1. 학습내용
오늘은 이미지를 읽어 딥러닝 모델을 만드는 것을 해 보았다.
구글 드라이브에 이미지 자료를 넣어 그 이미지를 우선 읽어 오는 작업부터 했다.
import keras
keras.__version__from google.colab import drive
drive.mount('/content/drive')import os, shutil #리눅스 명령어 같은거 쓸수 있는 스크립트(shutil)# 원본 데이터 셋을 압축 해제한 디렉터리 경로
original_dataset_dir = './drive/MyDrive/datasets/cats_and_dogs/train'
# 소규모 데이터셋을 저장할 디렉터리
base_dir = './drive/MyDrive/datasets/cats_and_dogs_small'
if os.path.exists(base_dir): #해당되는 경로가'base_dir'있는지 확인하는 매서드
shutil.rmtree(base_dir) #있으면 기존의 것을 삭제하고(rmtree)
os.mkdir(base_dir) #새로 만듦그런다음 '훈련용','검증용', '테스트용' 폴더를 새로 만들고, 있으면 삭제하고 생성하는 것을 만든다.
# 훈련, 검증, 테스트 분할을 위한 디렉터리
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)그런다음 '고양이'와 '강아지' 사진을 나눠서 그 나눈 사진도 위의 폴더에 각각 나누어 복사해 넣는 코드를 작성한다.
# 훈련용 고양이 사진 디렉터리
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 훈련용 강아지 사진 디렉터리
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 검증용 고양이 사진 디렉터리
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 검증용 강아지 사진 디렉터리
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
#테스트용 고양이 사진 디렉터리
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
#테스트용 강아지 사진 디렉터리
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)# 처음 1000개의 고양이 이미지를 train_cats_dir에 복사합니다.
print('Copy files....')
print('---traing file(s) (cat)....')
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 validaion_cats_dir에 복사합니다.
print('---validation file(s) (cat)....')
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 test_cats_dir에 복사합니다.
print('---test file(s) (cat)....')
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 처음 1000개의 강아지 이미지를 train_dogs_dir에 복사합니다.
print('---traing file(s) (dog)....')
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 validaion_dogs_dir에 복사합니다.
print('---validation file(s) (dog)....')
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 test_dogs_dir에 복사합니다.
print('---test file(s) (dog)....')
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
위의 코드는 한 셀로 적어야 폴더를 중복으로 만들지 않음.
학습을 하고, 이걸 검증하는 역활이 'validation'이고, 'train'과 같이 사용이 되고, 여기서 나온 모델로 남은 'test' 로 돌려 보고 얼마나 정확성이 높은 지 확인한다.
위에 것을 잘 복사 했으면 아래의 print코드로 갯수를 확인해 본다.
print('훈련용 고양이 이미지 전체 개수:', len(os.listdir(train_cats_dir)))
print('검증용 고양이 이미지 전체 개수:', len(os.listdir(validation_cats_dir)))
print('테스트용 고양이 이미지 전체 개수:', len(os.listdir(test_cats_dir)))
print('훈련용 강아지 이미지 전체 개수:', len(os.listdir(train_dogs_dir)))
print('검증용 강아지 이미지 전체 개수:', len(os.listdir(validation_dogs_dir)))
print('테스트용 강아지 이미지 전체 개수:', len(os.listdir(test_dogs_dir)))
이제 파일이 잘 복사된걸 확인했으니 모델을 만든다. 저번주 금요일에 배운 내용을 토대로,
이미지는 뉴런이 많으면 많을 수록 모델이 잘 읽으니, 한 11개의 레이어를 만들어 모델을 만든다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten()) #이미지를 넓게 펴줌.
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) #이진분류는 'sigmoid'참고로 첫번째 Conv2D 층의 첫번째 인자 32는 filters 값이다.
합성곱 연산에서 사용되는 필터 (filter)는 이미지에서 특징 (feature)을 분리해내는 기능을 하고,
filters의 값은 합성곱에 사용되는 필터의 종류 (개수)이며, 출력 공간의 차원 (깊이)을 결정한다.
두번째 인자 (3, 3)은 kernel_size 값이다.
kernel_size는 합성곱에 사용되는 필터 (=커널)의 크기.
참고자료 : https://codetorial.net/tensorflow/convolutional_neural_network.html
마지막의 층은 0,1 둘중 하나만 나오면 되기 때문에, 'Dense' 에 이진분류인 'sigmoid'
를 넣는다.
층의 깊이가 깊어질 수록 심오한 문제를 풀 수 있다.
이걸 요약해 보여줄려니 'complie'이 안되서 에러가 나므로 그걸 해준다.
(파이썬의 내장함수로, 문자열을 컴파일하여 파이썬 코드로 반환한다.)
from tensorflow.keras import optimizers
model. compile(loss='binary_crossentropy', #둘중 하나의 값이 결과값이 나와야 해서.
optimizer=optimizers.RMSprop(lr=1e-4), # 학습률설정. 0.0001 정도 됨.
metrics=['acc']) #'acc'는 정확도란 뜻.이미지를 그냥 쓸수 없다. 크기의 차이때문에 다르게 인식될 수 있으므로, 사이즈를 일정하게 조절하는 코드를 쓴다.
from keras.preprocessing.image import ImageDataGenerator #이미지 전처리 기능
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator =train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
validation_generator =validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)이제 만들어진 모델을 변환하면서 fit을 해본다.
