
웹데이터 분석 예제1-1. 네이버 금융 정보 확인
1) 모듈 및 url 정보 가져오기
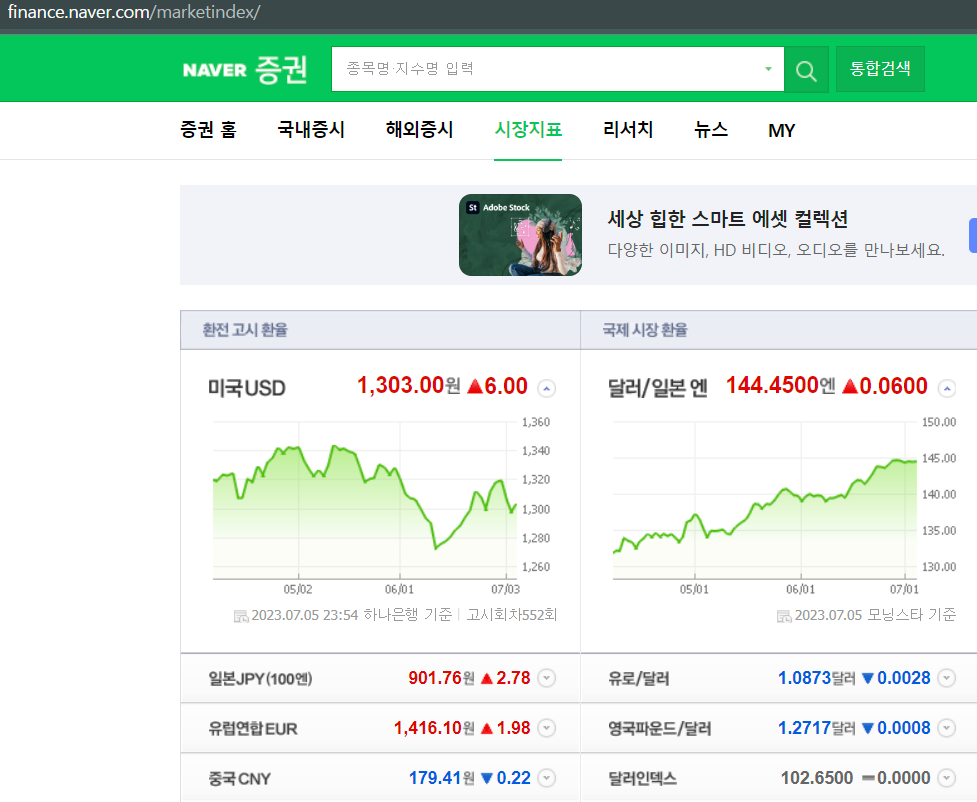
- 분석할 페이지 : 네이버 증권 - 시장지표
- import 모듈
from bs4 import BeautifulSoup url가져올 떄 요청하는 모듈 from urllib.request import urlopen
- url정보 가져오기
url = "https://finance.naver.com/marketindex/" page = urlopen(url) soup = BeautifulSoup(page,"html.parser") print(soup.prettify())네이버 증권 시장지표 html 가져오기
2) 페이지 html코드 확인 방법
인테넷 페이지 내에서 "ctrl + shift + I"
- 개발자 도구 창의 왼쪽 상단 아이콘 클릭 후 찾고싶은곳 커서올리면 코드 찾아 갈 수 있다.


3) 원하는 정보 뽑아내기
- 개발자 코드 창에서 span태그의 class명이 value인것을 확인
soup.find_all("span",class_= "value")span태그의 class명이 value인 모든 정보
[<span class="value">1,300.00</span>, <span class="value">900.50</span>, <span class="value">1,416.74</span>, <span class="value">179.87</span>, <span class="value">144.4500</span>, <span class="value">1.0906</span>, <span class="value">1.2688</span>, <span class="value">102.6500</span>, <span class="value">69.79</span>, <span class="value">1569.16</span>, <span class="value">1929.5</span>, <span class="value">80493.1</span>]
- 원하는 값은 뽑아낸 정보에서 첫번째 데이터의 문자
- 문자로 출력해주는 여러가지 방법
soup.find_all("span",{"class":"value"})[0].text soup.find_all("span",{"class":"value"})[0].string soup.find_all("span",{"class":"value"})[0].get_text()'1,300.00'
웹데이터 분석 예제1-2. 네이버 금융
- 최종 목표
- 네이버 금융에 환전고시환율 칸 국가, 금액, 변화량, 상승하락 구분 데이터 프레임 만들기
- 계속해서 분석하고 데이터를 가져올 페이지의 개발자도구를 활용해서 원하는 데이터의 정보들을 찾아야한다.
