
Deep Learning을 이용한 CTR 예측
CTR prediction with Deep Learning
- 왜 CTR 문제에서 딥러닝을 이용하는 가?
- 현실 CTR 데이터를 선형 모델로 예측하는 데에는 한계가 있음
- High Sparsity, High Non-linear
Wide & Deep
- 선형 모델 (wide)와 비선형 모델 (deep) 의 장점을 모두 결합하 한 모델
- 추천 시스템에서는 Memorization, Generalization이 중요
Memorization
- 빈번히 등장하는 아이템과 피쳐와의 관계를 학습 (암기)
- LR과 같은 선형 모델은 단순하고, 확장 및 해석에 용이하나 학습 데이터에 없는 피쳐 조합에 취약
Generalization
- 드물게 발생하거나, 전혀 발생한 적 없는 조합을 기존 관계로부터 발견 (일반화)
- FM, DNN과 같은 임베딩 기반 모델
- 일반화가 가능하지만, 고차원의 희소벡터로 부터 저 차원의 임베딩을 만들기 어려움
이 둘을 결합해 추천 성능을 늘리기
Wide Component
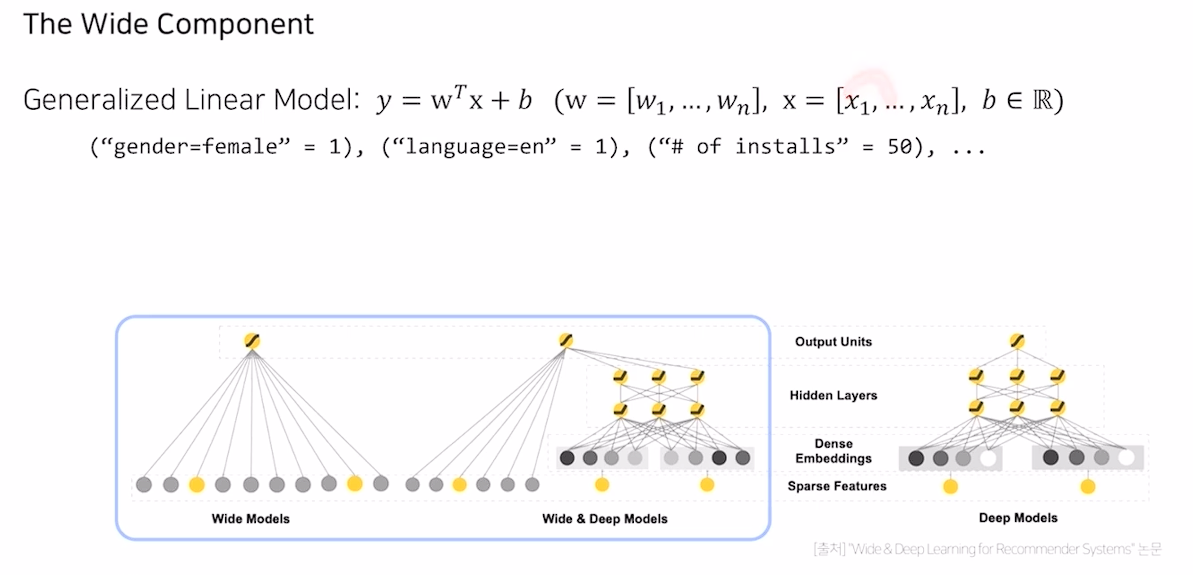

