
강화 학습을 접목한 추천 시스템
Multi-Armed Bandit (MAB)
One Armed Bandit
- 슬롯 머신은 한 번에 한 개의 arm을 당길 수 있음
- K 개의 슬롯머신을 N 번 플레이한다면?
- 수익의 최대화를 위해 어떤 arm을 어떤 순서대로 당겨야 하는가
Challenge
- 슬롯머신 reward의 확률을 정확히 알 수 없음
- Exploration & Exploitation Trade-Off 발생
Trade-Off
Exploration
- 더 많은 정보를 얻기 위해 새로운 arm을 선택
Exploitation
- 기존의 경험을 통해 가장 좋은 arm을 선택
두 가지의 policy를 적절히 선택하는 것이 중요
문제 정의

- 모든 액션의 q*(a)를 알고 있다면 문제 해결
- 시간 t에서의 q*(a)추정치인 Qt(a)를 최대한 정밀하게 구하는 것이 목표
- 가치가 최대한 action을 선택하는 것을 greedy action 이라고 함
MAB 기초 알고리즘
Greedy Algorithm

- 지금 까지 관측한 action 중 가장 높은 평균 reward를 선택하는 것
- 처음 선택되는 action과 reward에 크게 영향을 받음
Epsilon greedy algorithm

- 일정 확률로 랜덤하게 슬롯머신을 선택하도록 함
- simple하면서 강력
- Base로 주로 사용
- Exploration이 충분함에도 계속 exploration을 하는 단점
Upper Confidence Bound (UCB)

- 데이터가 충분히 모이면 exploitation을 수행하게 하는 알고리즘
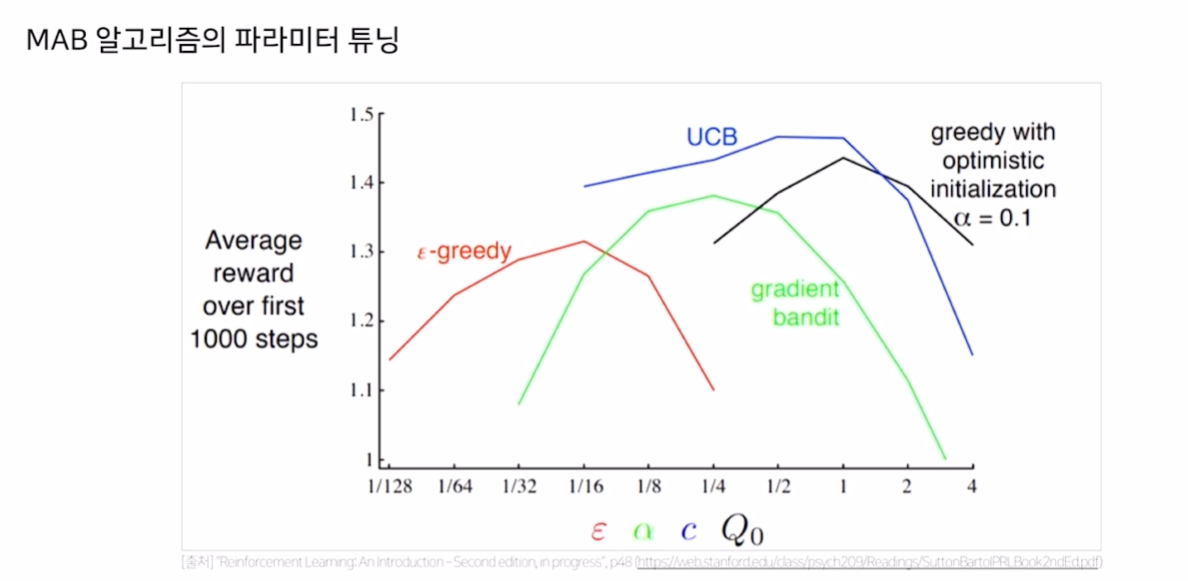
- 일반적으로 UCB가 잘 작동하지만, MAB의 최적 policy는 hyperparameter 선택이 중요
MAB를 활용한 추천시스템
- Bandit은 기존 추천 시스템과 전혀 다른 접근
- 클릭/구매를 모델의 reward로 가정
- reward를 최대화하는 방향으로 모델이 학습되고 추천을 수행 함
- 곧바로 CTR 등의 온라인 지표가 좋아짐

