
이전에는 서울시 CCTV 현황을 분석 해봤다.
인구수 대비 CCTV갯수를 구해 상관계수구하고 서울시 인구수대비 CCTV갯수 경향성을 구해
경향성에 비해 인구수대비 CCTV가 많고 적은 행적구역을 분석했다.
오늘부터는 서울시 범죄현황에 대해 분석해 보자.
분석 내용은 연습용으로 그저 가설일 뿐이다.
02. Analysis Seoul Crime
01. 데이터 가져오기
- numpy와 pandas 불러오기
import numpy as np
import pandas as pd
- 데이터 가져오기
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands="," , encoding="euc-kr"- 가져온 데이터 확인하기
crime_raw_data.head()
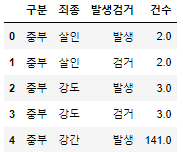
- 가져온 데이터 정보 확인
crime_raw_data.info()
위 출력된 정보창에 이상한 점이 있다.
Range Index가 65534라는건 인덱스가 65534개 라는 것인데 non-null 데이터는 310개이다.
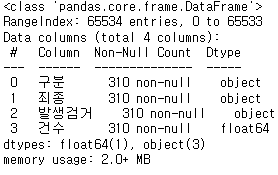
- isnull() : NaN값이 들어있으면 True, 아니면 False
crime_raw_data.isnull()
- NaN값이 들어있는 인덱스 데이터프레임으로 출력(확인용)
crime_raw_data[crime_raw_data["죄종"].isnull()].head()
- 인덱스 310번부터 NaN값이라는 걸 확인
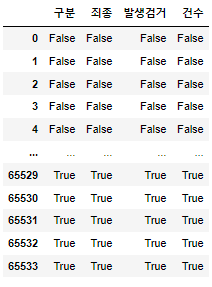

- notnull() : nan값이 아닌 값들만 가져오기
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]

Pandas Pivot Table 사용해 보기
- index, columns, values, aggfunc
잠시 pandas의 pivot table을 알아보자
- 사용할 데이터 가져오기
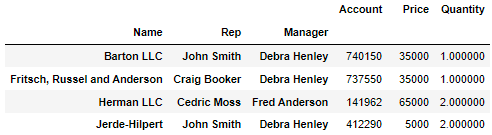
df = pd.read_excel("../data/02. sales-funnel.xlsx")
df.head()