- 기존 선형 term + second order product term으로 구성 된 wide component
Deep Component

- 단순한 feed forward neural network
전체 구조

DeepFM
- Wide & Deep 모델과 달리 wide와 deep component가 입력값을 공유하도록 한 end-to-end 방식의 모델
등장배경
- Feature Interaction을 학습하는 것은 중요
- 기존 모델들은 low order or high order interaction 중 한 쪽에만 강함
- wide & deep은 이를 해결했으나, wide component에 feature engineering(product term)이 필요
- FM을 wide component로 사용해보자
- DeepFM = FM + DNN
FM Component
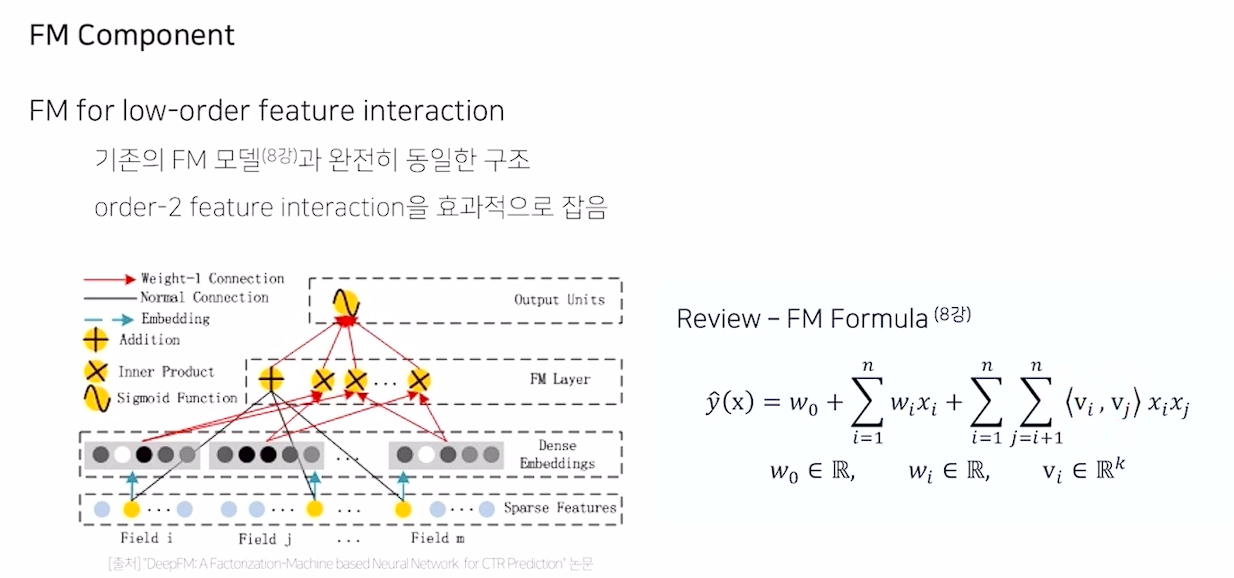
- 기존 FM formula와 수식이 완전히 동일
Deep Component

- 모든 피쳐는 동일한 차원으로 임베딩 되며, 사용되는 가중치는 FM Component의 가중치와 동일
전체 구조

Deep Interest Network (DIN)
- User behavior Feature를 처음 사용한 논문
- 기존 딥러닝 기반 모델은 모두 유사한 Embedding, MLP 패러다임을 따름
- 이러한 방식은 사용자의 다양한 관심사를 반영할 수 없음
- 사용자가 기존에 소비한 아이템 리스트를 Behavior feature로 만들어 관련성을 학습
피쳐 목록