- requests 모듈을 사용해보자
pip install requests- urllib.request와 requests의 차이점
1) 모듈 import
import requests #데이터 프레임을 만들기 위해 import pandas as pd from bs4 import BeautifulSoup
2) 페이지 html 정보 가져오기
url = "https://finance.naver.com/marketindex/" #response.get(), response.post() response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") print(soup.prettify())
3) 원하는 데이터 : 환전고시환율 창 안의 나라, 환전, 변화량, 상승하락
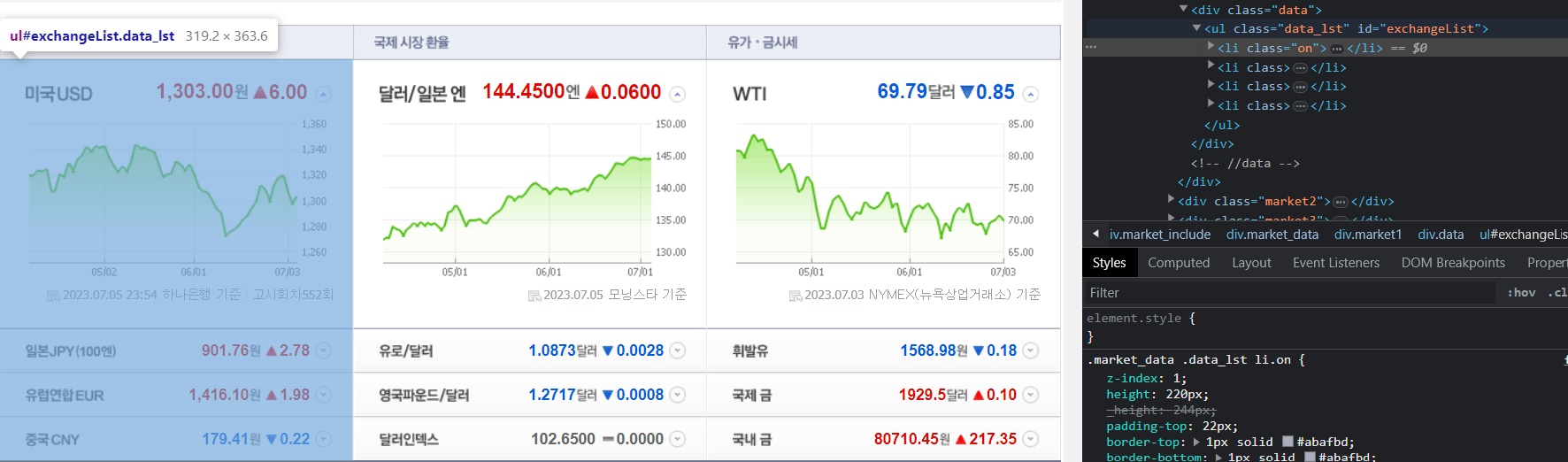
- 개발자 도구로 추적해 보니 id = exchangeList이다
- id가 있으면 편리한 이유는 id는 유일한 값이기 때문이다.
select(), select_one()
- select() : find_all()과 같은 기능
- select("#id, .class") : id명을 찾을 땐 '#', 클래스명을 찾을 땐'.'
- select("#id > li") : id안의 list들
- select_one() : find()와 같은 기능
- 환전고시환율 창의 각 국가별 데이터
- id가 exchangeList인 정보 안의 li태그 가져오기
- 원하는 데이터가 모두 포함된 곳
exchangeList = soup.select("#exchangeList > li") exchangeList
4) 미국의 환전고시환율 정보 가져오기
- 먼저, 원하는 정보들을 하나씩만 가져오는걸 테스트 해본다.
- 하나씩 가져오기를 성공했다면 반복문으로 변경해 원하는 값들을 가져온다.
- select_one()을 이용해 원하는 데이터 가져와 문자로 출력
- updown은 class명이 blind가 여러개 있어서 더 구체적으로 찾아야 한다.
- div.head_info point_dn
중간에 공백문자를 조심해야 한다. 공백문자는 class를 구별하기 위해 공백을 둔것- select_one()에서 사용할때는 head_info클래스와 point_dn클래스라고 보고 "div.head_info.point_dn"으로 사용
- exchangeList의 첫번째 값에 div태그 의 head_info.point_dn클래스의 첫번쨰 말고 다음 .blind 값
title = exchangeList[0].select_one(".h_lst").text exchange = exchangeList[0].select_one(".value").text change = exchangeList[0].select_one(".change").text updown = exchangeList[0].select_one("div.head_info.point_dn> .blind").text title, exchange, change, updown('미국 USD', '1,298.00', ' 8.00', '하락', '/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW')
- link가져오기
baseUrl = "https://finance.naver.com" link = exchangeList[0].select_one("a").get("href") baseUrl + link'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
5) 모든 데이터 가져오기
- 데이터 프레임으로 만들기
- 액셀파일로 저장
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title" : item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
"updown" : item.select_one("div.head_info.point_dn> .blind").text,
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx",encoding="utf-8")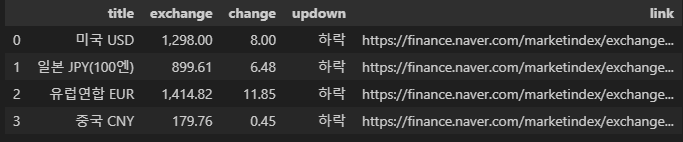
6) python환경에서 만들어보기
- 위에서 한 모든 과정을 하나로 합치면 된다.
