1. 학습내용
오늘은 SVM에 대해 배웠다.
서포트 벡터 머신(SVM: support vector machine)은 퍼셉트론 기반의 모형에 가장 안정적인 판별 경계선을 찾기 위한 제한 조건을 추가한 모형이라고 볼 수 있다.
두 클래스 사이에 선을 그었을 때 두 공간이 생기고 그 공간사이 전체 길이를 마진이라고 한다.
이 공간 자체를 support vector라고 한다.
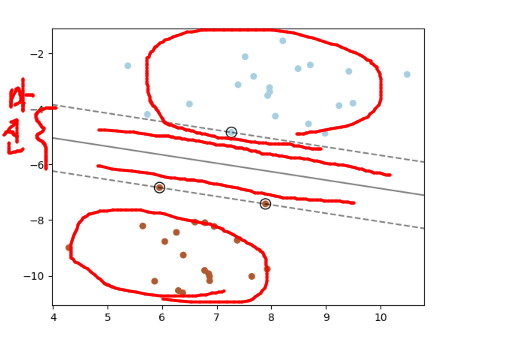
매개변수 "C"를 줘서 겹치는 영역을 얼마나 허용해 줄것인가. 얼마나 칼같이 분리하느냐에 다라 다르다.
식은 아래와 같다.
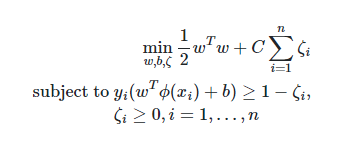

그러나 이런 식은 프레임 워크에 다 녹아있다고 하셨다.
저걸 활용하는 건 2차원으론 자를수 없는 방법일때 3차원으로 올려서 자르는 방법이기 때문이다
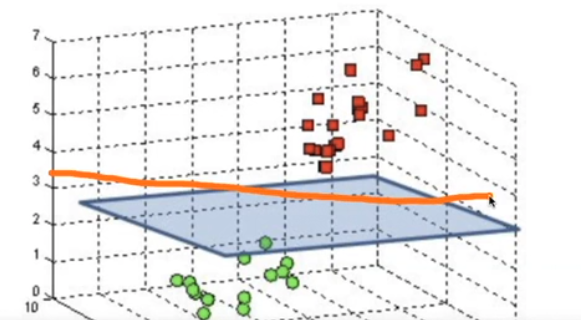
그림에 파란 막같은게 있는데 저 면같은 걸로 서로 다른 클래스들을 분리한다.
# 두 번째 특성을 제곱하여 추가합니다
X_new = np.hstack([X, X[:, 1:] ** 2])
from mpl_toolkits.mplot3d import Axes3D, axes3d
figure = plt.figure()
# 3차원 그래프
ax = Axes3D(figure, elev=-152, azim=-26)
# y == 0 인 포인트를 먼저 그리고 그 다음 y == 1 인 포인트를 그립니다
mask = y == 0
ax.scatter(X_new[mask, 0], X_new[mask, 1], X_new[mask, 2], c='b',
cmap=mglearn.cm2, s=60, edgecolor='k')
ax.scatter(X_new[~mask, 0], X_new[~mask, 1], X_new[~mask, 2], c='r', marker='^',
cmap=mglearn.cm2, s=60, edgecolor='k')
평면은 N차원-1차원이 평면의 차원이다. 초평면이라고도 한다. 위의 그래프를 평면으로 나눠보려 한다.
X_train, X_test, y_train, _y_test = train_test_split(cancer.data,
cancer.target,
random_state=0)
from sklearn.svm import SVC #SVC 알고리즘
svc = SVC()
svc.fit(X_train, y_train)
print(svc.score(X_train, y_train))
print(svc.score(X_test, y_test))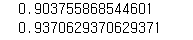
생각보다 꽤 괜찮은 결과가 나왔다. 데이터의 군집이 어느정도 되어 있다면 SVM이 알맞고, 좀 많이 흩어져 있다면 Tree알고리즘이 낫다.
이 다음은 딥러닝에 관한 개념을 살짝 보았다.
프레임워크가 여러가지가 있는데 그 중에 실습은 keras와 tnesorflow로 해보기로 했다.