- "Name" 컬럼을 index로 설정
데이터는 df사용 "Name"컬럼을 인덱스로 하고 Account, Price를 뽑기
pd.pivot_table(data=df, index="Name", values=["Account","Price"])
- 멀티 인덱스
df.pivot_tabel(index=["Name","Rep","Manager"])
처음 인덱스로 한 Name은 unipue값이지만 그 이후 인덱스는 중복이 있다.
- sum 연산 적용
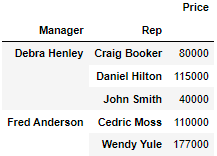
df.pivot_table(index=["Manager","Rep"], values="Price", aggfunc = np.sum)
- 다중연산
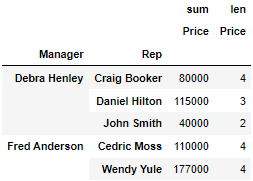
df.pivot_table(index =["Manager","Rep"], values="Price", aggfunc=[np.sum,len])
- columns 설정
- "Product"를 컬럼으로 설정
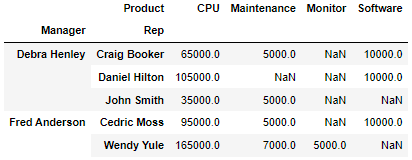
df.pivot_table(index =["Manager","Rep"], values="Price", columns="Product", aggfunc=np.sum)
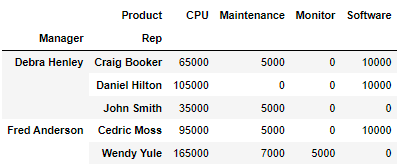
- NaN값을 0으로 채우기 : fill_value
df.pivot_table(index =["Manager","Rep"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)
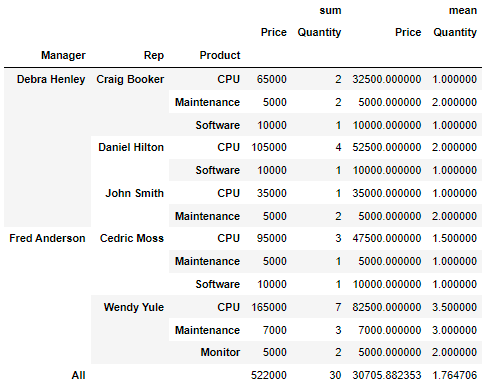
- aggfunc 2개이상 설정, 가장 아래 총합계 행 추가(margins = True)
df.pivot_table(
index=["Manager","Rep","Product"],
values=["Price","Quantity"],
aggfunc=[np.sum,np.mean],
fill_value=0,
margins=True #총계(All) 추가
)
02. 서울시 범죄 현황 데이터 정리
- 현재까지 정리한 데이터
crime_raw_data.head()
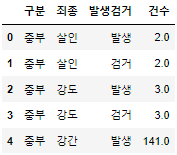
- pivot table이용해서 데이터 정리하기
- data는 crime_raw_data, index는 구분, columns는 [죄종,발생검거], 연산은 합
crime_station = crime_raw_data.pivot_table( crime_raw_data, index="구분", columns=["죄종","발생검거"], aggfunc=[np.sum]) crime_station.head()
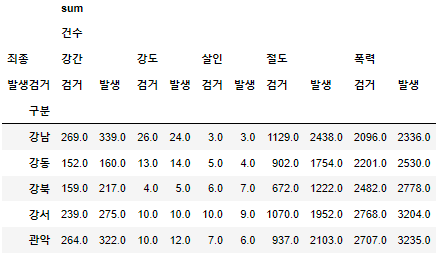
- 다중 컬럼에서 특정 컬럼 제거
- .droplevel([0,1])제거할 컬럼 인덱스 입력. [sum,건수]컬럼 제거
crime_station.columns = crime_station.columns.droplevel([0,1]) crime_station.head()

Google Maps API 설치
지금부터는 지도상에 모든 행정구역 경찰서를 표시해 분석으로 해본다.
지도를 가지고 분석하기 위해서는 googlemaps API를 설치해야 한다.
- conda prompt에서 사용할 가상환경(ds_study)에 접속을 해서
conda install -c conda-forge googlemaps로 googlemaps api설치
- googlemap 홈페이지에서 따로 무료로 구글맵 키를 발행받아야 한다.
키를 발행 받을 때는 보안문제 상 결제할 카드를 연결시켜야 하는데
googlemaps기능 중 일부기능헤만 요금이 부과되고 미니 프로젝트용에서는 과금이 되지 않는다. 과금이 되더라도 1000원에서 5000원 사이라고 한다.
- googlemap api설치 확인하기
import googlemaps gmaps_key="발급받은 구글맵 키" gmaps = googlemaps.Client(key=gmaps_key) gmaps.geocode("서울영등포경찰서",language="ko")
이렇게 실행이 된다면 googlemap api설치에 성공한 것이다.
"서울영등포경찰서" 정보가 나온다. 우리가 이용할 것은 위도,경도

Pandas에 잘 맞춰진 반복문 명령어: iterrows()
- pandas 데이터 프레임은 대부분 2차원
- for문을 사용하기엔 가독성이 너무 떨어진다.
- iterrows()옵션을 사용하면 편하다.
- 받을 때 인덱스와 내용으로 나누어 받는 것만 주의
03. Google Maps를 이용한 서울시 범죄 데이터 정리
- googlemaps 모듈 가져오기
mport googlemaps gmaps_key = "발급받은 구글맵 키" gmaps = googlemaps.Client(key=gmaps_key)
- 예를 들어, 서울영등포경찰서 정보 가져오기
gmaps.geocode("서울영등포경찰서", language="ko")

- 위도,경도 정보와 경찰서 행정구역 가져오기

- 현재 데이터 확인
crime_station.head()