많이 반복해야 결과가 나올 수 있기 때문에 epochs를 30회로 한다.
model.fit_generator(
train_generator,
epochs=30,
steps_per_epoch=100,
validation_data=validation_generator,
validation_steps=50
)이렇게 모델을 만든걸 따로 저장 할 수도 있다.
model.save('cats_and_dogs_small_1.h5')이렇게 만든 모델을 그래프로 한번 훈련용과 검증용이 얼마나 정확도가 높은지 확인해 본다.
history = model.history
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()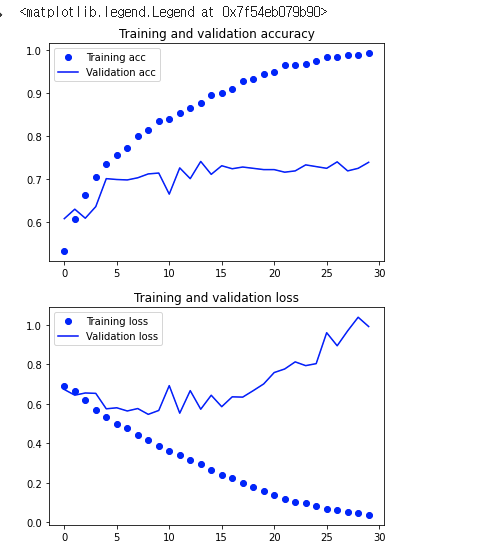
훈련용은 돌려보면 볼수록 정확도가 거의 100%가깝게 가는 것으로 보이고, 검증용은 어느 시점에서 멈추는 것을 볼수 있다.
검증된 이미지가 몇개 없다면 이미지를 증식시켜야 한다. 예로 한 고양이 사진이 있다면, 한장을 랜덤으로 이미지를 좌우 반전을 시켜보고 또 앵글을 다르게 돌려보고 이런 식으로 여러개로 만들어 낸다.
이런 방식을 사용하는 기법은 아래와 같다.
datagen = ImageDataGenerator(
rotation_range=40, #돌리는 각도
width_shift_range=0.2, #수평으로 돌리는 각도(20%), 좌우
height_shift_range=0.2, #상하로 돌림
shear_range=0.2,
zoom_range=0.2, #확대 축소
horizontal_flip=True, #수평으로 좌우로 바꿈
fill_mode='nearest') #이미지 이동시 빈값을 근처 색으로 채움
# 이미지 전처리 유틸리티 모듈
from keras.preprocessing import image
fnames = sorted([os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)])
# 증식할 이미지 선택합니다
img_path = fnames[3]
# 이미지를 읽고 크기를 변경합니다
img = image.load_img(img_path, target_size=(150, 150))
# (150, 150, 3) 크기의 넘파이 배열로 변환합니다
x = image.img_to_array(img)
# (1, 150, 150, 3) 크기로 변환합니다
x = x.reshape((1,) + x.shape)
# flow() 메서드는 랜덤하게 변환된 이미지의 배치를 생성합니다.
# 무한 반복되기 때문에 어느 지점에서 중지해야 합니다!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
이번엔 다른 조건으로 해서 모델을 만들어 보았다.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5)) #중간중간 노드들을 죽여버리고, 랜덤하게 연결하여 학습을 진행
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])위에 처럼 이미지 스케일 일정하게 하고, .fit을 해보았다.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블을 만들어야 합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32, #검증에는 증식사용하지 않음(test에서만)
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)처음에 다 학습이 되질 않아서 'train_generator'의 batch_size를 32에서 20으로 낮추었다.
그런다음 또 그래프로 비교를 해보니 아래와 같이 나왔다.
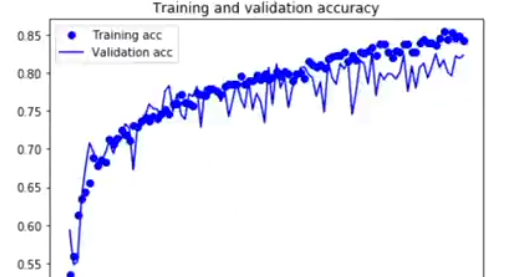
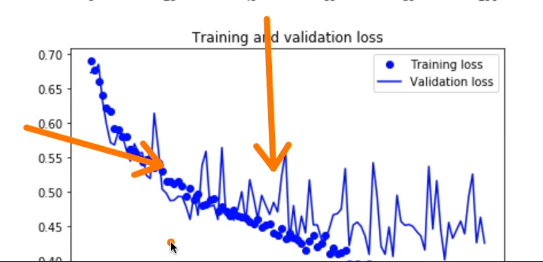
이미지를 증식시켜서 학습에 대해 정확도를 높인게 보인다.(화살표로 표시된 높게 올라간 그래프를 보아하니)
2. 어려웠던 점 및 해결 방안
어려웠던 점이라면, 중간중간 그대로 카피해서 무슨 명령문인지 모를때가 어려웠다.
이해가 안되고 그냥 넘어갔던 것들은 다시 동영상을 보고 이해했고...
명령문을 그래서 구글링을 해서 다시 찾아보고 주석을 달았다.
3. 학습 소감
모델을 저장해서 쓰고 싶을때 쓸 수 있다는게, 뭔가 결과값이 보여서 뿌듯하게 느껴졌다.
내일은 클라우드에 관해 또 배운다고 하니 조금 기대가 된다.
