1. 학습내용
오늘은 계속해서 딥러닝에 대해 배워보았다.
신경망 종류가 3가지로 나뉘는데, DNN을 기본으로 배워보았다. 이미지는 CNN으로 처리한다.
'activation'은 어떤 값이 들어왔을 때 이걸 통과시키냐 마느냐 판단하는 함수다.
'softmax'는 수식의 일종으로, 3개의 input 값을 집어넣으면 1을 기준으로 비율을 나눠준다.
마지막에 쓴 이유는, 도출된 값을 1을 기준으로 각각의 %를 만들어 주기 때문이다.
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))#Dense뉴런을 몇개 넣을건지(숫자 데이터는 Dense, 이미지는 Conv2D)
network.add(layers.Dense(10, activation='softmax'))
#2개의 신경망, 앞은 512개, 뒤는 10개.위의 신경망을 완성을 시키는 것을 .complie이라고 한다.
network.compile(optimizer='rmsprop', #가중치를 조절해주는 것.('rmsprop')
loss='categorical_crossentropy', #분류하는 것.손실값 계산 3개 이상 판별.
metrics=['accuracy']) #무슨 지표로 신경망을 동작시키는지.이렇게 까지하면 신경망이 준비가 된거다.
optimizer를 통해 가중치를 조절하는데, 가중치를 조절하는 방법은 경사하강법이라고 하는 'Gradient Descent'로 기울기가 올라가면 뒤로가고, 내려가면 올라갔다가 해서 왔다갔다 해서 기울기가 0이 되는 최적값을 찾는방법이다. 이게 처음부터 끝까지 체크하는 방법도 있지만 시간이 많이 걸린다는 단점이 있어서 다른방법이 있는데, 대충 몇번을 건너뛰어 내려가는 방법이다.
여러가지가 있지만 자주 쓰는건, rmsprop하고 Adam이 있다.
이제 이미지를 준비하는데 신경망에 맞게 모양을 바꿔준다. 60000, 28,28 을 60000,2828이렇게 두개의 항목으로 바꿀거다.
컴퓨터는 60000, 28,28을 2차원 모델로 보고 60000,2828은 1차원이라 이걸로 보는게 편하기 때문이다.
train_images = train_images.reshape(60000, 28 * 28)train_images 타입을 보니 정수형 8비트로 되어 있는데 이걸 실수형으로 바꿔야 한다.
train_images = train_images.astype('float32') / 255 #0~255사이의 값을 위치시키겠다는 의미.곧바로 test_images 도 바꾸었다.
test_images = test_images.reshape(10000, 28*28)
test_images = test_images.astype('float32') / 255
우리는 숫자이미지를 인식하는 자료를 쓰고 있다. 몇번째 숫자라고 프린트 되는 아래 결과는 계산할 수 있는 수가 아닌 구별만 하는 수라는 카테고리라는 것을 명확하게 하기 위해
아래와 같이 입력한다.
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)여기까지 하면 데이터 준비하고 신경망을 만든것이다. 이제 학습만 시키면 된다.
network.fit(train_images, train_labels, epochs=5, batch_size=128)#batch~한번 돌릴때 데이터 사이즈 정함.신경망에서 사용되는 역전파 알고리즘(backpropagation algorithm)은 파라미터를 사용하여 입력부터 출력까지의 각 계층의 weight를 계산하는 과정을 거치는 순방향 패스(forward pass), forward pass를 반대로 거슬러 올라가며 다시 한 번 계산 과정을 거처 기존의 weight를 수정하는 역방향 패스(backward pass)로 나뉩니다. 이 전체 데이터 셋에 대해 해당 과정(forward pass + backward pass)이 완료되면 한 번의 epoch가 진행됐다고 볼 수 있습니다.
역전파 알고리즘이 무엇인지 잘 모른다고 하더라도 epoch를 전체 데이터 셋에 대해 한 번의 학습 과정이 완료됐다고 단편적으로 이해하셔도 모델을 학습 시키는 데는 무리가 없습니다.
epochs = 40이라면 전체 데이터를 40번 사용해서 학습을 거치는 것입니다.