- 기존의 메타 데이터 + User Behavior Feature (multi-hot encoding)
모델 구성
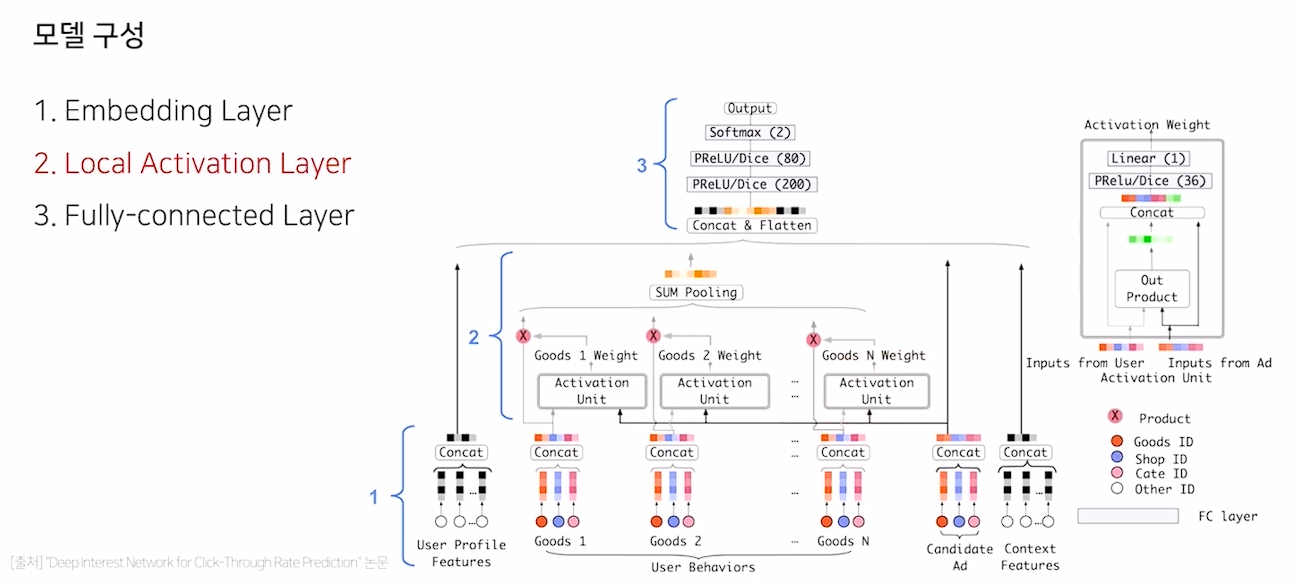
Local Activation Layer
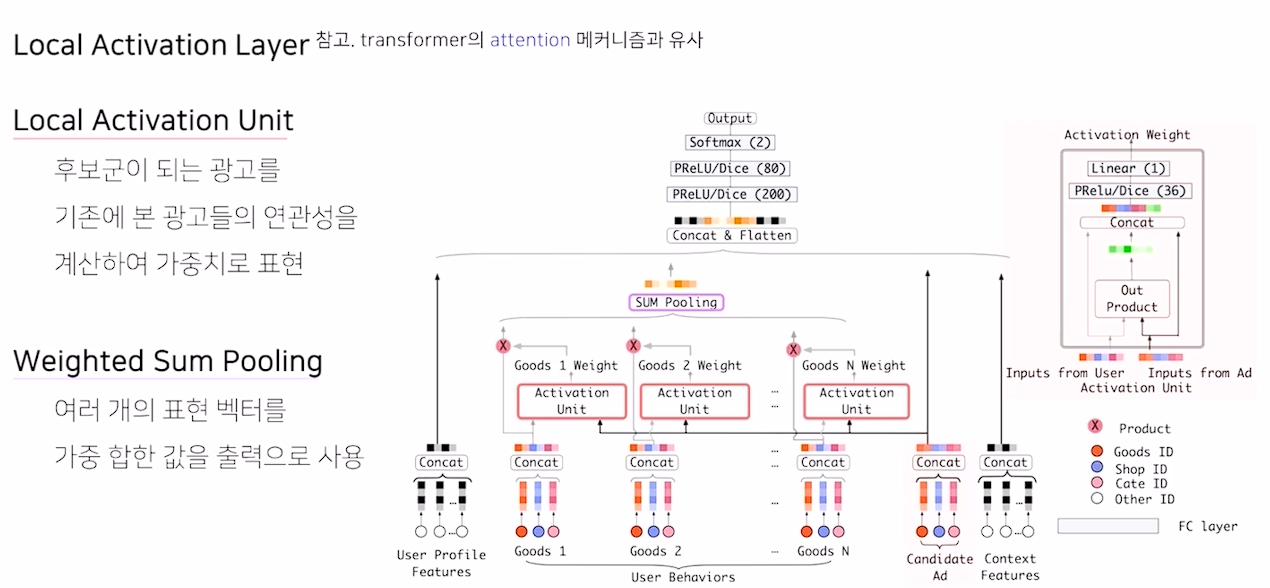
- Activation Unit을 통해 behavior와 아이템 간의 연관성 학습
- Transformer의 attention 메커니즘과 유사

- weight의 크기를 조절
Behavir Sequence Transformer (BST)
- Transformer를 CTR 예측 논문
Transformer
- CTR 예측 데이터와 NLP 번역 데이터 간 공통점이 다수
- 대부분 Sparse Feature이며, low high order interaction이 중요함
- 문장의 순서 처럼 사용자의 행동 순서 또한 중요함
- CTR에 적용
Attention