- "구별", "lat", "lng" 컬럼 추가
crime_station["구별"] = np.nan crime_station["lat"] = np.nan crime_station["lng"] = np.nan crime_station.head()

- iterrows()사용해서 구별 경찰서 위도 경도 데이터 추가
- count는 그냥 수에 맞게 잘 들어가는지 확인용으로
count = 1 for idx, rows in crime_station.iterrows(): station_name = "서울" + str(idx) +"경찰서" tmp = gmaps.geocode(station_name, language="ko") tmp_gu= tmp[0].get("formatted_address") lat = tmp[0].get("geometry")["location"]["lat"] lng = tmp[0].get("geometry")["location"]["lng"] crime_station.loc[idx, "lat"] = lat crime_station.loc[idx, "lng"] = lng crime_station.loc[idx, "구별"] = tmp_gu.split()[2] print(count) count += 1
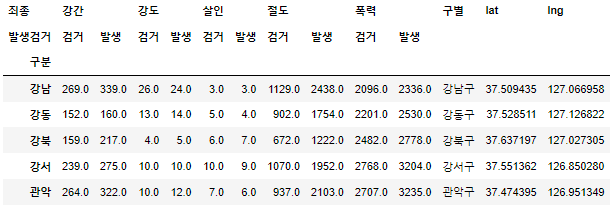
- columns들을 보기편하게 정리해보자
tmp = [ crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n] for n in range(0, len(crime_station.columns.get_level_values(0))) ] crime_station.columns = tmp crime_station.head()

- 중간중간 저장
crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep =",", encoding="utf-8")
04. 구 별 데이터로 정리
- 저장한 최종 데이터 불러오기
crime_anal_station = pd.read_csv("../data/02. crime_in_seoul_raw.csv", index_col=0, encoding="utf-8") crime_anal_station.head()
- 인덱스를 "구별" 로 하고 lat, lng컬럼 삭제
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc=np.sum) del crime_anal_gu["lat"] crime_anal_gu.drop("lng", axis=1, inplace=True) crime_anal_gu.head()
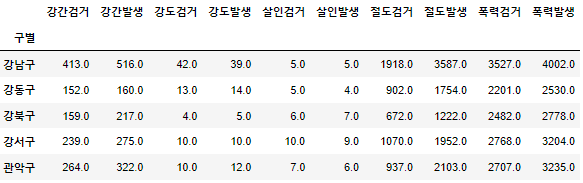
- 검거율 = 검거 / 발생
- 5대범죄 각각 검거율 컬럼 추가
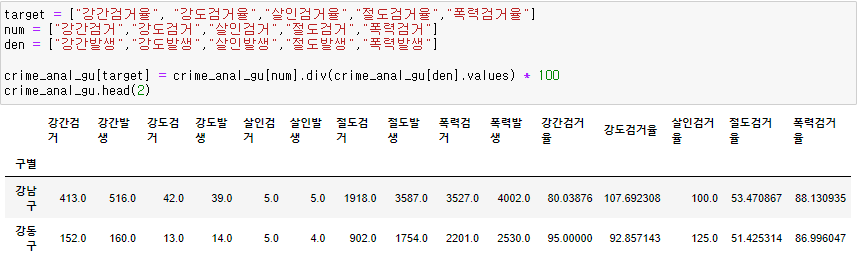
- 이제 검거 칼럼들은 이용하지 않으니 보기 편하게 지우자

- 검거율이 100이 넘는 이유는 현제 우리가 사용하는 데이터는 1년에 발생한 범죄들이고 그 이전에 발생한 범죄들을 올해 검거한 것도 포함해 100이 넘는 것이다.
- 공부 목적으로 분석하는 것이라 아직 100이 넘는 검거율은 100으로 처리
# 100보다 큰 숫자 찾아서 바꾸기 crime_anal_gu[crime_anal_gu[target] > 100] = 100 crime_anal_gu.head()