참고자료:
https://m.blog.naver.com/qbxlvnf11/221449297033
그럼 아래와 같이 학습한다.

이러면 손실값이 나오는데, 이걸 옵티마이저가 신경망을 조절해 가중치를 바꿔서 다시 돌린다.
이걸 평가하기 위해서.evaluate로 test데이터를 넣고 평가를 한다.
test_loss, test_acc = network.evaluate(test_images, test_labels)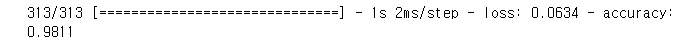
print('test_acc', test_acc)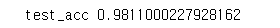
다음은 영화리뷰 데이터를 분류하는 작업을 해보았다. 이미 전처리 되어 있다. 10000차원의 벡터로 변환해서 사용한다.
from keras.datasets import imdb
(train_data, train_label), (test_data, test_label) = imdb.load_data(num_words=10000)#중요한 만개만 추려서 가져옴.keras 문법테스트 데이터의 수는 아래와 같다.
len(test_data) #문자수 계산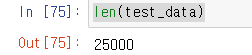
리뷰는 전부 숫자로 변환되어 있는데 그걸 아래와 같이 써서 영문으로 다시 출력해보면 아래와 같다.
# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다
word_index = imdb.get_word_index()
# 정수 인덱스와 단어를 매핑하도록 뒤집습니다
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 리뷰를 디코딩합니다. # 0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺍니다
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
decoded_review
단어들을 숫자로 치환 이걸 긍정적인지 부정적인 단어인지 숫자로 구분한다.
2. 어려웠던 점 및 해결 방안
숫자인 단어들을 만개짜리 배열로 만들어 나열할거다. 이런걸 할 수 있는 함수를 만든다.
이게 이해가 안되서 다시 동영상을 봤다.
def vectorize_sequences(sequences, dimension=10000): #넘겨받을 숫자를'sequences'로 받음. 0~9999 즉 만차원을 만들 변수.
results = np.zeros((len(sequences),dimension)) #0으로 만개짜리 배열을 채우고 해당되는 값에만 1로 넣음. 튜플타입으로 표시해야함. 하나의 파라메터로 인식할수 있게끔.
len(sequences)은 단어의 길이만큼 배열은 만듦.
for i, sequence in enumerate(sequences): #반복가능한 개체로 바꿔줌. index번호가 자동으로 생긴다. i에 index값이, 각각의 데이터 값이 'sequence'에 들어감.
results[i, sequence] = 1. #1.0 이란뜻
return resultsfor문은 해당되는 단어 위치에다가 1을 넣는다. 전체 단어 수많큼 1을 넣어준다.
이렇게 변환된 것을 아래와 같이 저장한다.
X_train = vectorize_sequences(train_data)
X_test = vectorize_sequences(test_data)이걸 실수형으로 또 바꿔준다. (label을 바꿈)
y_train = np.asarray(train_label).astype('float32')
y_test = np.asarray(test_label).astype('float32')신경망을 'model'이라 하고 3개정도를 만든다. 그 신경망 안에 들어가는 뉴런을 처음은 16개, 두번째도 16개(갯수의 정답은 없음. 단 중간에 뉴런의 숫자가 줄었다 늘면 안됨, 정보의 손실때문) 세번째는 결론에 이르기 위해 1개만 한다. 데이터가 입력되는 모양은 10000개로 해야 한다.