그 전에 함수 그래프에 대해 배웠다.

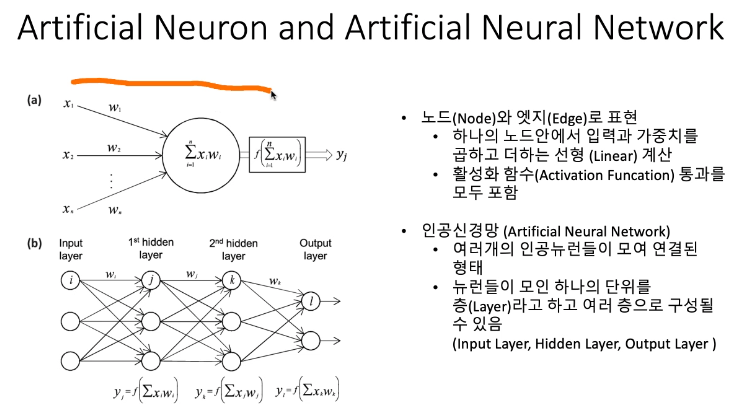
데이터를 넣을 때 함수에 넣어서 결과값을 도출 하는 데 그함수는 여러가지가 있다.
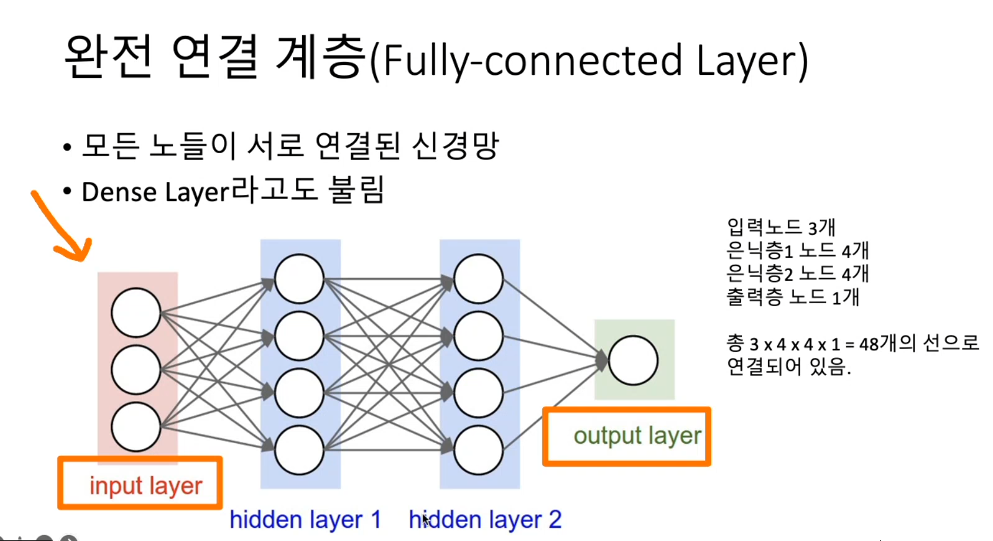
하지만 이미지 같은 것을 해석하려면 중간의 뉴럴의 갯수가 많아야 한다.
(중간의 레이어도 많아야 한다.)
우린 손글씨로 쓴 숫자를 알아보게 해서 최종 어떤 숫자가 출력되는지를 알아보는 Mnist를 쓸것이다.
딥러닝은 가중치에 의해 결과값이 많이 달라진다고 한다. 랜덤으로 넣은 가중치로 데이터를 input해서 예측치 y와 실제 데이터인 y가 얼마나 차이나는 지 검사해보는 것이다. 이걸 손실함수라고 한다. (loss Funcion) 이걸 통과하면 차이점을 정수로 매겨서 점수가 나오는데 그 차이가 크면
다시 가중치를 조정해 데이터를 넣어보는 것이다.