- 훨씬 구현이 간단하고 이해가 쉬움
유저 추천
- 개별 유저에 대해 모든 아이템의 Bandit을 구하는 것은 불가능
- 클러스터링을 통해 비슷한 유저를 그룹화 한 뒤, 해당 그룹 내에서 Bandit을 구축
- 필요 Bandit = 유저 Cluster * 후보 아이템 개수
유사 아이템 추천
- 주어진 아이템과 유사한 후보 아이템 리스트를 생성하고 그 안에서 Bandit 적용
- 유사 아이템은 MF, item2Vec, Contents based 등 유사도를 통해 측정
- 서비스에 맞게 다양한 방법을 사용 가능
MAB 심화 알고리즘
Thompson Sampling
- 주어진 K개의 action에 해당하는 확률 분포를 구하는 문제

- 주로 베타 분포를 사용
예시

- Greedy는 banner 2만 계속 sampling 하겠지만, Thompson sampling은 계속 sample을 뽑아서 action을 취함
- action 이후에, parameter를 지속적으로 update하여 수정
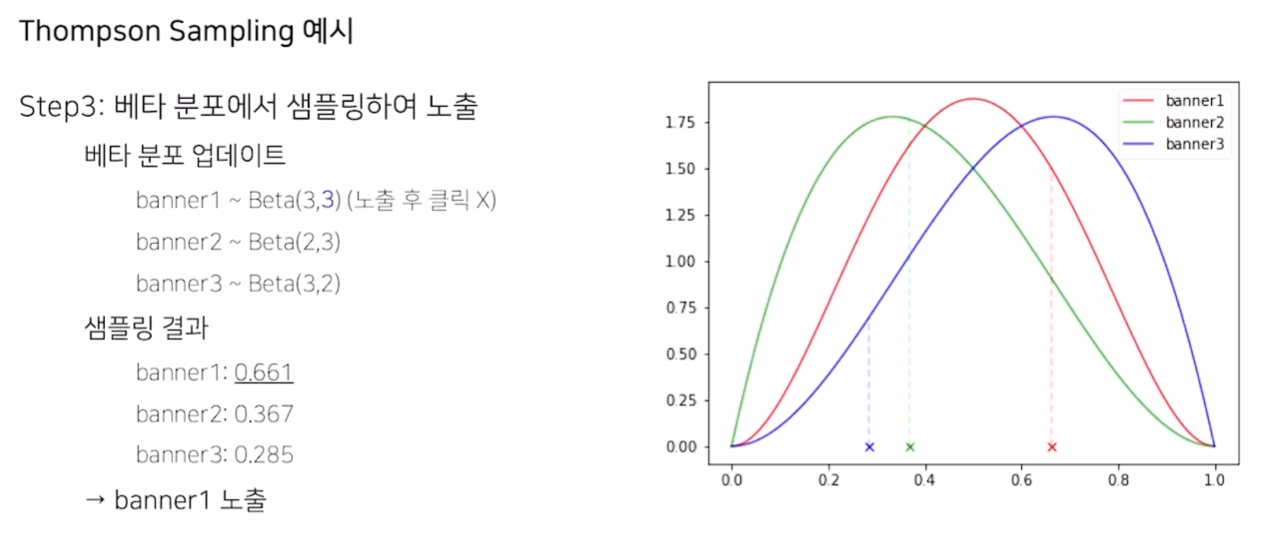
- 점직적으로 True Distribution을 찾아가는 것
LinUCB
Contextual Bandit
- 부가 정보를 활용하는 Bandit
- Action에 대해 유저의 context 정보에 관계 없이 항상 동일한 reward를 가지는 context-free bandit
- context 정보에 따라 동일한 action이라도 다른 reward를 가지는 contextual bandit
LinUCB with Disjoint Linear Models