- 입력 값의 어떤 부분에 주의를 기울일 것 인지를 찾는 원리
Scale Dot-product Attention
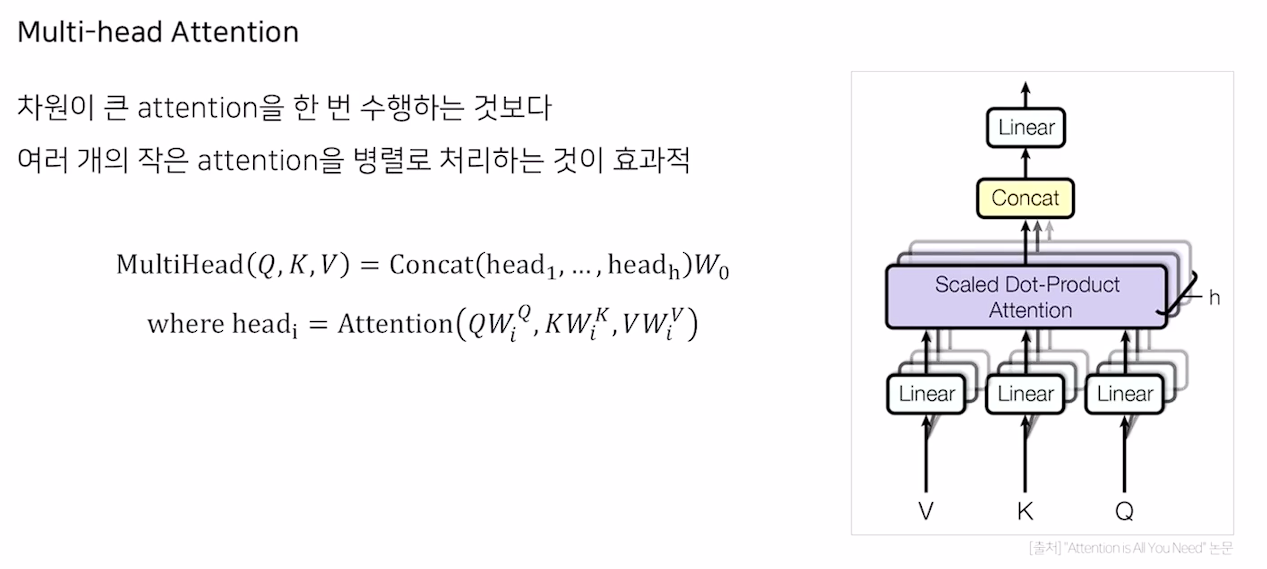
Multi-head Attention
- 이 레이어를 6개 쌓고, Add, norm, positional encoding을 통해 Transformer를 이룸
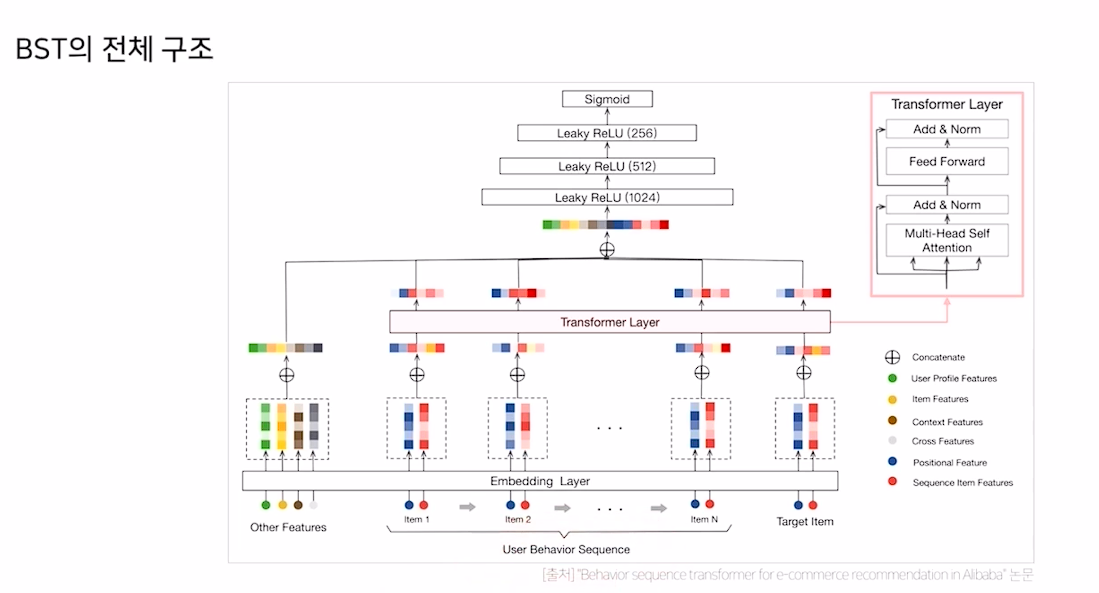
BST의 구조

- 과거에 유저가 소비했던 sequence와 Target Item을 추가해 Input으로 사용
BST Encoder layer

- dropout과 leakyRelu가 기존 encoder layer와 차이점
- 이 Encoder layer를 여러 개 쌓아 학습에 사용
vs DIN
- transformer vs local activation layer
- user behavior feature vs user behavior sequence
vs Transformer
- dropout과 leakyRelu
- 레이어를 1~4개 사용
- custom positional encoding (현재와 그 당시 아이템 상호작용 시간과의 차이)
