
시카고 맛집 데이터 분석(BeautifulSoup)
1) 개요
최종목표
- 50개 페이지에서 각 가게의 정보 가져오기
- 가게이름
- 대표메뉴
- 대표 메뉴 가격
- 가게 주소
2) 메인페이지 분석
- 모듈 import
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
- url 가져오기
url_base = "https://www.chicagomag.com/" url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/" url = url_base + url_sub req = Request(url) html = urlopen(req) soup = BeautifulSoup(html, "html.parser") print(soup.prettify())HTTPError: HTTP Error 403: Forbidden
네트워크 에로 코드
- 1xx(정보) : 요청을 받았으며 프로세스를 계속 진행합니다.
- 2xx(성공) : 요청을 성공적으로 받았으며 인식했고 수용하였습니다.
- 3xx(리다이렉션) : 요청 완료를 위해 추가 작업 조치가 필요합니다.
- 4xx(클라이언트 오류) : 요청의 문법이 잘못되었거나 요청을 처리할 수 없습니다.
- 5xx(서버 오류) : 서버가 명백히 유효한 요청에 대한 충족을 실패했습니다.
403에러면 클라이언트 오류이다.
- url 가져오기 서버요청 방법1
모듈 import
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url 설정
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
headers 이용해서 클라이언트 요청
req = Request(url, headers = {"User-Agent":"Chrome"})
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
- url 가져오기 서버요청 방법2. fake_useragent모듈로 사용자 랜덤정보 만들기
- pip install fake-useragent 다운
fake-useragent 모듈 추가import
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
fake_useragent로 만든 램덤정보
ua = UserAgent()
ua.ie
랜덤정보로 서버에 요청
req = Request(url, headers = {"User-Agent":ua.ie})
- 홈페이지 밑에 1~50위 랭킹의 가게들과 정보들이 있다.
- 이 정보들을 가져올 것

- 개발자 도구에서 1 BLT Old Oak Tap Read more 부분의 정보 찾아보자
- div태그에 class명이 sammy이다.

#find_all사용
soup.find_all("div","sammy"),
len(soup.find_all("div","sammy"))#50개인지 확인용
#select 사용
soup.select(".sammy"),
len(soup.select(".sammy"))
- 위에서 가져온 리스트의 첫번째 값 확인
tmp_one = soup.find_all("div","sammy")[0]
랭크, 가게이름, 대표메뉴 정보 확인 가능
3) 필요한 정보를 하나씩 가져오기
- 랭크
tmp_one.find(class_="sammyRank").get_text()'1'
- 가게이름, 대표메뉴
tmp_one.find("div",{"class":"sammyListing"}).text'BLT\nOld Oak Tap\nRead more '
- re
가게 이름, 대표메뉴 코드가 이어져있는 것을 각각 나누고 리스트로 반환
import re
tmp_string = tmp_one.find(class_="sammyListing").text
re.split(("\n|\r\n"), tmp_string)re.split(("\n|\r\n"), tmp_string)
tmp_string에서 \n 또는 \r\n 을 기준으로 나눠서 리스트로 반환해준다.
