
1. BeautifulSoup이용한 웹데이터 분석
1) BeautifulSoup 다운
- conda install -c anaconda beautifulsoup4
or- pip install beautifulsoup4
2) .html 내용 확인하기
- BeautifulSoup 모듈 가져오기
from bs4 import BeautifulSoup
- .html파일 읽기
page = open("../data/03. test_first.html").read()- 분석할 페이지(.html)
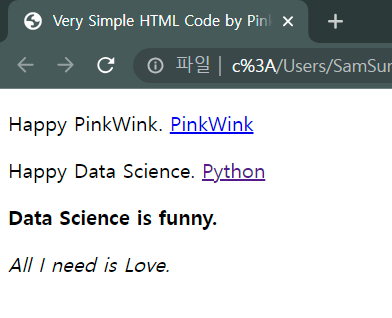
- 가독성 좋게 출력
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())

3) find(), find_all()
- p태그 중 가장 처음 발견한 것 출력
soup.find("p")<p class="inner-text first-item" id="first"> Happy PinkWink. <a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a> </p>
- find("출력할 태그","출력할 클래스")
- class명으로 찾을 때는 class_ 라고 명시해준다.
- 파이썬 예약어와 겹치지 않도록 하기 위함
방법1. soup.find("P", class_="inner-text second-item")- 딕셔너리 형태로 class를 찾을 수 있다.
방법2. soup.find("p", {"class":"inner-text second-item"})<p class="inner-text second-item"> Happy Data Science. <a href="https://www.python.org" id="py-link">Python</a> </p>
- 다중 조건으로 원하는 데이터 가져오기
soup.find("p",{"class" : "inner-text first-item", "id":"first"})
p태그 에서 class명을 inner-text first-item이면서 id가 first인 정보 가져오기
- class명으로 p태그 찾아 text문만 출력
- strip() : 공백을 없애고 출력
soup.find("p", {"class":"outer-text first-item"}).text.strip()'Data Science is funny.'
- find_all() : 여러개 태그를 반환
- 리스트 형식으로 반환
soup.find_all("p")[<p class="inner-text first-item" id="first"> Happy PinkWink. <a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a> </p>, <p class="inner-text second-item"> Happy Data Science. <a href="https://www.python.org" id="py-link">Python</a> </p>, <p class="outer-text first-item" id="second"> <b> Data Science is funny. </b> </p>, <p class="outer-text"> <i> All I need is Love. </i> </p>]
- soup.findall(class="outer-text")[0].text.strip()
class명이 outer-text인것 중 첫번째(0번째 인덱스) 정보에서 문자를 공백 지워서 출력
4) text 보는 방법들
- print(soup.find_all("p")[0].text)
- print(soup.find_all("p")[1].string)
- print(soup.find_all("p")[1].get_text())
5) "a"태그 안 링크주소 가져오기
- a태그 추출
links = soup.find_all("a")[<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>, <a href="https://www.python.org" id="py-link">Python</a>]
- a태그 안의 href(링크) 추출
방법1. links[0].get("href")
방법2. links[0]["href"]'http://www.pinkwink.kr'

취업공부