0,1(긍정,부정) 값이 나와야 하므로 sigmotd 함수를 쓰고 처음은 그값 그대로 쓰니까 relu를 씀.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) #레이어 안 신경의 계수
model.add(layers.Dense(16, activation='relu')) #첫번째만 입력에 대한 모양 지정해주면 됨
model.add(layers.Dense(1, activation='sigmoid'))모델에 옵션을 추가한다.
model.compile(optimizer='rmsprop,
loss='binary_crossentropy', #분류문제 둘중하나가 나와야 해서'binary_crossentropy'를 써야 함.
metrics='accuracy') #평가지표X_val = X_train[:10000] #슬라이싱 기법, 학습데이터에서 만개를 갈라냄. 앞을 생략함(그럼 앞에서부터 만개란 소리)
partial_X_train = X_train[10000:] #만개 이후 나머지 부분
y_val = y_train[:10000]
partial_y_train = y_train[10000:]이제 학습을 시키고 제대로 되었는지 검증하는 작업을 한다. 일단 15000(partial_X_train)건만 학습하고, 10000건으로 검증을 한다.
history = model.fit(partial_X_train,
partial_y_train,
epochs=3,
batch_size=512,
validation_data=(X_val, y_val)) #결과를 검증하는 작업.
history_dict = history.history #위에서 실행했던 결과들이 나옴.
history_dict.keys() #어떤 내용이 있는지 나옴.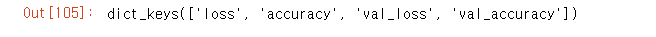
이걸 그래프로 보기 위해 아래와 같이 코드를 쓴다. 어느선에서 반복을 그만해야 하는지 알수 있다.
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1) #1부터 20까지 acc의 총개수를 지정. 추가로 1칸정도 더 밀어준다.x값엔 반복함수(epochs)를 y에는 손실함수를(loss)를 정해 그래프를 그린다. 반복시 손실이 얼마나 주는지 알수 있다. epochs는 0부너 20까지 loss는 0부터 0.7까지 볼거다.
검증 손실은 어느시점까지 내려가다 올라가기 시작함. (<-학습용 데이터에 과대 적합이 됨. 그때 학습을 중단시켜야 한다.)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'r-', label='Validation loss')
plt.title('Trining and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()그런데 예상한 대로 그래프가 안나와서 상위의 optimizer를 'optimizers.RMSprop(lr=0.01)'이런 식으로 바꾸고.
'from keras import losses
from keras import metrics
from tensorflow.keras import optimizers' 를 추가한다.
RMSprop(lr=0.01)이게 학습량을 설정하는 것과 똑같은 현상이 일어난다.
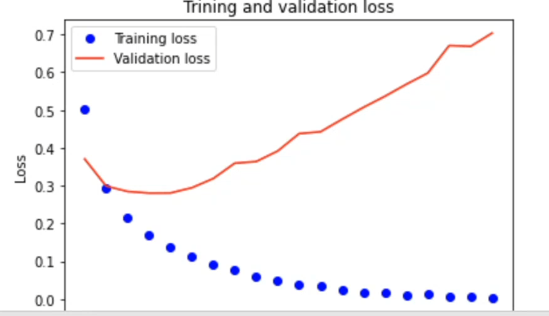
이걸 보니, 한 3~4번 정도 학습했을때가 가장 좋다는 결론이 나온다. 그래서 위에 epochs를 바꾸면 가장 정확한 모델이 나오는 것을 알 수 있다.
이제 모델을 평가하는 작업을 해본다.
results = model.evaluate(X_test, y_test)평가는 test값으로 한다.
정확하게 보기 위해 변수로 만들었다.

정확도는 82프로 정도 손실값은 71프로 정도 나온다.
이 모델로 예측값을 출력해 본다.
model.predict(X_test) #y값을 돌려줌.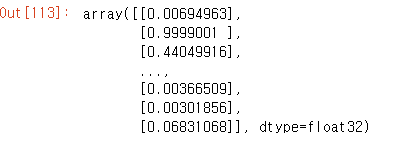
1이 긍정적인 후기, 0이 부정적인 후기라고 설정했으니 어떤 불만이 있는지 알수 있다.
3. 학습 소감
다시 차근차근 보니 이제 좀 배운게 눈에 들어 오는것 같긴하다. 그러나 역시나 새로운 뉴런 네트워크를 배우니 또 어렵게 느껴졌다.