['BLT', 'Old Oak Tap', 'Read more ']
- 가게 정보 담긴 링크
tmp_one.find("a")["href"]'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'4) 반복문으로 1~50위 정보 가져오기
- 랭크, 가게이름, 대표메뉴, 가게정보링크 하나씩 가져오기 성공
- 이제 1~50위의 정보를 똑같이 가져오면 되므로 반복문 사용
from urllib.parse import urljoin
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
url_base = "https://www.chicagomag.com/"
#필요한 내용을 담을 빈 리스트
#리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div","sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").text)
tmp_string = item.find(class_="sammyListing").text
main_menu.append(re.split(("\n|\r\n"),tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"),tmp_string)[1])
#urljoin() : 중복되지 않게 앞에 url_base가 있다면 뒤만 붙이고 없다면 전체 붙여주는 기능
url_add.append(urljoin(url_base, item.find("a")["href"]))5) 데이터프레임으로 만들기(pandas)
#데이터 프레임으로 만들기
import pandas as pd
data = {
"Rank":rank,
"Menu" : main_menu,
"Cafe" : cafe_name,
"URL" : url_add
}
df = pd.DataFrame(data)
df.tail()
- 컬럼순서 변경
df = pd.DataFrame(data, columns=["Rank","Cafe","Menu","URL"])
df.tail()
- 데이터 저장
df.to_csv("../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8")6) 하위페이지에서 정보 가져오기
- 모듈 import및 저장한 데이터프레임 가져오기
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
#index_col=0 은 첫번째 인덱스행 지우기
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.head()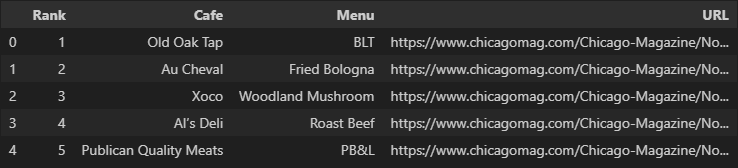
- 1위 음식점 url 가져오기
df["URL"][0]'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
- 1위 음식점 창 안의 가격, 주소 정보 가져오기
개발자도구 활용
#서버에 요청 후 답받기
req = Request(df["URL"][0], headers={"User-Agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "lxml")
soup_tmp.find("p","addy").text'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
- 가져온 정보 나누어 리스트로 반환받기(정규화표현)
Regular Expression
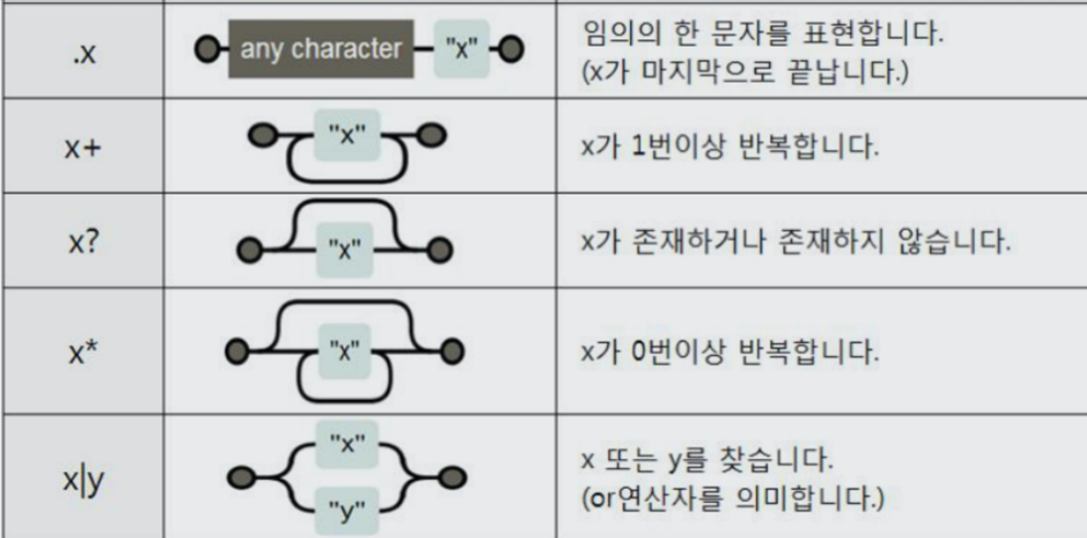
import re #re : regular expression
price_tmp = soup_tmp.find("p","addy").text
re.split(".,", price_tmp)['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']
- 여기서 우리는 첫번째 인덱스 값만 사용하면 된다.
price_tmp = re.split(".,", price_tmp)[0]
price_tmp'\n$10. 2109 W. Chicago Ave'
- 가격과 주소를 나눠야 한다. 이때 re 사용
가격
#price_tmp에서 "($)(숫자) . (숫자가 올수도 안올수도) "
#.group() : 찾은 내용을 문자로 출력
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
tmp'$10.'주소
#tmp의 길이 는 $10. 총 4 에 공백을 더해주면 6번째 부터 주소
#6번째부터 끝까지 슬라이싱한 것이 주소
price_tmp[len(tmp)+2:]'2109 W. Chicago Ave'7) 반복문 이용해 1~50위 가격, 주소 가져오기
#tqdm 모듈은 많은 정보들이 가져오는 것의 진행정도를 볼 수 있게 해준다.
#다른 모듈들은 이미 위에서 호출 되어있다.
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"User-Agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p","addy").text
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)
- 정보 확인하기
len(price), len(address)(50, 50)50개씩 잘 가져와졌다.