- 컬럼 이름을 더 보기 편리하게 변경
crime_anal_gu.rename(columns = {"강간발생":"강간","강도발생":"강도", "살인발생":"살인","절도발생":"절도","폭력발생":"폭력"}, inplace=True) crime_anal_gu.head()
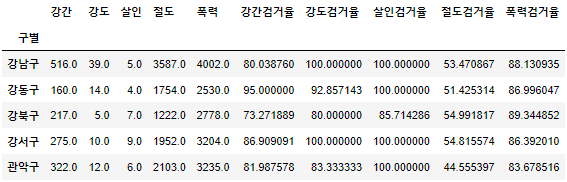
05. 범죄 데이터 정렬을 위한 데이터 정리
- 5대 범죄의 발생 건수 차이가 크다
- 살인은 1자리수이고 절도는 4자리 수
- 후에 시각화에서 어려움이 발생 할수 있다.
- 정규화를 해줘야 한다.
- 정규화는 0~1 사이값으로 최대치를 나눠주면 된다.
- 새로운 프레임데이터를 만들어 5대범죄 발생을 정규화 시키자
col = ["강간","강도","살인","절도","폭력"] crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max() crime_anal_norm.head()

- 검거율 추가
col2 = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"] crime_anal_norm[col2] = crime_anal_gu[col2] crime_anal_norm.head()
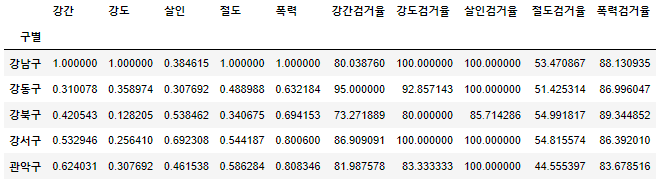
- 이전 프로젝트에서 CCTV갯수와 인구수 추가
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col="구별", encoding="utf-8") crime_anal_norm[["인구수","CCTV"]] = result_CCTV[["인구수","소계"]] crime_anal_norm.head()
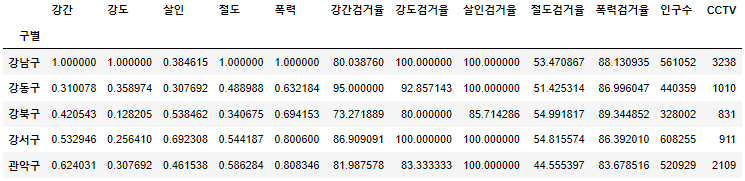
- 정규화된 범죄 발생 건수 전체의 평균을 구해 범죄 컬럼 추가
col = ["강간","강도","살인","절도","폭력"] crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col],axis=1) crime_anal_norm.head()
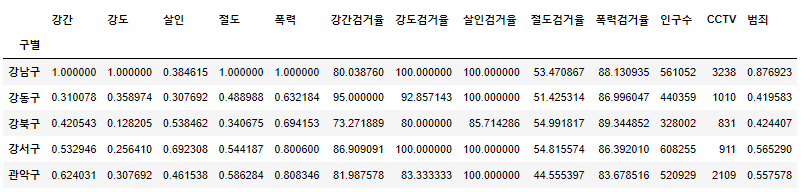
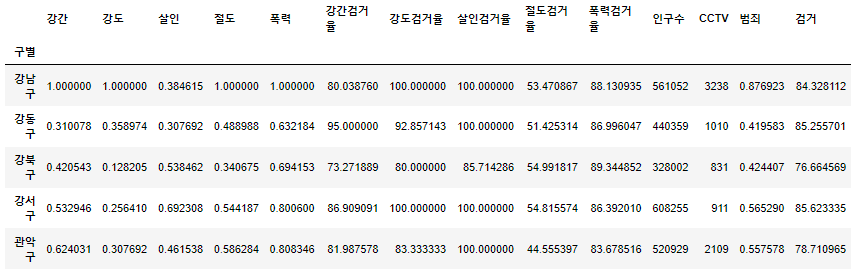
- 검거율 평균도 검거 컬럼으로 추가
col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"] crime_anal_norm["검거"] = np.mean(crime_anal_gu[col],axis=1) # numpy에서는 axis =1 행, axis=0 열 crime_anal_norm.head()

취업공부