9)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def create_momentum_model():
model = Sequential()
### START CODE HERE ### (≈ 1 line of code)
model.add(Dense(units = 32, input_dim = 12, activation = 'relu'))
### END CODE HERE ###
model.add(Dense(64, activation = 'relu'))
### START CODE HERE ### (≈ 1 line of code)
model.add(Dense(units = 1, activation = 'sigmoid'))
### END CODE HERE ###
### START CODE HERE ### (≈ 1 line of code)
model.compile(optimizer = sgd, metrics = ['accuracy'], loss = 'binary_crossentropy' )
### END CODE HERE ###
return model이후 epoch=10, batch_size=1로 실행
4
from tensorflow.keras.datasets import fashion_mnist
(x,y), (x_test, y_test) = fashion_mnist.load_data()
from tensorflow.keras.utils import to_categorical
x = x.astype('float32')
x_test = x_test.astype('float32')
x = x.reshape(60000,-1)
x_test = x_test.reshape(10000,-1)
x = x/255.
x_test = x/ 255.
y = to_categorical(y, 10)
y_test = to_categorical(y_test, 10)
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x, y, train_size = 1/2, random_state = 3, stratify=y)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def create_hn_model():
model = Sequential()
### START CODE HERE ### (≈ 4 line of code)
model.add(Dense(64, input_shape=(784,), activation = 'relu',kernel_initializer = 'he_normal'))
model.add(Dense(128, activation = 'relu',kernel_initializer = 'he_normal'))
model.add(Dense(256, activation = 'relu',kernel_initializer = 'he_normal'))
model.add(Dense(10, activation = 'softmax', kernel_initializer = 'he_normal'))
### END CODE HERE ###
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
return modelhe_normal의 효과를 볼 수 있었다.
이번 8주차에서는 CNN을 본격 시작하게 되었다.
CNN ( Convolutional Neural Network )
CNN은 분야에 상관없이 어디에나 적용 가능하므로 꼭 배울 필요가 있습니다!
사람의 뇌를 예로 들어 내린 결론 3가지
-
특정 feature를 detect하는 뉴런이 필요하다.
-
인접 feature를 detect하는 뉴런이 필요하다.
-
feature를 계층적으로 학습할 필요가 있다.
Fully - Connected Layer
-
필요한 정보만
-
조금 씩 읽자
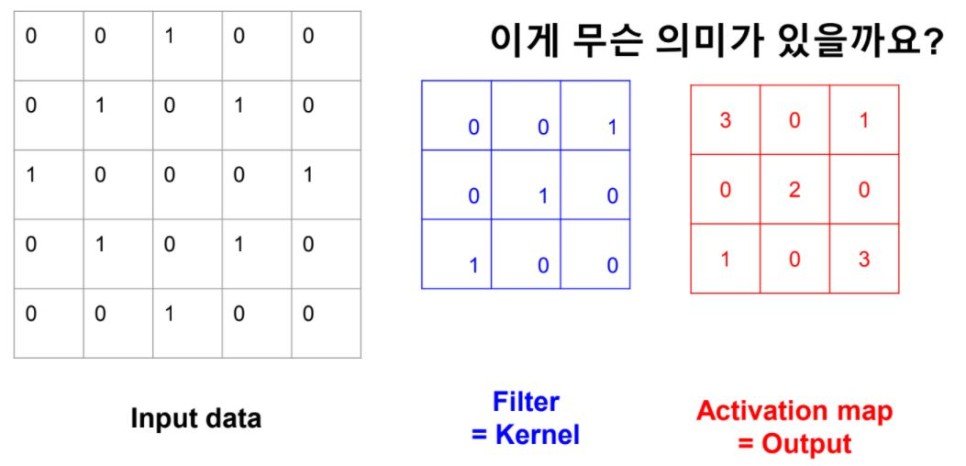
- 모든 pixel간의 feature 추출로 비효율적
locally - connected한 feature추출
- 물체가 이동하면 인식하지 못함
convolution filter는 움직이면서 feature를 추출한다.
용어정리
- input data
2.filter = kernel = window
filter 모양의 feature 추출
filter 개수가 많을수록 더 다양한 feature 추출
- activation map = feature map
filter가 찾은 특성이 얼마나 있는지 압축해서 표현 ( 지도처럼 압축해놓았다. )
filter 개수 = output activation map의 depth
Hyperparameter
- kernel_size
홀수를 쓰는 것이 기본
대부분 3X3을 사용 ( 5X5, 7X7 )
- filters = kernel의 개수
자기맘대로 (Dense layer에서 unit 개수와 유사)
많을 수록 더 많은 feature뽑지만 overfitting 위험
- kernel_size를 홀수를 쓰는 이유
현재 위치 pixel에서의 가로세로 대칭만큼과의 관계를 파악하는 것이 목적
어느 pixel에서 conv 사용했는지 1:1 연결이 불가
padding을 사용할 때 비대칭으로 padding을 사용하게 된다.
padding
: output size가 줄어드는 것을 막기 위해 input data의 외곽을 특정 값으로 덧대준다.
edge 부근의 feature도 잘 추출할 수 있다.
일부를 0으로 해서 원래의 feature를 희석하니 overfititing 방지하는 효과도 일부 있다.
(Dropout도 일부 node가 0이되면서 overfitting 막았다.)
- valid(default)
padding을 주지 않는다.
- same
padding으로 output size와 input size가 같게끔 만든다. ( depth를 제외하고 )
pooling - maxpooling
: 설정한 pool_size 안에서 가장 큰 값으로 downsampling
-
downsmapling 해야 deeper layer에서 더 많은 영역의 정보를 담을 수 있다.
-
parameter 개수가 많아지는걸 막는다.
-
maxpooling layer는 parameter가 있는 layer가 아니다.
-
1,2 번의 이유로 overfitting 방지효과가 있다.


