5주차 과제 리뷰를 해본다
과제의 내용은 keras.dataset인 mnist 데이터를 가지고 train_test_split을 해보는거와 add메서드를 이용한 Sequential modeling이다
과제의 내용에 이어서
Data preprocess
data를 딥러닝 모델 안에 넣고 잘 train 될 수 있게 하는 모든 행위를 의미
-
tensorflow 는 기본적으로 'float32'를 사용해서 혹시 모를 error를 방지해 astype함수를 사용해서 변환한다.
-
normalization
-
flatten : Dense layer는 vector는 ( 1D-array )만 input으로 받을 수 있어서 3D-array로 flatten하는 과정
-
one-hot encoding
one-hot encoding
: 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
loss 선택
: one-hot encoding을 한 경우 : 'sparse_categorical_crossentropy
: one-hot encoding을 안 한 경우 : 'categorical_crossentropy
자연어처리의 기본 전처리 방식
모델의 학습과정 설정 ( compile )
3가지 argument
-
optimizer
-
loss 설정
-
metrics ( 평가 지표 )
모델 학습 ( fit )
기본 parameter
- x : feature = input
- y : label
- epochs ( 전체 training data를 train하는 횟수 )
- verbose : train 할 때 표시되는 bar ( 보통 1을 사용 )
- validation_split : ( 0~1 사이의 float )
- validation_data : ( x_val, y_val )
Sequential 의 메서드
-
compile
-
fit
-
evaluate
-
predict
Holdout Validation
-
slicing
-
train_test_split
-
fit에서 사용
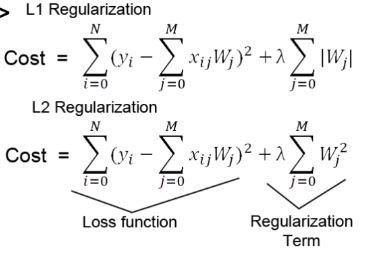
Regularization
: cost에 일정 값을 더해서 fit의 시점을 늦추는 방식
일반적으로 L1보다 L2를 사용한다.
람다는 hyperparameter이며 람다가 클수록 효과가 크다
'Weight Decay'라 불리기도 한다.
구현
from tensorflow.keras import regularizersdef regularizer_model():
model = Sequential()
model.add(Dense(20, 'relu', kernel_regularizer = regularizers.l2(0.001))
model.add(Dense(4, 'relu', kernel_regularizer = regularizers.l2(0.001))사실 딥러닝에서는 Dropout을 더 많이 사용!
Dropout
매 학습마다 설정한 drop rate만큼 random하게 node를 지워서 학습시킨다.
매 학습마다 다른 node들이 지워졌다가 복원되었다가를 반복
regularizer와 달리 Dropout Layer가 따로 존재한다. -> 실질 layer가 아니다
구현
from tensorflow.keras.layers import Dropoutdef dropout_model():
model = Sequential()
model.add(Dense(unit=10, activation='relu'))
model.add(Dense(21, 'relu'))
model.add(Dropout(0.2))바로 위의 layer를 dropout한다
dropout(rate) : 버릴 unit의 비율을 정한다
0~1 사이의 값 ( 보통 0.2~0.5 를 많이 한다 )
이 rate를 크게 할수록 dropout 효과가 크다
underfitting vs overfitting
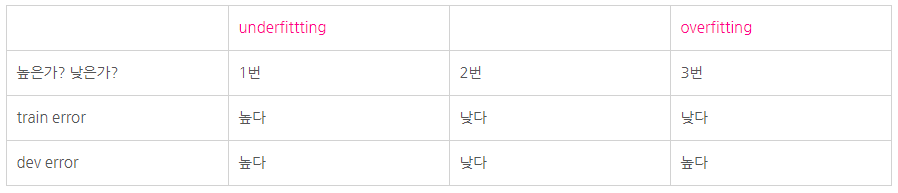
각 case 별로 어떤 문제에 처해있는지 파악할 수 있어야 한다.