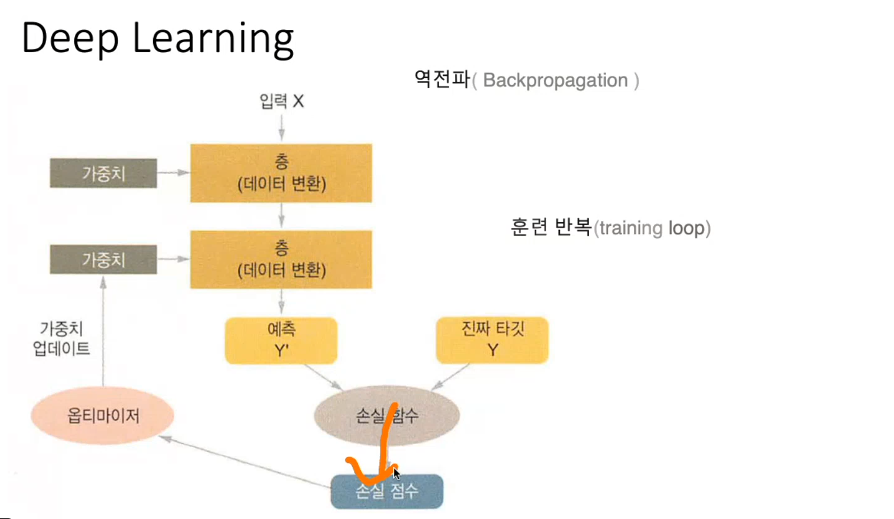
옵티마이저가 손실값을 보고 가중치를 조정한다. 오류를 다시 역으로 전파한다고 해서 역전파라고 한다.
이걸 반복하다보면 데이터에 맞는 가중치가 생기게 되는데 이걸 overfiting되었다고 한다.
각 층마다 출력을 낼때 어떻게 낼건가 하는건 아래 함수를 적용한다.

예를 들어 타이타닉호 데이터면 살고 죽고 하는 문제에 대한 데이터에서 저 함수들 중에 적용하면 특정 숫자 범위 안에서 죽음이 결정되는게 아닌 좀더 명확하게 결과가 나온다.
텐서라는 개념을 또 배웠다.
스칼라(Scalar)는 0차원 배열로 그냥 값만 존재하는 값이다. Rank가 1이면 벡터(Vector)를 의미하며,1차원 배열을 말한다. n이면 n차원 배열을 의미한다고 생각하면 된다.

참고자료: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=complusblog&logNo=221237818389
참고로, 칼라 이미지는 참고로 4차원 텐서, 동영상은 5차원 텐서 정도 필요하다.
2. 어려웠던 점 및 해결 방안
손글씨로 쓴 숫자를 구분하는 알고리즘을 쓸때 조건문을 쓰는 일이 있었다.
퍼셉트론 게이트 AND OR NAND 등을 적용해보는 거였는데, 함수 식을 써서 0보다 작으면 0값을 출력하고, 아니면 1을 출력하는 거였다.
def AND(x1, x2): #input 값
input = np.array([x1,x2])
weights = np.array([0.4,0.4]) #가중치(임의로 설정할 수 있음)
bias = -0.6 #편향점
value = np.sum(input * weights) + bias
if value <= 0:
return 0
else:
return 1저 위의 식이 이해가 안갔는데 활성화 함수의 식을 저렇게 풀어놓은 것이었다.

np.sum이 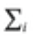
나타내는 것이였다.
퍼셉트론 게이트 저 부분이 논리 회로인데 저 논리로 알고리즘의 결론을 낸다고 한다. 처음에 왜 논리회로가 들어가는지 몰랐는데 구글링을 해보니 알수 있었다.
퍼셉트론 알고리즘을 구현하는데 쓰이는데 이 퍼셉트론 알고리즘은 딥러닝의 기원이 되는 매우 중요한 알고리즘이라고 한다.
퍼셉트론은 다수의 신호를 입력으로 받아 하나의 신호로 출력하는데 이때 하나이상의 값들을 input으로 받아 어떠한 계산후 output으로 출력한다. 퍼셉트론 신호는 1이나 0 두가지 값을 가질수 있다. 신호가 흐르면 1, 흐르지 않으면 0이라 생각하면 편하다.
자세한 내용은 아래 참고자료에 나온다.