8) 데이터 프레임에 컬럼 추가
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank","Cafe","Menu","Price","Address"]]
df.set_index("Rank", inplace = True)
df.head()9) 데이터 저장하기
df.to_csv("../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="utf-8")10) 시카고 맛집 데이터 지도 시각화
- 모듈 import
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
- 저장된 데이터 가져오기
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.tail(7)
- googlemaps 사용하기 위한 세팅, 이전의 발행받은 키 있어야 한다.
gmaps_key = "발행받은 키"
gmaps = googlemaps.Client(key=gmaps_key)
- 위도, 경도 정보 받아오기
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Mulitple location":
#googlemap에 던져 줄 주소
target_name = row["Address"] + "," + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)tqdm의 결과
50it [00:05, 9.52it/s]
- 정보 잘 가져왔는지 확인
len(lat), len(lng)(50, 50)잘가져 왔다.
- 데이터 프레임에 위도,경도 컬럼 추가
df["lat"] = lat
df["lng"] = lng
df.tail()
- 지도에 1~50위 위치 마커 표시
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location = [row["lat"],row["lng"]],
popup = row["Cafe"],
tooltip = row["Menu"],
icon= folium.Icon(
icon = "coffee",
prefix ="fa"
)
).add_to(mapping)
mapping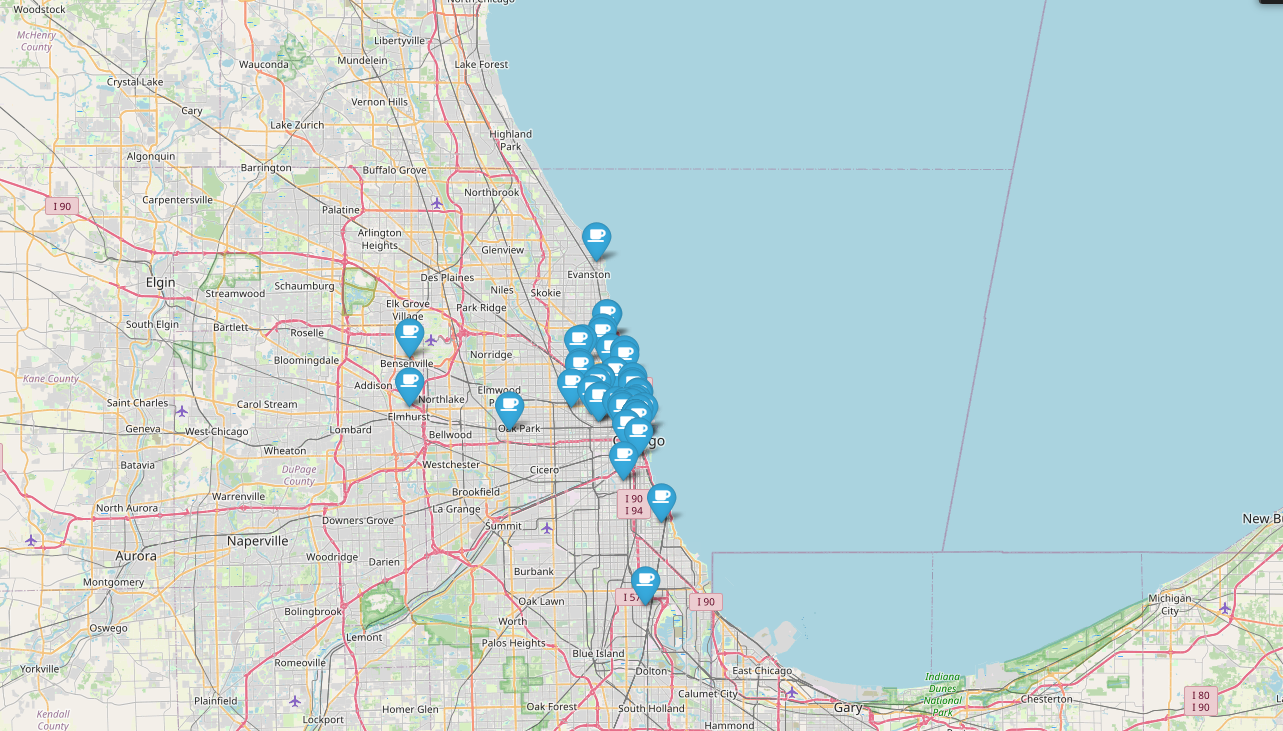

취업공부