- 컨텍스트 벡터 안에 모든 메타 데이터가 포함되어 있고, 파라미터를 Update
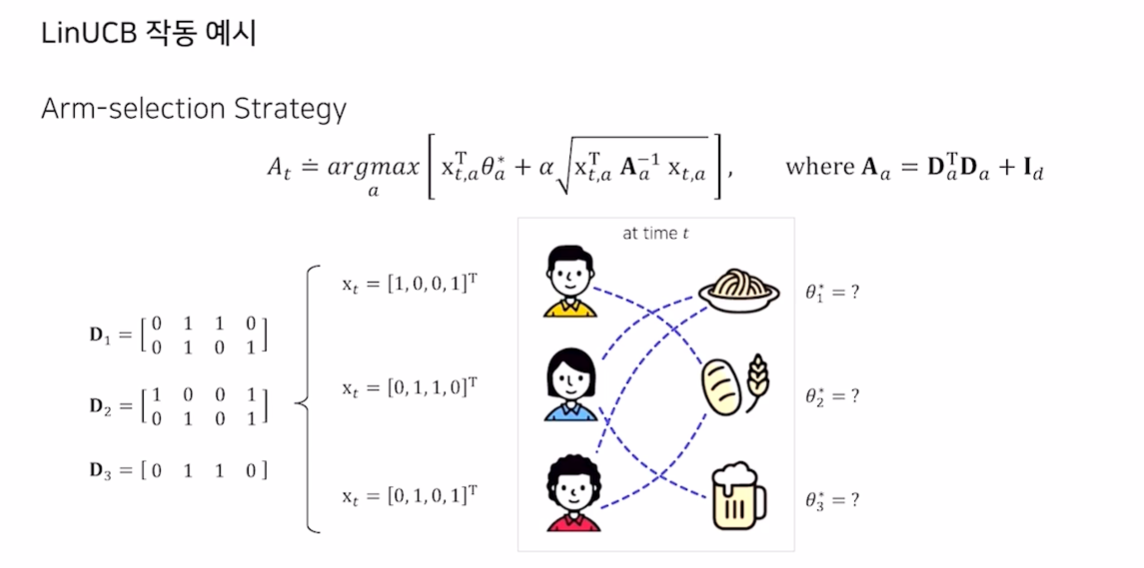
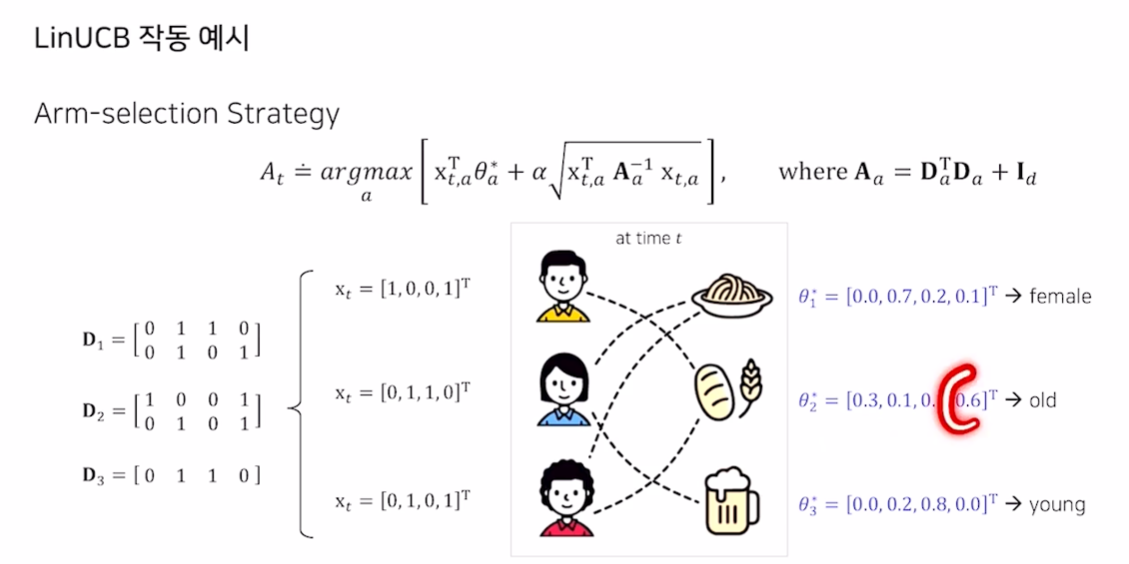
- 동일한 차원의 item 벡터를 보고 어느 것에 가중치를 두는지 확인할 수 있음