참고자료: https://leedakyeong.tistory.com/entry/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0-%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94-%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%8D%BC%EC%85%89%ED%8A%B8%EB%A1%A0%EC%9D%B4%EB%9E%80-What-is-perceptron
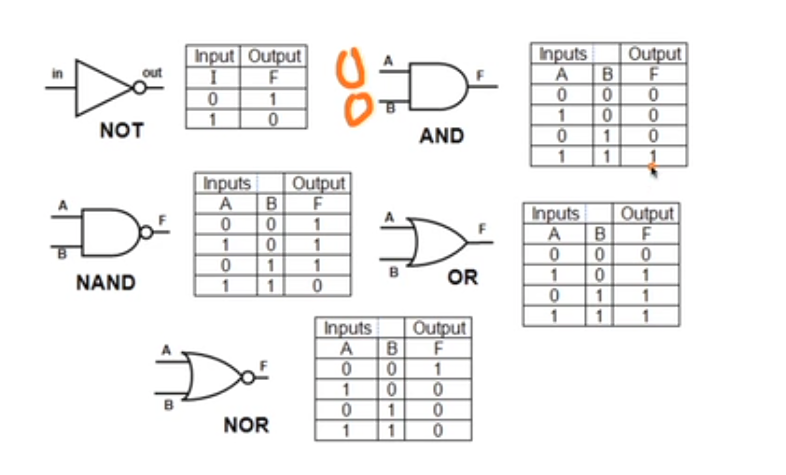
논리 회로는 아래와 같이 있다.
NOT 게이트
; 1개의 입력과 1개의 출력을 갖는 게이트로 부정을 표현
AND 게이트
; 입력이 모두 1인 경우에만 출력이 1이 됨
입력 중 하나라도 0이 있으면 출력이 0이 되는 논리곱
OR 게이트
; 입력이 모두 0인 경우에만 출력이 0
입력 중 1이 하나라도 있으면 출력은 1이 되는 논리합
NAND 게이트
; 입력이 모두 1인 경우에만 출력이 0이고, 입력에 0이 하나라도 있으면 출력이 1
AND가 NOT된 것
NOR 게이트
; 입력이 모두 0인 경우에만 출력이 1이고, 입력에 1이 하나라도 있으면 출력이 0
OR가 NOT된 것
XOR 게이트
; 입력에 1이 홀수 개면 출력 1, 짝수 개면 0
원래 F(출력) = A'B + AB' 로 계산해야 함.
그리고 위의 수식에 '편향'이란 말이 이해가 안되었는데 역시 구글링을 하니 알수 있었다.
정답 하나를 맞추기 위해 컴퓨터는 여러 번의 예측값 내놓기를 시도하는데,
컴퓨터가 내놓은 예측값의 동태를 묘사하는 표현이 '편향' 과 '분산' 이다.예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 말하고,
예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)이 높다고 말합니다.
참고자료: https://opentutorials.org/module/3653/22071
저 편향값과 가중치를 조절해서 논리 회로를 만드는 것이었다.
위의 코드를 그래프를 그리면 편향 선에서 (1,1)이 벗어난 것을 알수 있는데 수치를 다르게 넣어서 비슷한 그래프를 만들어 보았다.
x1 = np.arange(-2, 2, 0.01)
x2 = np.arange(-2, 2, 0.01)
bias = -0.6
y = (-0.4 * x1 - bias) / 0.4 #가중치: 0.4
plt.axvline(x=0) #축 설정.
plt.axhline(y=0)
plt.plot(x1, y, 'r--')
plt.scatter(0,0,color='orange',marker='o',s=150)
plt.scatter(0,1,color='orange',marker='o',s=150)
plt.scatter(1,0,color='orange',marker='o',s=150)
plt.scatter(1,1,color='black',marker='^',s=150)
plt.xlim(-0.5,1.5)
plt.ylim(-0.5,1.5)
plt.grid() #값을 분류하는 기준이 되는 선:빨간 점선
3. 학습소감
오늘은 딥러닝에 대해 조금 배워봤는데, 역시나 함수를 좀 이해하지 못하면 코드를 못넣겠다는 생각이 처음 들었다. 그래도 새로 딥러닝이 되는 모델을 만들어 보는게 좀 신기하긴 했다.