- vscode나 jupyter notebook을 이용하는 가장 큰 이유는 인터프리터의 장점을 살리기 위해 실시간으로 한줄한줄 실행 결과를 확인하기 위해서이다.
- naver.py
웹데이터 분석 예제2. 위키백과 문서 정보
- 주요 사항 : url 가져올때 글자를 인코딩 해서 가져오기
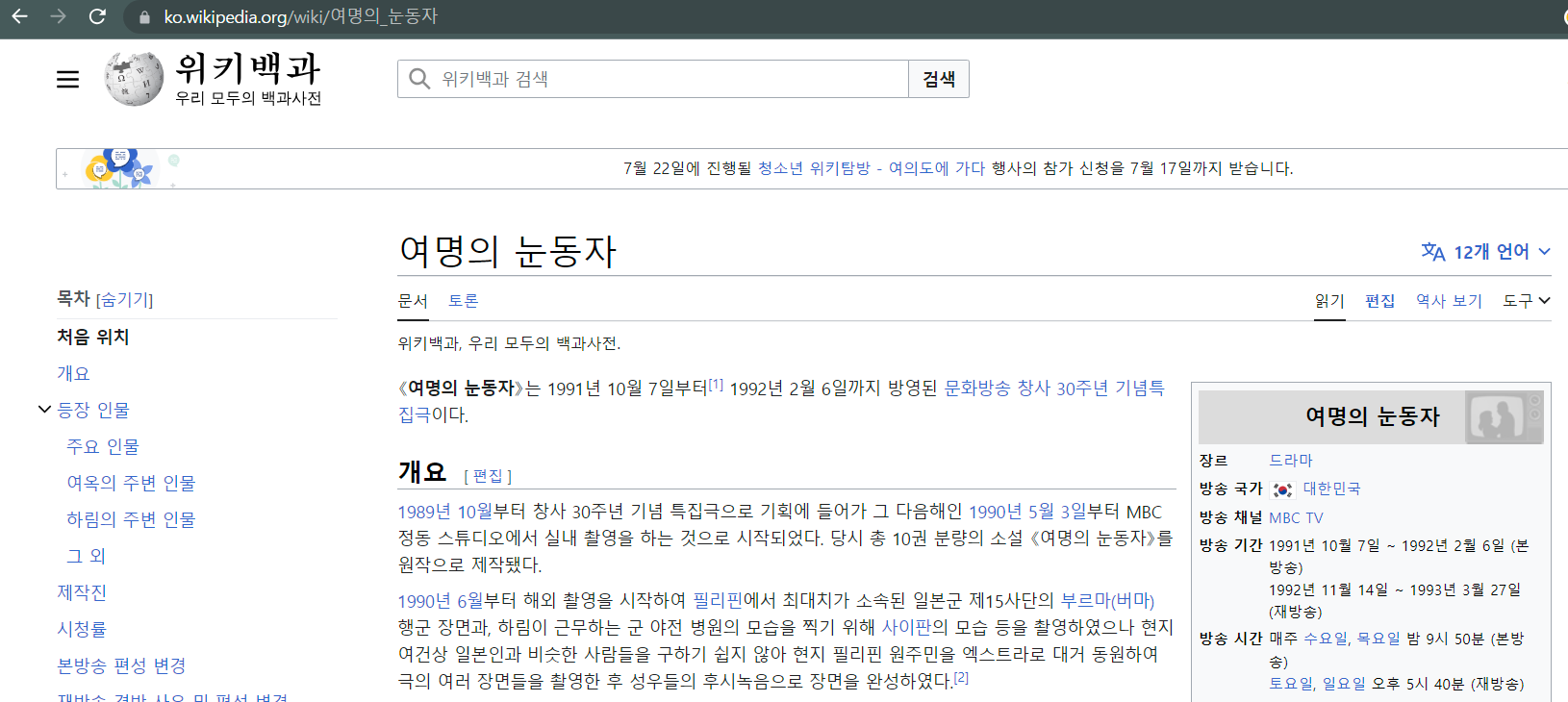
- url을 메모장에 복사해서 붙여넣으면
https://ko.wikipedia.org/wiki/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90 - 페이지에는 https://ko.wikipedia.org/wiki/여명의_눈동자
1) 모듈 import
import urllib from urllib.request import urlopen, Request from bs4 import BeautifulSoup
2) url가져와 html코드 출력
html = "https://ko.wikipedia.org/wiki/{search_words}" req = Request(html.format(search_words = urllib.parse.quote("여명의_눈동자"))) #글자를 URL로 인코딩 response = urlopen(req) soup = BeautifulSoup(response, "html.parser") print(soup.prettify())
- 인코딩 해줄 부분을 {변수} 로 지정해서 html이라는 변수에 저장
html = "https://ko.wikipedia.org/wiki/{search_words}"
- Request함수 사용 html의 format을 정해주는데 searchword는 urllib의 parse의 quote()를 사용해 "여명의눈동자"를 인코딩해서 넣어준다.
req = Request(html.format(search_words = urllib.parse.quote("여명의_눈동자")))urllib.parse.quote(문자) : 문자를 인코딩한 값
- 최종 가져온 데이터


취업공부